Анализируя двумерную матрицу частот, исследователь работает в понятиях «больше» – «меньше», рассматривая нормированное отклонение признака в градациях «подлежащего» от так же нормированного его значения в «сказуемом» по выборке в целом. Сила отклонения рассматривается, анализируется, оценивается, гипотеза выдвигается или отвергается. Это написано во многих учебных пособиях[37].
Безумна затея – оценивать значимость отклонений по каждой клетке в десятках тысяч таблиц, проверяя то, что важно называется «гипотезой», а по-нашему – просто очередной логический вывод типа «больше» – «меньше». Все это может сделать компьютер, рассмотрев, сравнив, оценив, проставив знак с математической достоверностью. Если отклонение незначимо, программа проставляет в этой клетке знак «±», если частота в таблице непредставительна, программа ставит «·». Так, в табл. 1.7 мы сразу видим дифференциацию возрастных групп по включенности в политико-идеологический и информационный процессы и тут же полную их индифферентность в отклонении их оценок аккумуляции информации органами власти от средних по массиву. Дифференциация оценок в классовом и образовательном срезе и там и там очевидна. Мы сразу видим и лес и деревья.
Коэффициенты сопряженности, основанные на критерии «хи-квадрат» имеют в анализе другие функции. Они показывают общую связь признаков, когда мы меряем сопряженность разных подсистем. Но не детали. Это хорошо видно на измерении взаимной связи связи в «активности» и «информированности»[38].
Мы видим, что в первой из таблиц 3x3, где приводятся данные о распределении уровня знаний о «косыгинской» реформе у всего населения города, наибольший коэффициент взаимной сопряженности («хи-квадрат» составляет здесь 350,998). Однако, как только мы исключаем из анализа треть населения, не использующую никаких источников информации об экономической жизни города и не знающую ни одного элемента информации об экономической реформе на предприятиях, мы получаем в несколько раз меньшее значение «хи-квадрата»: 88,813, а отсюда и соответствующие коэффициенты сопряженности. В то же время перепады в долях процентов в 3 – 4 раза (!) от среднего значимы. Они говорят о прямой взаимозависимости знаний о происходящих экономических событиях и производственной и информационной активности. Здесь анализ, основанный на «хи-квадрате», может помочь только в интерпретации показателей энтропии. Она резко возрастает из-за расширения масштабов общности и концентрации массы населения или в области отчуждения от происходящего процесса, или в активной зоне происходящего. На предприятиях Ташкента энтропия по заполненным клеткам 0,738. Две клетки не выпадают. Нельзя быть высокоактивным в определенной области и мало знать об этой области. И наоборот: быть малоактивным и много знать[39]. Перед нами информационно-деятельностный синдром, точно такой же, кстати, как и в случае информационного приема (табл. 1.12). Ведь осознание объективных информационных потребностей – та же информированность на уровне рефлексии собственной деятельности. Но и там коэффициенты на основе «хи-квадрат» «зашкаливаются», и в плотной, и в разреженной аудитории и показывают одно и в плавно принимаемом, и в судорожно выхватываемом потоках сведений (табл. 1.13).
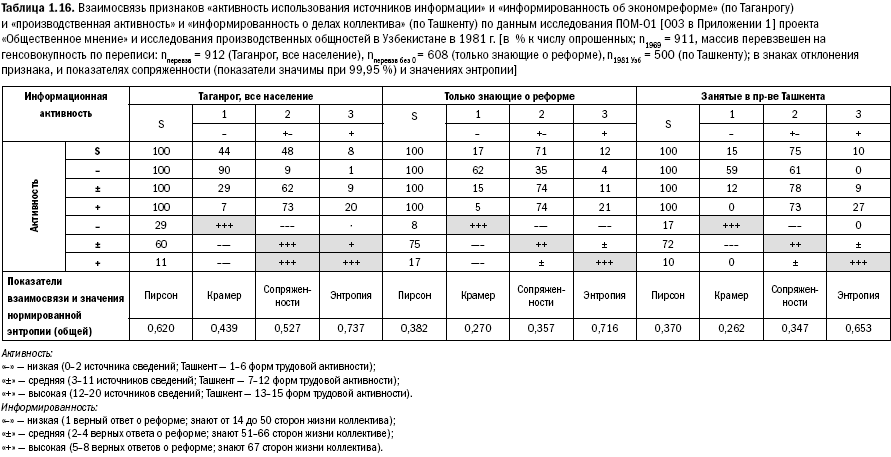
Между тем все три коэффициента и показатели энтропии работают вместе с оценками силы отклонений и дают достаточно надежную для аргументации картину[40]. Кроме того, здесь возникает фундаментальное предположение, косвенно подтверждаемое падением и возрастанием значений энтропии среди незанятого в народном хозяйстве населения города и среди двух типов производственных общностей (переходящих на новую систему работы и работающих по старой). Дело в том, что энтропия – линейная функция и ее значения, показывая своего рода меру рассеяния данного континуума предметностей по массе населения, позволяют предполагать, что метрика социального пространства ограничена функциональным горизонтом общностей. И чем меньше общность, тем меньше значение энтропии (при прочих равных условиях пронизывания систем деятельности формами силовых линий социальных институтов). Это предположение нуждается в соответствующей экспериментальной проверке.
Наконец, надо сказать об аппроксимации кривых распределений (кумулят, «гауссиан» и «огив»-кривых «Парето»). Первые полтора десятка из них были получены автором в начале 80-х гг. Тогда они были встречены коллегами «в штыки», но теперь многие говорят о нормальных распределениях в социологических замерах. Программная и электронная базы, однако, не были готовы в то время еще к такому анализу[41]. Однако появление новой серии машин «Pentium», последних версий программного пакета «SPSS», двух версий «TableCurve 2D» и «TableCurve 3D», позволяющих апробированно заниматься аппроксимацией кривых, зависимостей и построением форм пространственно-временной конфигурации общества в трехмерной графике, позволило, наконец, решить поставленные еще 30 лет назад задачи[42].
Информационная база исследования
Кое-что сказано уже во Введении, и это избавляет от повторений. В общем и целом, в этой книге интерпретируется информация около 200 исследований, из которых отобрано 135 массивов, представленных в Приложении 1. Здесь 19 Всесоюзных исследований (одно из них Всероссийское по селу) и 116 региональных. Их характеристики следуют из описания в Приложении. Отметим две особенности, которые в описании не указаны, а упомянуты косвенно.
1. Стихийный характер производства социологической информации в нашем обществе приводил и приводит к тому, что в каждом отдельно взятом исследовании рассматривались (зачастую несмотря на системный «замах») узко определенные области социального и их взаимосвязи. В одном исследовании, например, это владение товарами длительного пользования, спрос на них, сбережения населения и ориентация на формы досуга, – широкий спектр, но нет информационной и политической подсистем. В другом они как раз и представлены, а в вопросе о количестве имеющихся детей[43] фиксируется важный показатель процесса рождаемости, но показателей благосостояния нет. В некоторый общесоюзных исследованиях можно поэтому рассматривать взаимосвязи только отдельных подсистем, сопоставляя их на временном ряду и выясняя динамику взаимосвязи их форм. В минимальной степени эта «ограниченность» присуща исследованиям «Образа жизни», но и там показатели подсистемы потока информации от населения во власть и показатели межличностного общения несколько сужены. Показатели информированности отсутствуют вообще, а попытка построить их косвенным образом не удалась. Зато здесь хорошо разработаны показатели обыденных жизненных представлений населения и проведено блестящее «лонгитюдное» исследование. Но так или иначе эти ограничения ставили проблему, которую надо было снять. С этой целью автором и было проведено в 1990 – 91 гг. последнее Всесоюзное исследование, в котором удалось зафиксировать практически все стороны процесса «деятельность – сознание – деятельность», сняв у личности характеристики развертки ее активности как на уровне макроструктуры общественного организма, так и на других: информированности, осознанных отношений, психолингвистическом (семиотические группы), психическом (аналог теста Люшера), установочно-этническом[44]. Было получено больше 10 000 документов и среднее число ответов на одно интервью в 150 вопросов составило около 750. Здесь был зафиксирован и процесс приема информации в естественных условиях, и уровень семиотической подготовки личности в приеме информации (способности понимать смысл текста на тот или иной лад), и дальнейшее использование элементов текста в практике, и многое другое, необходимое для работы[45]. Вычищенный от недостоверной информации массив составил 9672 документа интервью (с 3608 переменными в версии SPSS), которые дали поле частот в 7,5 млн. (вместе с перевалившими за 60 тыс. контактов с сообщениями «АиФ», «Правды», «Комсомольской правды» и «Советской России»). Общество было взято в самый критический момент точки перехода из одного состояния в другое, а методики обеспечивали стыковку этого массива информации со всеми предыдущими исследованиями по всем существенным параметрам. В дальнейшем можно было проводить только локальные точечные замеры.