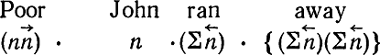6.3.5. УСЛОВНАЯ ЗАПИСЬ
Здесь мы введем для экономии места условную запись, которая не окажет воздействия на формальные качества системы. Мы будем записывать «дроби» как упорядоченную пару заключенных в скобки символов с числителем на первом месте и знаменателем на втором и стрелкой над знаменателем, указывающей направление. По этому условию run будет характеризоваться как
, poor — как
, а «наречие» типа away 'прочь'— как
.
6.3.6. «КАТЕГОРИАЛЬНЫЙ» АНАЛИЗ СТРУКТУРЫ СОСТАВЛЯЮЩИХ
Теперь мы можем проиллюстрировать действие этой простой двунаправленной категориальной грамматики относительно предложения Блумфилда Poor John ran away. Категориальная классификация всех лексических элементов была приведена выше. Мы запишем их под словами в предложении:
Теперь о «сокращениях». Ясно, что на первой стадии существует три возможности: (1а) «сокращение» poor и John; (1b) John и ran и (lc) ran и away. Если выбрать (lb), то в результате получится:
Это означает, что John ran признается предложением, a poor и away остаются вне предложения и вне описания. Если выбрать (1а), то на следующей стадии мы получим:
Теперь мы имеем две возможности; и ясно, что для того, чтобы проанализировать предложения без остатка, мы должны теперь Сократить ran и away, получив
и, наконец,
(3) Σ.
Или же мы могли сначала объединить ran и away (1с), а затем — poor и John; другими словами, мы могли сокращать те же самые элементы, но в другом порядке.
6.3.7. СОПОСТАВЛЕНИЕ АНАЛИЗА ПО НЕПОСРЕДСТВЕННЫМ СОСТАВЛЯЮЩИМ С КАТЕГОРИАЛЬНЫМ АНАЛИЗОМ
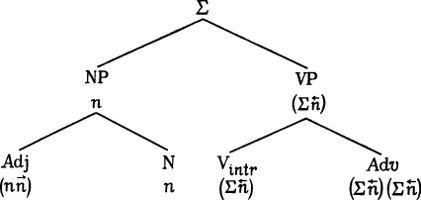
Операция «сокращения» отражает понятие скобочной записи, которое мы рассматривали в этом разделе; ясно, что только что приведенный анализ Poor John ran away соответствует тому, что говорил о структуре этого предложения Блумфилд: что оно состоит из двух непосредственных составляющих — poor John и ran away — и что каждая из них состоит из двух непосредственных составляющих — poor и John, с одной стороны, и ran и away — с другой. Сравним теперь категориальный анализ с анализом в терминах следующих правил «подстановки» (ср. § 6.2.2):
(1) Σ → NP + VP
(2) VP → Vintr + Adv
(3) NP → A + N.
Рис. 12.
Из сложного дерева, приведенного на рис. 12, ясно, что эти две грамматики не только слабо эквивалентны (в том смысле, что они порождают одно и то же множество предложений — тот факт, что мы излагали категориальную систему в форме грамматики «распознавания», а систему «подстановок» в форме грамматики «образования», не релевантен для данного вопроса; ср. §4.3.1), они также эквивалентны в отношении скобочной записи, которую они определяют для предложений типа Poor John ran away. Но они эквивалентны далеко не во всех отношениях. Прежде всего можно отметить, что система «подстановок», кроме четырех терминальных символов, обозначающих лексические классы (N, Vintr, A и Adv), имеет два вспомогательных символа (NP и VP); поэтому, если категориальный анализ утверждает, что poor John представляет собой составляющую той же категории, что и John, a ran away — составляющую той же категории, что и ran, то при анализе при помощи «подстановок» такое утверждение не делается. Однако мы легко можем сделать обе эти системы эквивалентными в отношении данного признака, заменив NP на N и VP на Vintr в правилах «подстановки» (мы не будем вдаваться в дальнейшие импликации данной поправки). Главное различие между этими двумя системами заключается в том, что категориальная грамматика, в отличие от грамматики «подстановок», считает одну из составляющих в каждой конструкции зависящей от другой; условная запись категориальной грамматики показывает, которая из составляющих является зависимой (та, у которой более сложная характеристика), и это имеет принципиальное значение для операции «сокращения». В системе «подстановок» понятие зависимости получает лишь частичное и косвенное отражение: из правила вида N → A + N можно заключить, что А зависит от N, но правило вида Σ → N + Vintr (или Σ → NP + VP) не дает оснований для выводов относительно какой-либо связи или зависимости между двумя составляющими. Это не означает, что категориальная система непременно должна быть лучше, чем система «подстановок», а значит только то, что эти две системы не являются сильно эквивалентными. Могут возникнуть соображения, заставляющие предпочесть один анализ другому; в этом случае мы будем считать, что грамматика, приписывающая предложению предпочтительный анализ, обладает большей силой адекватности по сравнению с другой грамматикой. Это составляет отдельный вопрос, которого мы бегло коснемся ниже (см. § 6.5.7).
6.4. ЭКЗОЦЕНТРИЧЕСКИЕ И ЭНДОЦЕНТРИЧЕСКИЕ КОНСТРУКЦИИ *
6.4.1. ДИСТРИБУЦИОННАЯ ИНТЕРПРЕТАЦИЯ
Мы можем теперь рассмотреть несколько более подробно дист-рибуционную основу анализа по непосредственным составляющим. Конструкции могут подразделяться, в соответствии с их дистрибуцией и дистрибуцией их составляющих, на так называемые (в терминах, предложенных Блумфилдом) эндоцентрические и экзоцентрические конструкции. Эндоцентрической принято называть такую конструкцию, дистрибуция которой совпадает с дистрибуцией одной или более из ее составляющих; любая конструкция, не являющаяся эндоцентрической, называется экзоцентрической. (Другими словами, экзоцентричность определяется негативно относительно предшествующего определения эндоцентричности, и любая конструкция попадает в тот или другой класс.) Например, знаменитое теперь словосочетание poor John является эндоцентрич-ным, поскольку оно имеет ту же дистрибуцию, что и его составляющая John; любому английскому предложению, в котором встретится John, обычно можно сопоставить другое предложение, в котором в той же позиции находится poor John; и, поскольку John представляет собой существительное, poor John описывается как именная группа. С другой стороны, in Vancouver 'в Ванкувере' является экзоцентрической конструкцией, поскольку ее дистрибуция отличается как от дистрибуции предлога in, так и от дистрибуции существительного Vancouver. Словосочетание in Vancouver имеет почти такую же дистрибуцию в английских предложениях, как there 'там' и другие наречия (места); поэтому оно классифицируется как адвербиальная группа (места). Эти примеры показывают, что, хотя традиционная грамматика не проводила как таковое разграничение между эндоцентрическими и экзоцентрическими конструкциями, традиционному представлению о «функции» (согласно которому считается, что poor John имеет «функцию» существительного, a in Vancouver — наречия) может быть дано естественное истолкование с точки зрения дистрибуции соответствующих элементов.
Часто говорят, что ни одна конструкция не имеет в точности такой же дистрибуции, как какая-либо из ее составляющих; что в результате подстановки конструкции на место одной из составляющих мы получим некоторое количество неприемлемых высказываний. Это, без сомнения, справедливо. Но, как мы видели в предыдущей главе, под дистрибуцией элемента мы подразумеваем не совокупность приемлемых высказываний, в которых встречается данный элемент, а множество тех высказываний, приемлемость которых устанавливается и объясняется грамматическим описанием языка, причем степень глубины объяснения, доступная данному грамматическому описанию, определяется тем, что мы назвали «законом снижения рентабельности» (см. § 4.2.11). В этом смысле, следовательно, два элемента могут обладать либо не обладать тождественной дистрибуцией, а конструкции могут быть эндоцент-ричными или экзоцентричными. В любой грамматике английского языка будет выделен ряд различных (и частично пересекающихся) подклассов существительных, глаголов, прилагательных и т. д. Например, будет проведено разграничение между «исчисляемыми» и «неисчисляемыми» (или «вещественными») существительными (чтобы объяснить приемлемость I like wine 'Я люблю вино' и т. п. и неприемлемость — если только не иметь в виду ситуацию людоедства — *I like boy [43] и т. п.); между «человеческими» и «нечеловеческими» существительными (чтобы объяснить, среди прочего, дистрибуцию who : which; ср. The boy who... 'Мальчик, который...' и The book which... 'Книга, которая...'); между существительными в единственном и во множественном числе (чтобы описать «согласование»; ср. The boy is... 'Мальчик есть...' и The boys are... 'Мальчики суть...'); между существительными мужского, женского и среднего рода (чтобы описать «референцию» местоимений he 'он', she 'она', it 'оно') и т. д. Когда мы говорим, что два существительных имеют в точности одинаковую дистрибуцию, мы имеем в виду, что они попадают в один класс на самом «низком» уровне дистрибуционной субклассификации, достигаемом грамматикой. Но мы можем говорить об одной и той же или различной дистрибуции двух элементов в зависимости от соответствующей, специально указанной «глубины». Так, все имена (и все именные группы и именные несамостоятельные предложения) имеют одинаковую дистрибуцию на относительно высоком уровне классификации, на котором термин «имя» используется без дальнейших уточнений. На более низком уровне два имени могут иметь различную дистрибуцию, если одно, скажем, «одушевленное», а другое «неодушевленное» и т. п. Понятия эндоцентричности и экзоцентричности, таким образом, следует употреблять по отношению к некоторой определенной «глубине» субклассификации.