3.3.5. НЕЙТРАЛИЗАЦИЯ В ФОНОЛОГИИ
Более общим явлением, нежели свободное варьирование фонем при определенных фонологических условиях, является так называемая нейтрализация различия между ними в некоторых позициях. Это можно пояснить на одном общеизвестном примере. Во многих языках, включая немецкий, русский, турецкий, существует фонемное различие между звонкими и глухими согласными в большинстве позиций в слове, однако в конце слова звонкие согласные не встречаются. Таким образом, оба немецких слова — Rad ('колесо', 'велосипед') и Rat ('совет') — произносятся одинаково, а именно как [ra:t]. (Многие носители немецкого языка различают эти два слова — Rad и Rat — на основе долготы или качества гласного. Но это не затрагивает сути дела.) Принятая орфография учитывает тот факт, что в тех формах этих слов, в которых данные согласные находятся не в конечном положении, звонкий и глухой члены пары последовательно различаются: ср. zum Rade [ra:də] verdammen ('приговорить к колесованию') и meinem Rate [ra:tə] folgen ('следовать моему совету'). Говорят, что различие между звонкими и глухими согласными, то есть между/d/ и /t/, /b/ и /р/ и т. д., «нейтрализуется» в конечном положении; и это представляет собой фонологическое утверждение о данном языке.
Однако существует несколько различных способов интерпретации данного вида нейтрализации. Некоторые лингвисты сказали бы, что как в конце слова Rad, так и в конце слова Rat встречается фонема /t/ и объясняли бы изменение /d/ в /t/, проявляющееся в отношении между Rade и Rad, в разделе лингвистического описания, промежуточном между грамматикой и фонологией (то есть в разделе, которому присвоено название морфофонемики: этот подход принимается во многих американских учебниках и публикациях по анализу языков). Лингвисты другой школы сказали бы, что тот факт, что определенные фонологические оппозиции в некотором данном языке «нейтрализуемы», тогда как другие — нет, составляет важную и фундаментальную черту фонологии этого языка, обосновывающую выделение двух различных типов фонологических единиц. Лингвисты, принимающие этот подход (главным образом, так называемая «Пражская школа»), выделяют, кроме фонем, которые сохраняют свою различительную функцию во всех позициях, еще и так называемые архифонемы, ограниченные позициями нейтрализации. Обычным и удобным способом обозначения архифонем служит использование прописных букв: таким образом, /Т/ — это архифонема в немецком языке, в отличие от /d/ и /t/, которые представляют собой фонемы и не встречаются в конечном положении. Слово типа Tod ('смерть') было бы затранскрибировано как /toD/[30], другими словами, способом, благодаря которому становится ясно, что единица, встречающаяся на конце, — другого порядка, нежели единица, встречающаяся в начале. С фонетической точки зрения звуки речи в начале и в конце одинаковы (при не слишком узкой транскрипции). Одинаковы ли они с фонологической точки зрения — это вопрос, который может быть решен лишь в рамках той или иной фонологической теории. Лингвист, принимающий принцип «однажды фонема — всегда фонема», скажет, что они одинаковы. Лингвист, разграничивающий фонемы и архифонемы, скажет, что нет. Несколько ниже в настоящей главе мы остановимся подробнее на некоторых теоретических различиях, лежащих в основе этих разных ответов.
Здесь было сказано достаточно для того, чтобы пробудить в читателе подозрение (которое будет расти по мере углубления в данный предмет), что «факты» относительно структуры отдельного языка, обнаруживаемые лингвистом, не являются целиком независимыми от теорий, которые он заранее принимает.
3.3.6. СИНТАГМАТИЧЕСКИЕ ОТНОШЕНИЯ МЕЖДУ ФОНЕМАМИ
До сих пор, рассматривая фонологическую теорию, мы имели дело только с парадигматическими измерениями речи (см. § 2.3.3). Мы говорили, что /р/, /b/, /1/ и т. д. представляют собой различные фонемы в английском языке потому, что они находятся в парадигматическом контрасте в разных контекстах. (В предыдущей главе мы излагали понятие «контраста» с более общей точки зрения; см. § 2.2.9.) Мы можем сказать, что, например, в слове pet 'ласкать' в начальной позиции встречается фонема /р/, где она находится в контрасте с /b/,/1/ и т. д. (ср. bet 'пари', let 'позволять' и т. п.), на втором месте представлена фонема /е/, находящаяся в контрасте с /i/, /о/ и т. д. (ср. pit 'яма', pot 'горшок' и т. п.), и что в конечной позиции встречается фонема /t/, которая контрастирует с /k/,/n/ и т. д. (ср. реек 'клевать', pen 'перо' и т. п.). Поэтому слово pet может быть представлено в виде последовательности трех фонем: /p/+/e/+/t/, сокращенно — /pet/ (причины того, почему фонемы считают линейно упорядоченными, рассматривались выше; см. § 2.3.6).
Предположим, для простоты, что три, и только три, фонемы находятся в отношении контраста в контексте /-et/, а именно /р/, /b/ и /1/; что три, и только три, фонемы находятся в отношении контраста в контексте /р-t/, а именно /е/, /i/ и /о/; что три, и только три, находятся в отношении контраста в контексте /ре-/: /t/, /k/ и /n/. На основе этого предположения мы можем построить следующую двумерную матрицу, в которой вертикальные колонки представляют собой классы фонем, находящихся в констрасте в каждой из трех позиций:
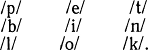
Горизонтальным измерением представлена возможность синтагматического сочетания (см. § 2.3.3). Матрица может быть истолкована следующим образом: в любую позицию парадигматического контраста в слове /pet/, находящемся в верхней строке матрицы, можно подставить другую фонему из второй или третьей строки, и в результате получится новое английское слово. Матрица, таким образом, суммирует факты, описанные выше. Она сообщает нам, что следующие семь синтагматических сочетаний образуют английские слова: /pet/, /bet/, /let/, /pit/, /pot/, /pen/ и /pek/.
При такой интерпретации матрицы мы помещаем слово pet в «фокус» и оставляем постоянными две из составляющих его фонем в качестве контекста при парадигматической подстановке. Но можно истолковать матрицу и таким образом, что ни одно слово не будет помещаться в «фокус» в данном смысле. Можно описать и многие другие английские слова, если допустить, что любая фонема из первой колонки сочетается синтагматически с любой фонемой из второй и третьей колонок: ср. bin 'ларь', bit 'кусочек', lick 'лизать', lock 'замок' и т. д. (Мы приводим слова в их стандартной орфографической записи.) В результате, однако, будут допущены также и некоторые сочетания, не образующие английских слов, например: /bik/ или /lon/. Здесь мы должны решить, запрещаются ли подобные сочетания систематически, в силу каких-то общих ограничений сочетаемости английских фонем друг с другом. Если нельзя установить подобных ограничений, мы будем считать, что формы типа /bik/ и /lon/ являются фонологически приемлемыми английскими «словами», которые, так сказать, не «актуализуются» языком и не облекаются значением и грамматической функцией. «Неактуализация» в этом понимании термина увеличивает избыточность высказываний (ср. § 2.4.5).
Итак, определение фонологической структуры языка можно представлять себе следующим образом. Всякий язык обладает словарем «реальных» слов, каждое из которых сначала можно рассматривать как фонологически «регулярное» (удовлетворяющее определенным системным принципам сочетаемости, действующим на составляющих их фонемах). Задачей лингвиста является объяснение их фонологической «регулярности». (Для простоты изложения мы умышленно ограничили данным этапом рассмотрение фонологической структуры, предположив, что фонология занимается только образованием слов независимо от их встречаемости в предложениях.) Если дано множество «реальных» слов, лингвист будет описывать их фонологическую структуру на основе правил, устанавливающих допустимые сочетания классов фонем так, чтобы каждый член класса находился в отношении контраста с каждым другим. Будем, например, считать, что каждая колонка в приведенной выше матрице составляет класс Х = {/р/, /b/, /1/}, Y = {/e/, /i/, /о/}, Z = {/t/, /n/, /k/}. Мы можем теперь сформулировать правило, согласно которому любой член X может сочетаться с любым членом Y и Z (в данном порядке). Это правило, как мы только что видели, не только признает фонологическую регулярность таких «реальных» слов, как pet, bet, lit, lick, peck и т. д., но также определит как регулярные ряд не встречающихся «слов».