3.2.7. АРТИКУЛЯТОРНЫЕ ПЕРЕМЕННЫЕ: «ДОЛГИЕ» И «КРАТКИЕ» КОМПОНЕНТЫ
Пока мы представили дело так, как если бы речь состояла из последовательности физически дискретных единиц. Это не так. Речь состоит из непрерывных отрезков звучания различной длительности; физические перерывы происходят там, где говорящий делает паузу, чтобы перевести дыхание. То, что фонетист называет звуками речи, выделяется им из непрерывных потоков воздуха согласно каким-то эксплицитным или имплицитным критериям членения. Несколько упрощая вопрос, мы можем сказать, что число звуков речи, выделимых на непрерывном отрезке речи, определяется числом последовательных состояний органов речи: изменение состояния органов речи может быть определено как ощутимое изменение по меньшей мере одной из выделенных артикуляторных переменных. Из этого следует, что некоторые переменные могут сохранять одно и то же значение на протяжении ряда последовательных состояний органов речи. Рассмотрим два английских слова cats и cads, которые могут быть записаны в широкой транскрипции как [kats] и [kadz]. Заметим, что фонетическая нотация, используемая здесь, представляет различие между этими двумя словами как сумму различий между двумя различными звуками речи (то есть [t] : [d] и [s] : [z]). В действительности, различие заключается только в одной из арти-куляторных переменных (мы можем пренебречь различием гласных): в [kats] сегмент слова, появляющийся после гласного, глухой; в [kadz] он звонкий (это некоторое упрощение, но оно не влияет на высказанное утверждение). Мы можем, таким образом, разграничить два вида фонетических компонентов, которые удобно называть «кратким» и «долгим» в соответствии с тем, занимают ли они одну или несколько позиций. Важно отметить, что один и тот же артикуляторный компонент может быть кратким или долгим в разных фонетических последовательностях. Например, в слове under компонент звонкости распространяется на все слово, компонент дентальности охватывает две позиции —[nd], тогда как назальность ограничена одной позицией — [n]; но в слове omnipotent назальность является долгим компонентом в [mn], и к различению позиций, занимаемых звуками речи [m] и [n], приводит нас переход от лабиальной к дентальной (точнее, альвеолярной) смычке.
Некоторые артикуляторные компоненты, в частности голос и назальность, не затрагиваемые наличием или отсутствием преграды в полости рта, участвуют в образовании как согласных, так и гласных. Например, отношение между гласными, записываемыми в Международном Фонетическом Алфавите (МФА) как [ḁ], [а] и [ã], такое же, как отношение между согласными [р], [b] и [m]; [t], [d] и [n]; [k], [g] и [ŋ] : первый член каждой тройки не является ни звонким, ни назализованным, второй — звонким, но не назализованным, третий— и звонким, и назализованным. Это можно проиллюстрировать посредством следующего гипотетического примера. Предположим, что в некотором данном языке существуют три слова, которые могут быть протранскрибированы фонетически как: a) [pḁtḁk], b) [badag] и с) [mãnãŋ]. Здесь участвуют пять артикуляторных переменных: три точки артикуляции — (i) лабиальная, (ii) дентальная и (iii) велярная смычка — и два компонента, которые могут участвовать в образовании как согласных, так и гласных, — наличие или отсутствие (iv) голоса и (v) назальности. Фонетические связи между тремя словами можно представить посредством двумерных матриц, приведенных на рис. 3; при этом горизонтальное измерение используется для обозначения временной последовательности, а вертикальное измерение — для определения «положительного» или «отрицательного» значения каждой из пяти релевантных артикуляторных переменных: «положительному» значению (звонкий, а не глухой; носовой, а не ротовой; дентальная, а не лабиальная или велярная смычка и т. д.) соответствует горизонтальная прерывистая черта, а «отрицательное» оставлено без специального обозначения. Эти матрицы абсолютно эквивалентны более обычным алфавитным транскрипциям: a) [pḁtḁk], b) [badag] и с) [mãnãŋ].
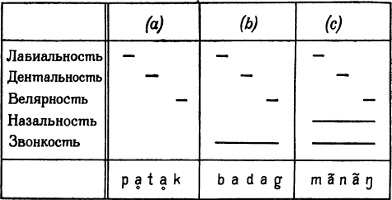
Рис. 3. Заметим, что, поскольку «лабиальность», «дентальность» и «велярность» предполагают преграду в этих точках артикуляции (артикуляторные компоненты гласных не приводятся: предполагается, что их значение постоянно), различение гласных и согласных, а следовательно, выделение пяти состояний органов речи, ясно из отсутствия преграды в двух сегментах и наличия преграды в трех сегментах каждого слова.
Как явствует из приведенной таблицы, в словах [pḁtḁk], [badag] и [mãnãŋ] наличие или отсутствие голоса и назальности суть долгие компоненты, распространяющиеся на всё слово от его начала до конца (напомним, что маленький кружочек под гласным означает, что этот гласный глухой, а «тильда» (~), помещенная над гласным, передает назализованность гласного, и если гласный не отмечен как глухой, то предполагается, что он звонкий, как «обычно»); также ясно, что представление соответствующих цепочек в виде последовательности сегментов, встречающих препятствие и не встречающих препятствия, позволяет различить согласные и гласные и в данном случае число звуков речи. Тщательное рассмотрение этого примера и обобщение фактов, неявно в нем содержащихся, должно привести нас к заключению, что такие выражения, как «[р]-звук», «[m]-звук» и т. п., — удобные, но не вполне точные способы обозначения «отрезка звука, характеризуемого в определенном месте лабиальностью, смычкой, глухостью и отсутствием назальности», «отрезка звука, характеризуемого в определенном месте лабиальностью, смычкой, звонкостью и назальностью» и т. п. (если ограничиться упоминанием лишь нескольких релевантных артикуляторных переменных). Алфавитная система транскрипции, обычно используемая фонетистами и употребляемая здесь при цитации примеров, таким образом, далеко не совершенная система транскрипции речи. Более удовлетворительной системой могла бы быть такая, в которой каждый из перекрывающихся артикуляторных компонентов любого данного отрезка речи получал бы непосредственную символизацию и в которой была бы эксплицитно обозначена относительная длина компонентов. Фактически всякий, кто хочет правильно читать фонетическую транскрипцию, должен сначала научиться «деалфавитизировать» ее, мысленно подставляя вместо каждого символа обозначаемый им пучок артикуляторных компонентов и соединяя эти компоненты друг с другом в последовательность, согласно проиллюстрированному выше принципу.
Этот момент рассматривался здесь довольно подробно в связи с тем, что в начальных и популярных изложениях теории языка он не всегда подчеркивается должным образом, а иногда и вовсе не упоминается. Слишком часто создается впечатление, что речь состоит из последовательностей дискретных и независимых звуков и что эти звуки речи суть конечные единицы артикуляторного фонетического анализа. Мы скоро узнаем, что разграничение между долгими и краткими компонентами, проведенное здесь на фонетической основе, может получить также и фонологическое обоснование.
3.2.8. ФОНЕТИЧЕСКИЕ АЛФАВИТЫ
Читатель теперь легко воспримет следующее утверждение. Международный Фонетический Алфавит (МФА) основан на латинском алфавите. Кроме того, фонетические значения, приданные буквам, были установлены до того, как была осознана со всей ясностью необходимость разграничения фонетики и фонологии. То обстоятельство, что МФА по своему происхождению связан с латинским алфавитом, получило отражение в известной непоследовательности символизации некоторых артикуляторных признаков и в представлениях МФА относительно «нормальности» и «ненормальности» [тех или иных артикуляций]. В целом буквы были предназначены для символизации «звуков», которые обозначаются ими в одном или нескольких из главных европейских языков, использующих латинский алфавит; некоторым избыточным буквам, например х (ср. ее употребление в английском и других языках (=[ks])) или с (ср. ее употребление в английском, французском и др. языках (=[к] или [s])), было придано иное фонетическое истолкование; кроме того, было введено некоторое число новых символов (заимствованных из греческого алфавита или специально созданных), например [θ] и [ð] — для передачи начальных «звуков» английских слов thick и there. При создании новых символов алфавита авторы МФА и те, кто принимал участие в его дальнейшем совершенствовании, проявили большую изобретательность, а также достойное похвалы внимание к требованиям полиграфического порядка; однако возможность создания новых отдельных символов была очевидным образом практически ограничена. Поэтому в МФА с самого начала было предусмотрено использование диакритических значков при буквах. Диакритические значки употребляются, как мы видели выше, либо для того, чтобы дать более «узкую» транскрипцию, чем это возможно при использовании только букв, либо для того, чтобы показать, что способ произнесения того или иного звука принято рассматривать, в соответствии с представлениями МФА, как «ненормальный».