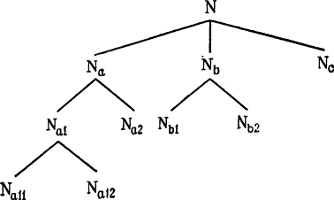
Na → {Na1, Na2}
Nb → {Nb1, Nb2}
Na1 → {Na11, Na12}
и т. д.
Каждое последующее выделение подклассов такого рода предполагает увеличение числа правил лексической субституции. Более того, очевидно, что эта формализация основывается на весьма частном (и, как мы увидим, ошибочном) предположении относительно грамматической структуры языка. Эти правила делят весь словарь на иерархически упорядоченные классы и подклассы (см. рис. 7) так, что Na11 и Na12 полностью принадлежат Na1; Na1 полностью принадлежит Na, а Na полностью принадлежит N и т. д. Это предположение лежало в основе первых генеративных грамматик, принявших подстановочную систему формализации (введенную в лингвистику Хомским).
Рис. 7.
Оно неудовлетворительно по двум причинам. Во-первых, оно ведет к увеличению числа отдельных списков в словаре при соответственно высокой степени многократного вхождения (см. § 4.2.10). Во-вторых, и это более важно, оно делает формулировку грамматических правил более сложной, чем этого требуют «факты». Цитируя Хомского: «Трудность состоит в том, что такая субкатегоризация [то есть выделение подклассов в словаре] обычно не является строго иерархической, а включает в себя перекрестную классификацию. Так, например, существительные в английском языке делятся на Имена Собственные (John, Egypt) и Имена Нарицательные (boy 'мальчик', book 'книга') и бывают Человеческими (John, boy) и Нечеловеческими (Egypt, book)... Но если субкатегоризация задана правилами подстановки, то какое-то из этих различий должно доминировать, и тогда другое нельзя будет сформулировать естественным образом». Например, если класс существительных сначала делится на Собственные Имена существительные и Нарицательные Имена существительные, затем каждое из них в свою очередь подразделяется на подклассы «Человеческий» и «Нечеловеческий», единственный способ сформулировать правило, относящееся ко всем «Человеческим существительным», — это отнести его к обоим совершенно не связанным классам «Собственные Человеческие» и «Нарицательные Человеческие» (поскольку в словаре нет списка «Человеческих Имен существительных»). Как пишет далее Хомский, «по мере углубления разложения [т. е. с каждой последующей субклассификацией] проблемы такого рода становятся столь значительными, что указывают на серьезную неадекватность грамматики, которая состоит только из правил подстановки». Мы не будем рассматривать предлагаемое Хомским исправление грамматических правил для решения этих проблем: в настоящей главе мы имеем дело с очень простой системой. Что касается словаря, то результат «перекрестной классификации» ясен. Предполагается, что каждое слово должно быть «индексировано» таким образом, чтобы можно было подобрать, например, любое «человеческое» существительное (независимо от того, «собственное» оно или «нарицательное»), любое «конкретное» существительное (независимо от того, «одушевленное» оно или «неодушевленное») и т. д. С этим типом классификации, или «индексирования», обычно связывают специальный термин признак (ср. в известной мере аналогичное использование термина «признак» в фонологии). Мы предполагаем, что каждое слово должно быть приведено в словаре (который уже не может теперь иметь вид системы правил подстановки, включенной в грамматику) вместе с набором признаков, например:
boy : [нарицательное], [человеческое], [мужской род], ...
door : [нарицательное], [неодушевленное], ...
Правило или правила лексической субституции придется, следовательно, формулировать так, чтобы можно было подобрать отдельное слово согласно одному или более указанным признакам. На каком этапе в системе порождения будут применяться правила лексической субституции — это спорный вопрос. Следует отметить, однако, что, хотя мы отказались от словаря, представленного в виде набора правил вида Na → {boy,...}, наше более общее правило остается в силе (см. § 4.3.2):
Х → х|х ∈ Х.
(«замени X на х, где х — член класса слов X»). Различие в том, что теперь X — это класс слов, удовлетворяющих специальной признаковой характеристике. Так, если порождаемое грамматикой предложение предусматривает «нарицательное, человеческое» существительное «мужского рода», то X —это класс, состоящий из всех слов лексикона, содержащих в качестве грамматических признаков [на-рицательность], [человечность], [мужской род], например boy. Однако списка членов этого сложного класса не существует.
4.3.4. ИМПЛИКАЦИИ КОНГРУЭНТНОСТИ ГРАММАТИЧЕСКОЙ И СЕМАНТИЧЕСКОЙ КЛАССИФИКАЦИИ
Теперь мы можем перейти к следующему вопросу. Хотя этот вопрос почти не имеет отношения к пониманию генеративной грамматики, как она излагалась до сих пор в опубликованных работах, он начинает приобретать определенное значение в связи с некоторыми недавними предложениями, касающимися формализации семантики. Как мы увидим в последующих главах, есть серьезные основания полагать, что слияние грамматики и семантики приведет к некоторому сближению между «формальной» и «понятийной» грамматикой. По этой причине особенно важно не упустить из виду некоторые общие положения.
Термины, которые мы использовали для обозначения признаков, упоминавшихся в предыдущем абзаце («собственное», «нарицательное», «одушевленное», «мужской род» и т. п.), трактовались как грамматические. Мы не отказались от того принципиального положения, согласно которому подобные термины, обозначая классы, упоминаемые в грамматических правилах, представляют собой условные наименования классов, основанных, как мы согласились считать, на дистрибуции. Однако эти условные наименования (по происхождению связанные с «понятийной» грамматикой) явно несут определенные семантические импликации. Мы уже упоминали о конгруэнтности, или взаимном соответствии, которое наблюдается в разной степени между грамматической и семантической структурой языка; и мы вернемся к этому вопросу позже. Так, можно полагать, что большинство грамматически «одушевленных» существительных будет обозначать людей или животных, что большинство существительных «мужского рода» будет обозначать мужчин и т. д. Нередко, однако, между классификацией слов, использующей такие признаки, как «одушевленность» или «мужской род», и классификацией, основанной на значении слов, могут наблюдаться противоречия (ср. гл. 7). Это давно признано и является главной причиной, в связи с которой большинство лингвистов отказалось от «понятийной» грамматики.
В то же время следует ясно понимать, что при достаточно полном описании языка в словарь должны включаться как грамматические, так и семантические сведения о каждом приведенном в нем слове.
Семантическую информацию, возможно, следует организовать таким образом, чтобы во всех тех случаях, когда между грамматической и семантической классификацией наблюдается соответствие, было бы возможным вывести часть грамматической информации (требуемой для действия грамматических правил) из описания значения слова. Предположим, например, что слово man приводится в словаре вместе с описанием его значения (в какой бы то ни было форме), и, кроме того, предположим, что из этих сведений можно вывести посредством соответствующего правила, что денотатом man (по крайней мере в одном из значений) является взрослый человек мужского пола (NB: из этого не следует, что значение man — это 'взрослый, человек, мужского пола': эта оговорка существенна в свете того, что будет сказано в главах по семантике). При таком условии мы можем вывести из этого грамматическую характеристику слова man, включающую признаки [мужской род], [человечность], что имплицирует [одушевленность] и т. д. Это — грамматическая классификация, так как она предназначена для объяснения таких дистрибуционных фактов, как употребление форм who 'кто' vs. which 'который, что'; he, him, his 'он, ему, его...' vs. she, her 'она, ее' vs. it, its 'оно, его' и т. д. Например, *The man which came... или *The man washed her own shirt должны быть отвергнуты как неприемлемые и, как мы полагаем, неграмматичные.