Несмотря на достижения Google Brain, нам пока нечем похвастаться. Человеческий мозг работает на малой мощности, порядка 20 ватт, а суперкомпьютеру требуются миллионы ватт для работы35, 49а – 57. В то время как мозг не нужно программировать (пусть даже иногда кажется, что он запрограммирован) и он теряет нейроны на протяжении своей жизни без существенного функционального истощения, компьютер, потерявший один-единственный чип, может сломаться, и обычно машины не могут адаптироваться к миру, с которым взаимодействуют50. Гари Маркус, нейробиолог из Нью-Йоркского университета, так сформулировал эту нейроморфную задачу в перспективе: «В такие времена я нахожу полезным вспомнить базовую истину: человеческий мозг – это самый сложный орган во Вселенной, и мы до сих пор не представляем, как он работает. Кто сказал, что копирование его восхитительной мощи будет простым?»58 Тем не менее наблюдается довольно большой прогресс в распознавании речи, лиц, жестов и снимков, в чем так силен человеческий мозг и слаб компьютер. Я посетил немало конференций и читал лекции в разных странах, с синхронным переводом, и меня особенно поразило одно достижение: Ричард Рашид, возглавлявший некогда научное подразделение в Microsoft, выступал с лекцией в Китае, и компьютер не только синхронно выдавал ее в иероглифах, но и переводил на китайский (смоделированным) голосом самого Рашида36. Программа DeepFace от Facebook, с самой большой в мире фотобиблиотекой, может определить, принадлежат ли две фотографии одному и тому же человеку, с точностью в 97,25 %59, 60. Последствия для медицины очевидны. Ученые уже показывают, что компьютеры способны распознавать выражения лиц, например боль, точнее, чем люди, и происходит поразительный прогресс в распознавании лиц компьютерами61–63. Специалисты по информатике из Стэнфордского университета использовали кластер из 1600 компьютеров для подготовки к распознаванию снимков, тренировки проводились на 20 000 различных объектов. Больше к нашей теме относится то, что они использовали инструменты глубинного обучения для определения, является ли образец, взятый при биопсии в случае рака груди, злокачественным37. Эндрю Бек из Гарвардского университета разработал компьютеризованную систему для диагностики рака груди и прогнозирования шансов на выживание, основываясь на автоматической обработке снимков. Оказалось, что обучение на основе обработки данных в ЭВМ обеспечивает бо́льшую точность в сравнении с патологами, и это помогло распознать новые особенности, остававшиеся незамеченными на протяжении многих лет64. И нам не следует забывать об активной поддержке развития искусственного интеллекта, которая позволила создать видящие и слышащие устройства. Камера-датчик Orcam устанавливается на очках слабовидящих людей, она видит предметы и передает эту информацию через наушник, используя костную проводимость39. Слуховые аппараты GN ReSound Linx и Starkey – это подключаемые к смартфону приложения, которые «обеспечивают людям, потерявшим слух, возможность слышать лучше тех, кто нормально слышит»65. Есть инвалидные кресла для людей без четырех конечностей, контролируемые мыслью, в духе бионического будущего39. Поэтому способность искусственного интеллекта преображать вещный мир в медицине нельзя упускать из виду. Конечно, технологии могут легко соединяться с робототехникой. В Калифорнийском университете в Сан-Франциско больничная аптека полностью автоматизирована, и роботизированная выдача лекарственных препаратов пока происходит без единой ошибки.
Человек и Интернет медицинских вещей
Теперь мы готовы говорить о медицине и ее возросшей, благодаря нашим цифровым машинам и инфраструктуре, интеллектуальной мощи. В настоящее время количество данных, ежегодное производимое в мире в расчете на одного человека, составляет около одного терабайта, или пяти зеттабайтов, данных в год (или 40 секстильонов). Но вспомните из главы 5, когда мы говорили о человеческой ГИС, что только омики одного человека добавят по крайней мере еще пять терабайтов, а мы еще не достигли даже потокового поступления данных с биодатчиков в режиме реального времени, которые быстро заполонят объем генерируемых сейчас данных. И тем не менее едва ли достаточно добавить другие компоненты ГИС, в частности поток данных в пикселях медицинских снимков и предстоящий шквал информации из Интернета медицинских вещей, чтобы все преобразилось.
Но это, безусловно, не просто история исследования с участием одного человека (N = 1). Как было показано в главе 11, хотя иметь много данных о вас было бы полезно, для того, чтобы сделать данные максимально информативными, нужно сравнить их со всеми данными от каждого человека на планете (рис. 13.4). До всех людей мы никогда не доберемся, тем не менее чем их больше, тем лучше, и компании типа Facebook показывают, что можно сделать.
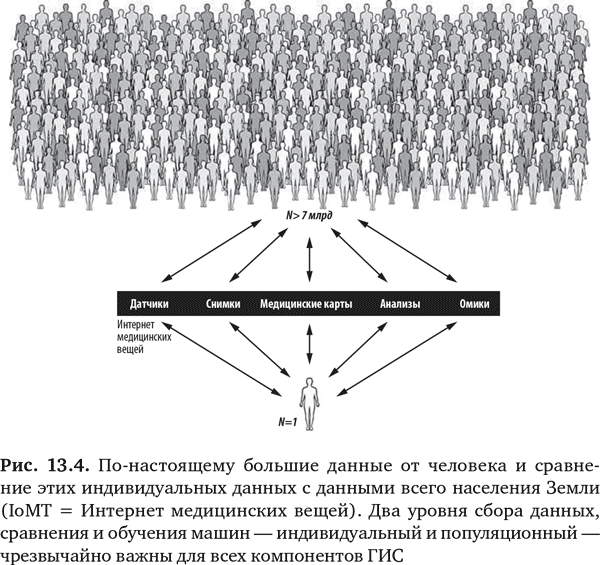
Главное, что обучение машин, подобных стоящим за IBM Watson и другими системами, позволяет нам идти вширь (N = 7 млрд) и вглубь (N = 1) не просто в поисках знаний, но и в поисках предсказаний и понимания. В отношении каждого человека нам нужно знать пусковые механизмы и сложные взаимосвязи на многочисленных уровнях – геномном, биологическом, физиологическом, средовом, – которые отвечают за предрасположенность к заболеванию или состоянию. Цель – не просто оценить риск в течение жизни человека, а в определенное время или момент. Многое мы узнаем и в результате углубленного исследования максимально возможного количества людей на предмет сигналов, обогащающих наше понимание того, что требуется для проявления болезни или для ее предотвращения. Только сейчас мы можем собрать такие паноромные данные по каждому отдельному человеку и в группах населения, и, обладая способностью управлять и обрабатывать огромные наборы данных, мы оказываемся в завидном положении предсказателей болезни. И, может быть, после того, как мы научимся все это делать хорошо, нам удастся даже предотвращать болезни у некоторых людей.
Предсказание болезни: кто, когда, как, почему и что?
Для начала убедимся в том, что мы различаем понятия «предсказание» и «диагноз». Онлайн-тестеры для проверки симптомов66 пользуются все большей популярностью и вниманием в Интернете и помогают людям проводить «самодиагностику» (с помощью компьютера), но они не предсказывают болезнь. В лучшем случае из набора симптомов, которые вводит человек, предлагается дифференциальная диагностика, и правильный диагноз входит в список вариантов. Это полезно и практично, но это ничего не предсказывает. Точно так же разработчики из Biovideo – которые разрабатывают приложение для суперкомпьютера IBM Watson, чтобы «мать с больным ребенком в четыре утра могла воспользоваться IBM Watson и спросить, что случилось с ее ребенком и получить точный ответ»67а, – могут создать что-то полезное, но это что-то не имеет отношения к прогнозу.
У нас очень серьезная проблема с ошибочной диагностикой: диагноз – неправильный или правильный – ставится пациенту слишком поздно, и эта проблема затрагивает 12 млн американцев в год67b, 67c. Для решения этой проблемы можно обратиться к технологиям и контекстуальным вычислениям. Популярный телесериал «Доктор Хаус» очень поучителен в этом плане. Главный герой, Грегори Хаус, – блестящий диагност, который разбирается с самыми редкими и таинственными случаями, ставящими в тупик других врачей68–71. Для того чтобы этого добиться, он использует байесовский подход, при котором вся информация – история болезни, медосмотр, лабораторные исследования, сканограммы – рассматривается в контексте всей ранее известной, относящейся к делу информации (что известно из теоремы Байеса[49] как клиническая предсказуемость результата испытания). Ответ «да» или «нет» не получается. Скорее, есть вероятность, что у пациента диагноз X или Y. Это можно сравнить с распространенным подходом, предусматривающим «да» или «нет» на основании исключительно статистики вероятности (типа Р < 0,05, где Р – коэффициент вероятности). Модель доктора Хауса идеально подходит для компьютерной автоматизации в медицине, и точно так же работает IBM Watson70, 71. Вероятность предварительного диагноза учитывает всю медицинскую литературу, которая была опубликована до сегодняшнего дня. Когда вы вводите в IBM Watson все имеющиеся данные о конкретном пациенте в поиске диагноза, вы получаете список возможных вариантов. Каждому присваивается вес или вероятность (отношение правдоподобия).