Некоторые принялись защищать GFT, указывая, что данные были всего лишь дополнением к санитарно-эпидемиологическим центрам, а Google никогда не заявляла, что обладает магическим инструментом. Наиболее взвешенную точку зрения выразили Гари Маркус и Эрнест Дэвис в своей статье «Восемь (нет, девять!) проблем с большими данными» (Eight (No, Nine!) Problems With Big Data)20. Я уже обращался ко многим их выводам, но мнение Маркуса и Дэвиса насчет беззастенчивой рекламы больших данных и относительно того, что́ большие данные могут (и чего не могут), заслуживает особого упоминания: «Большие данные повсюду. Кажется, что все их собирают, анализируют, делают на этом деньги и прославляют их силу или боятся их… Большие данные никуда не денутся, как и должно быть. Но давайте будем реалистами: это важный ресурс для всех, кто анализирует данные, а не серебряная пуля»20.
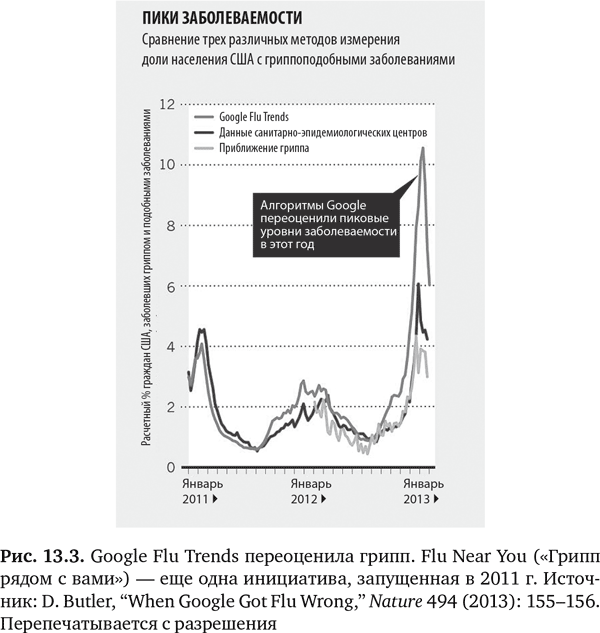
Несмотря на проблемы с GFT, подобные шаги никуда не ведут. Альтернативный и более поздний подход – это предсказание вспышки заболеваемости с использованием меньшей базы людей, которые активно поддерживали связь в Twitter, – так называемых «центральных узлов», когда люди по сути выступают в качестве датчиков21а. Это позволило обнаружить вспышки вирусных заболеваний на семь дней быстрее, чем когда рассматривалось население в целом. Точно так же алгоритм HealthMap, который проводит поиск в десятках тысяч социальных сетей и новостных СМИ, смог предсказать вспышку лихорадки Эбола в 2014 г. в Западной Африке на девять дней раньше Всемирной организации здравоохранения21b. Я углубился в историю, связанную с Google и гриппом и вспышками заразных болезней, потому что они отображают ранние этапы пути, по которому мы идем, и показывают, как мы можем заплутать, используя большие массивы данных для предсказаний в медицине. Но знать, как мы сбились в пути, важно, если мы собираемся по нему двигаться.
Предсказания на индивидуальном уровне
По сравнению с данными по всему населению, как в случае Google Flu Trends, более мощный эффект достигается комбинацией детальных данных отдельного человека21с с детальными данными остального населения. Вы уже сталкивались с этим раньше. Например, компания Pandora располагает базой данных с предпочитаемыми песнями по более чем 200 млн зарегистрированных пользователей, которые в общей сложности нажали на кнопки «нравится» или «не нравится» свыше 35 млн раз22. В компании знают, кто слушает музыку, когда ведет машину, у кого Android, а у кого iPhone и где живет каждый из них. В результате можно предсказать не только какая музыка понравится слушателю, но даже его политические предпочтения, и компания уже использовала это в целевой политической рекламе во время президентской избирательной кампании и выборов в конгресс. Эрик Бишке, главный научный сотрудник Pandora, cчитает, что их программы по сбору данных позволяют проникнуть в самую суть своих пользователей. И это действительно так, поскольку, чтобы дойти до сути, они интегрируют два слоя больших данных – ваши данные и данные миллионов других людей22.
Используя компании, торгующие данными, типа Acxiom (которые обсуждались в предыдущей главе), Медицинский центр Питтсбургского университета проводит углубленный анализ данных своих пациентов, включая характерное поведение во время шопинга, для предсказания вероятности пользования услугами пунктов оказания первой помощи23. Подобным образом поступает и Организация здравоохранения Северной и Южной Каролины, собирая данные о кредитных картах клиентов – 2 млн человек в своем регионе, чтобы определить пациентов с высокой степенью риска заболеваний (например, через покупки фастфуда, сигарет, спиртных напитков и лекарств)24. Предиктивная модель, используемая в Питтсбурге, показала, что потребители, которые делают больше всего покупок через Интернет и заказывают товары по почте, чаще обращаются в пункты оказания первой помощи, чего организации здравоохранения отнюдь не приветствуют. Обнаруженные взаимосвязи со временем обрастают новыми подробностями, когда информация о нынешних пациентах поступает повторно и большее количество пациентов включается в систему, чтобы лучше предсказывать определенные процессы. Но вопросы конфиденциальности и этичности остаются.
Эти примеры могут рассматриваться как рудиментарная форма искусственного интеллекта – машин или программного обеспечения, демонстрирующих интеллект, подобный человеческому. Другие примеры, которые, возможно, уже окружают вас, включают личных цифровых помощников типа Google Now, Future Control, Cortana25 и SwiftKey26, которые сводят информацию из электронных писем, СМС, ежедневников, записных книжек, истории поисковых запросов, местоположений, покупок, того, с кем вы проводите время, ваших пристрастий в искусстве и вашего поведения в прошлом27. Основываясь на том, что они узнают из этой информации, эти приложения появляются на вашем экране, чтобы напомнить о предстоящей встрече, показать пробки на вашем маршруте или сообщить новости по поводу вашего авиарейса. Читая то, что пишут в Twitter, Future Control ваши друзья, вам могут дать совет: «Ваша девушка грустит, пошлите ей цветы»28. SwiftKey даже вычисляет ваши ошибки при наборе текста и исправляет их, если вы все время нажимаете не на ту клавишу. Google Now работает с авиалиниями и организаторами мероприятий, чтобы иметь доступ к информации о билетах, и может даже слушать звук вашего телевизора, чтобы заранее обеспечить вас программой телевидения29. Как вы можете догадаться, это гораздо более мощные возможности, чем поиск соответствий, приводящий в действие Google Flu Trends, и они имеют непосредственное отношение к медицине.
Такая предсказательная сила полагается исключительно на обучение машин, ключевое свойство искусственного интеллекта. Чем больше данных вводится в программу или компьютер, тем большему они учатся, тем лучше алгоритмы и, предположительно, тем умнее они становятся.
Техники обучения машин и искусственного интеллекта – это то, что обеспечивало триумф суперкомпьютера IBM Watson над людьми в телевикторине Jeopardy! (Рискуй!)[47]. Требовалось быстро отвечать на сложные вопросы, ответы на которые не найти с помощью поисковика Google30–32. IBM Watson были обучены ответам на сотни тысяч вопросов, которые задавались в предыдущих играх-викторинах Jeopardy! вооружены всей информацией из Википедии и запрограммированы на предиктивное моделирование. Здесь не предсказание будущего, а просто предсказание того, что у IBM Watson есть правильный ответ. В основе предсказательных возможностей суперкомпьютера был внушительный портфель систем для обучения машин, включая сети Байеса, цепи Маркова, метод опорных векторов и генетические алгоритмы33. Не стану больше в это углубляться: я недостаточно умен, чтобы все это понять, и, к счастью, это не особо относится к тому, куда мы с вами сейчас идем.
Еще один подвид искусственного интеллекта и обучения машин2, 20, 34–48, известный как глубинное обучение, имеет важное значение для медицины. Глубинное обучение стоит за способностью Siri декодировать речь, как и за экспериментами Google Brain[48] с распознаванием образов. Исследователи из Google X извлекли из видеозаписей на YouTube 10 млн изображений и запустили их в сеть из 1000 компьютеров, чтобы посмотреть, что Google Brain, обладающий миллионом моделируемых нейронов и миллиардом моделируемых синапсов, способен предложить самостоятельно35, 36. Ответ – кошек. Интернет, по крайней мере сегмент YouTube (который занимает весьма существенную его часть), полон видеозаписей кошек. Кроме опознания кошки это открытие проиллюстрировало когнитивные вычисления, также известные как нейроморфные49а. Если компьютеры могут соревноваться с человеческим мозгом, как гласит теория, то можно добиться перехода их функциональных возможностей в плане восприятия, действия и понимания на следующий уровень. Прогресс в нейроморфных вычислениях идет с головокружительной скоростью. В прошлом году точность компьютерного зрения – например, распознавание пешехода, шлема, велосипедиста, автомобиля – улучшилась с 23 % до 44 %, при этом частота ошибок снизилась с 12 % до менее 7 %49b.