Очевидно: если бы Робби их знал, все пошло бы отлично — как в наивном байесовском алгоритме, каждый кластер определялся бы своей вероятностью (17 процентов сгенерированных объектов — игрушки) и распределением вероятности каждого атрибута среди членов кластера (например, 80 процентов игрушек коричневые). Робби мог бы оценивать вероятности путем простого подсчета числа игрушек в имеющихся данных, количества коричневых игрушек и так далее, но для этого надо знать, какие предметы — игрушки. Эта проблема может показаться крепким орешком, но, оказывается, мы уже знаем, как ее решить. Если бы в распоряжении Робби имелся наивный байесовский классификатор и ему необходимо было определить класс нового предмета, нужно было бы только применить классификатор и вычислить вероятность класса при данных атрибутах объекта. Маленький, пухлый, коричневый, похож на медведя, с большими глазами и галстуком-бабочкой? Вероятно, игрушка, но, возможно, животное.
Итак, Робби сталкивается с проблемой «курица или яйцо»: зная классы предметов, он мог бы получить модели классов путем подсчета, а если бы знал модели, мог бы сделать заключение о классах объектов. Если вы думаете, что опять застряли, это далеко не так: чтобы стартовать, надо просто начать угадывать классы для каждого предмета каким угодно способом, даже произвольно. На основе этих классов и данных можно получить модели классов, на основе этих моделей — вновь сделать вывод о классах и так далее. На первый взгляд это кажется безумием: придется бесконечно кружиться между выводами о классах на основе моделей и моделей на основе их классов, и даже если это закончится, нет причин полагать, что кластеры получатся осмысленные. Но в 1977 году трое статистиков из Гарварда — Артур Демпстер, Нэн Лэрд и Дональд Рубин — показали, что сумасшедший план работает: после каждого прохождения по этой петле модель кластера улучшается, а после достижения моделью локального максимума похожести повторения заканчиваются. Они назвали эту схему EM-алгоритмом, где E — ожидания (expectation, заключение об ожидаемых вероятностях), а M — максимизация (maximization, оценка параметров максимальной схожести). Еще они показали, что многие предыдущие алгоритмы были частными случаями EM. Например, чтобы получить скрытые модели Маркова, мы чередуем выводы о скрытых состояниях с оценкой вероятностей перехода и наблюдения на их основе. Когда мы хотим получить статистическую модель, но нам не хватает какой-то ключевой информации (например, классов примеров), всегда можно использовать EM-алгоритм, что делает его одним из самых популярных инструментов в области машинного обучения.
Вы, возможно, заметили определенное сходство между методом k-средних и EM-алгоритмом, поскольку оба чередуют отнесение сущностей к кластерам и обновление описаний кластеров. Это не случайность: метод k-средних сам по себе — частный случай EM-алгоритма, который получается, если у всех атрибутов «узкое» нормальное распределение, то есть нормальное распределение с очень маленькой дисперсией. Если кластеры часто перекрываются, объект может относиться, скажем, к кластеру A с вероятностью 0,7 и к кластеру B с вероятностью 0,3, и нельзя просто отнести его к кластеру A без потери информации. EM-алгоритм учитывает это путем частичного приписывания объекта к двум кластерам и соответствующего обновления описаний этих кластеров, однако, если распределения очень сконцентрированы, вероятность, что сущность принадлежит к ближайшему кластеру, всегда будет приблизительно равна единице, и нужно только распределить объекты по кластерам и усреднить их в каждом кластере, чтобы вычислить среднее — то есть получится алгоритм k-среднего.
До сих пор мы рассматривали получение всего одного уровня кластеров, но мир, конечно, намного богаче, и одни кластеры в нем вложены в другие вплоть до конкретных предметов: живое делится на растения и животных, животные — на млекопитающих, птиц, рыб и так далее до домашнего любимца — пса Фидо. Но проблем это не создает: получив набор кластеров, к ним можно относиться как к объектам и, в свою очередь, объединять их в кластеры все более высокого уровня, вплоть до кластера всех объектов. Или же можно начать с грубой кластеризации, а затем все больше дробить кластеры на подкластеры: игрушки Робби делятся на мягкие игрушки, конструкторы и так далее. Мягкие игрушки — на плюшевых медведей, котят и так далее. Дети, видимо, начинают изучение мира где-то посередине, а потом идут и вверх, и вниз. Например, понятие «собака» они усваивают до того, как узнают о «животных» и «гончих». Для Робби это может стать хорошей стратегией.
Открытие формы данных
Независимо от того, поступают ли данные в мозг Робби из его органов чувств или в виде потока миллионов кликов клиентов Amazon, сгруппировать множество в меньшее число кластеров — лишь половина дела. Второй этап — сократить описание объектов. Первый образ мамы, который видит Робби, будет состоять, может быть, из миллиона пикселей, каждый своего цвета, однако человеку вряд ли нужен миллион переменных, чтобы описать лицо. Аналогично каждый товар, на который вы кликнули на сайте Amazon, дает частицу информации о вас, но на самом деле Amazon интересны не ваши клики, а ваши вкусы. Вкусы довольно стабильны и в какой-то мере подразумеваются в кликах, количество которых растет безгранично во время пользования сайтом и должно понемногу складываться в картину предпочтений точно так же, как пиксели складываются в картинку лица. Вопрос в том, как реализовать это сложение.
У человека есть примерно 50 лицевых мышц, поэтому 50 чисел должно с лихвой хватить для описания всех возможных выражений лица. Форма глаз, носа, рта и так далее — всего того, что помогает отличить одного человека от другого, — тоже не должна занимать больше нескольких десятков чисел. В конце концов, художникам в полиции достаточно всего десяти вариантов каждой черты лица, чтобы составить фоторобот, позволяющий опознать подозреваемого. Можно добавить еще несколько чисел для описания освещения и наклона, но на этом все. Поэтому, если вы дадите мне примерно сотню чисел, этого должно хватить для воссоздания лица, и наоборот: мозг Робби должен быть способен взять картинку лица и быстро свести ее ко все той же сотне по-настоящему важных чисел.
Специалисты по машинному обучению называют этот процесс понижением размерности, потому что он уменьшает множество видимых измерений (пикселей) до нескольких подразумеваемых (выражение и черты лица). Понижение размерности важно для того, чтобы справиться с большим объемом данных, например данными, поступающими каждую секунду из органов чувств. Может быть, действительно лучше один раз увидеть, чем сто раз услышать, но обрабатывать и запоминать изображения в миллион раз сложнее, чем слова. Тем не менее зрительная кора головного мозга каким-то образом довольно хорошо справляется с уменьшением такого объема информации до приемлемого, достаточного, чтобы ориентироваться в мире, узнавать людей и предметы и помнить увиденное. Это великое чудо познания настолько естественно для нас, что мы его даже не замечаем.
Наводя порядок в своей библиотеке, вы тоже выполняете своего рода понижение размерности от обширного пространства тем до одномерной полки. Некоторые тесно связанные книги неизбежно окажутся далеко друг от друга, но все равно можно расставить их так, чтобы такие случаи были редкими. Алгоритм понижения размерности делает именно это.
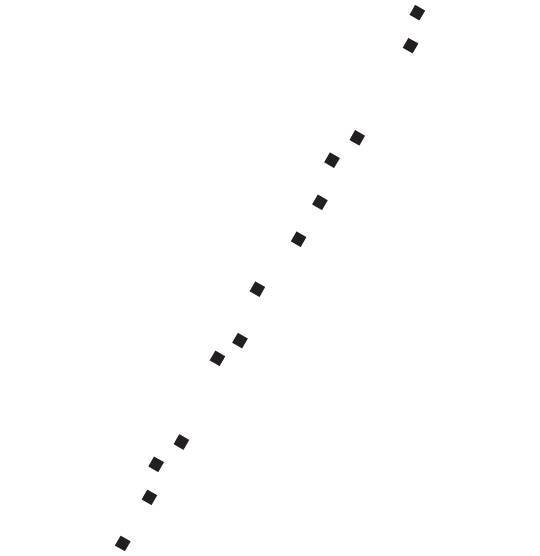
Представьте, что я дал вам координаты GPS всех магазинов в Пало-Альто в Калифорнии и вы нанесли их на листок бумаги:
Наверное, взглянув на эту схему, вы сразу поймете, что главная улица городка ведет с юго-запада на северо-восток. Хотя вы не рисовали саму улицу, интуиция подсказывает, где она проходит, потому что все точки лежат на прямой линии (или рядом с ней — магазины могут быть по разные стороны улицы). Догадка верна: эта улица — Юниверсити-авеню, и, если вы окажетесь в Пало-Альто и захотите перекусить и сделать покупки, туда и надо идти. Еще лучше, что, когда магазины сконцентрированы на одной улице, для описания их расположения нужно уже не два числа, а всего одно — номер дома, а для большей точности — расстояние от магазина до пригородной железнодорожной станции в юго-западном углу, откуда начинается Юниверсити-авеню.