Напрашивается вопрос: как выбрать лучший атрибут для тестирования в узле? Точность — количество правильно предсказанных примеров — работает не очень хорошо, потому что мы не пытаемся предсказать конкретный класс, а, скорее, стремимся постепенно разделять классы, пока не «очистим» все ветви. Это заставляет вспомнить понятие энтропии[51] из теории информации. Энтропия набора предметов — мера его неупорядоченности. Если в группе из 150 человек будет 50 республиканцев, 50 демократов и 50 независимых кандидатов, ее политическая энтропия максимальна. С другой стороны, если в группе одни республиканцы, энтропия будет равна нулю, во всяком случае, в отношении партийной принадлежности. Поэтому, чтобы получить хорошее дерево решений, мы выберем в каждом узле атрибут, который в среднем даст самую низкую энтропию классов по всем ее ветвям, с учетом количества примеров в каждой из ветвей.
Как и в случае обучения правилам, мы не хотим получить дерево, которое будет идеально предсказывать классы всех примеров в обучающей выборке, потому что это будет, вероятно, переобучением. Для его предотвращения мы, опять же, можем использовать тесты значимости или штрафные очки для больших размеров дерева.
Иметь отдельную ветвь для каждого значения атрибута неплохо, если они дискретные. А как насчет числовых атрибутов? Если выделять ветвь для каждого значения непрерывной переменной, дерево окажется бесконечно широким. Простое решение — выбрать ряд ключевых порогов на основе энтропии и использовать их. Например, «температура пациента выше или ниже 37,7 °C?». Для выявления у человека инфекции этой информации в сочетании с другими симптомами может быть достаточно.
Деревья решений находят применение во многих областях. Так, они делают важную работу в психологии. Эрл Хант[52] и его коллеги пользовались деревьями решений в 1960 году для моделирования усвоения человеком новых концепций, а один из магистрантов Ханта, Джон Росс Куинлан, попробовал использовать их в шахматах. Его первоначальная цель была скромной: предсказать результаты эндшпилей «король и ладья против короля и ферзя» на основе ситуации на доске. Теперь же дерево решений, согласно опросам, стало самым широко используемым алгоритмом машинного обучения, что неудивительно: эту методику легко понять и освоить, и обычно она дает довольно точный результат без лишних настроек. Куинлан — самый выдающийся исследователь в школе символистов. Этот невозмутимый прагматичный австралиец год за годом неустанно улучшал деревья решений, сделал их золотым стандартом в области классификации и пишет о них удивительно ясные статьи.
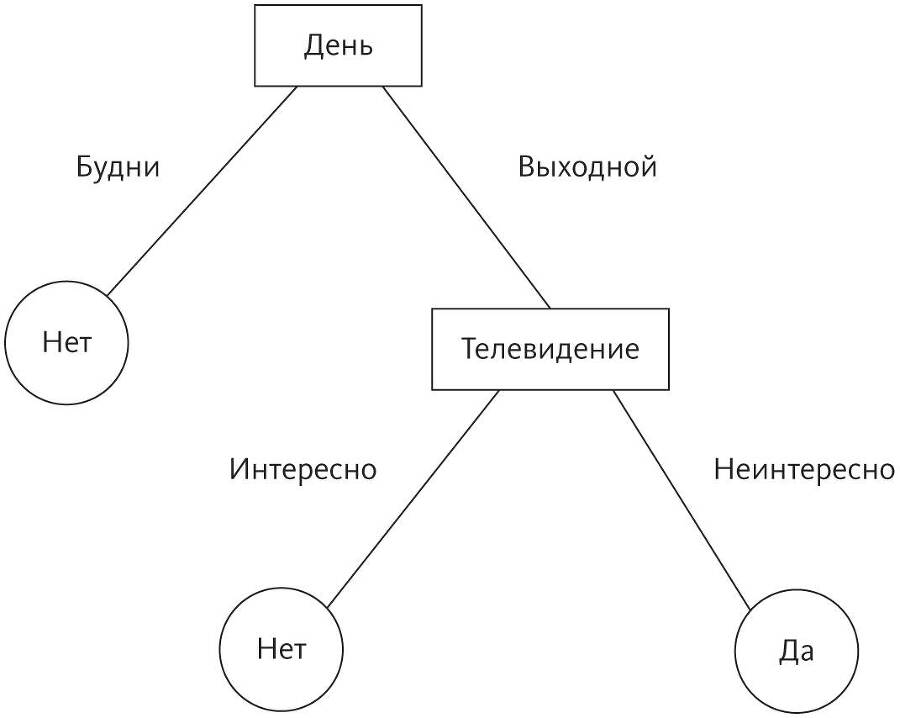
Что бы вы ни хотели предсказать, очень вероятно, что кто-то уже использовал для этого деревья решений. С их помощью разработанный Microsoft игровой контроллер Kinect определяет положение частей тела, получая сигналы от сенсоров глубины, и передает информацию в приставку Xbox. В 2002 году деревья решений обошли группу экспертов, правильно предсказав три из каждых четырех постановлений Верховного суда, в то время как люди дали менее 60 процентов правильных ответов. «Тысячи поклонников деревьев решений не могут ошибаться!» — думаете вы и набрасываете свое дерево, чтобы угадать ответ девушки на ваше приглашение:
Получается, что сегодня вечером она скажет «да». Вы делаете глубокий вдох, достаете телефон и набираете ее номер.
Символисты
Важнейшее убеждение символистов заключается в том, что интеллект можно свести к манипулированию символами. Математик решает уравнения, переставляя символы и заменяя одни другими согласно заранее определенным правилам. Так же поступает логик, когда делает выводы путем дедукции. Согласно этой гипотезе, интеллект не зависит от носителя: можно писать символы мелом на доске, включать и выключать транзисторы, выражать их импульсами между нейронами или с помощью конструктора Tinkertoys. Если у вас есть структура, обладающая мощью универсальной машины Тьюринга, вы сможете сделать все что угодно. Программное обеспечение можно вообще отделить от «железа», и, если вы хотите просто разобраться, как могут учиться машины, вам (к счастью) не надо волноваться о машинах как таковых, за исключением приобретения ПК или циклов на облаке Amazon.
Веру символистов в мощь манипуляций символами разделяют многие другие информатики, психологи и философы. Психолог Дэвид Марр утверждает, что любую систему обработки информации нужно рассматривать на трех уровнях: фундаментальные свойства проблемы, которую она решает, алгоритмы и представления, которые используются для ее решения, и их физическое воплощение. Например, сложение можно определить набором аксиом, не зависящих от того, как оно выполняется. Числа можно выразить по-разному (например, римскими и арабскими цифрами) и складывать с использованием разных алгоритмов, а алгоритмы могут выполняться на абаке, карманном калькуляторе или даже — что очень неэффективно — в уме. Обучение — яркий пример когнитивной способности, которую мы можем плодотворно изучать с точки зрения уровней Марра.
Символистское машинное обучение — ответвление инженерии знаний, одной из школ искусственного интеллекта. В 1970-х у так называемых систем на основе знаний были очень впечатляющие успехи, в 1980-х они быстро распространились, но потом вымерли. Главная причина — печально известное «узкое горло» приобретения знаний: получать информацию от экспертов и кодировать в виде правил слишком сложное, трудоемкое и подверженное ошибкам занятие, поэтому для большинства проблем такой подход нецелесообразен. Оказалось, что намного легче позволить компьютеру автоматически учиться, скажем, диагностировать заболевания путем просмотра в базах данных симптомов и исходов, чем без конца опрашивать врачей. Внезапно работы таких первопроходцев, как Рышард Михальский, Том Митчелл и Росс Куинлан, приобрели новую значимость, и с тех пор дисциплина непрерывно развивается. (Еще одной важной проблемой систем, основанных на знаниях, было то, что им сложно работать с неопределенностью. Подробнее мы поговорим об этом в главе 6.)
Благодаря своему происхождению и основополагающим принципам символистское машинное обучение ближе к другим областям науки об искусственном интеллекте, чем другие школы машинного обучения. Если информатику представить в виде континента, у символизма будет длинная граница с инженерией знаний. Обмен информацией происходит в обоих направлениях: обучающиеся алгоритмы используют введенное вручную знание, а знание, полученное путем индукции, пополняет базы знаний. Тем не менее вдоль этой границы проходит разлом между рационалистами и эмпириками, и пересечь ее непросто.
Символизм — кратчайший путь к Верховному алгоритму. Он не требует разбираться, как работает эволюция или головной мозг, и позволяет обойтись без сложной математики байесианства. Наборы правил и деревья решений просты для понимания, и поэтому пользователь представляет себе, что замышляет обучающийся алгоритм, ему легче отличить правильные действия от неправильных, при необходимости внести поправки и быть уверенным в результатах.
Но несмотря на популярность деревьев решений, более удобный исходный пункт для поисков Верховного алгоритма — обратная дедукция. У нее есть критически важное качество: в нее легко встраивать знания, а, как нам уже известно, из-за проблемы Юма это существенное преимущество. Кроме того, наборы правил — экспоненциально более компактный способ представления большинства понятий, чем деревья решений. Превратить дерево решений в набор правил несложно: каждый путь от корня к листу становится правилом, и нет никаких подводных камней. С другой стороны, если нужно превратить в дерево решений набор правил, в худшем случае придется разворачивать каждое из них в мини-дерево решений, а затем заменять каждый листок дерева, полученного из правила один, копией дерева для правила два, каждый листок каждой копии правила два копией правила три и так далее, что порождает серьезные проблемы.