Аналогия была искрой, из которой разгорелись величайшие научные достижения в истории человечества. Теория естественного отбора родилась, когда Дарвин, читая An Essay on the Principle of Population («Опыт о законе народонаселения») Мальтуса, был поражен сходством между борьбой за выживание в экономике и в природе. Модель атома появилась на свет, когда Бор увидел в ней миниатюрную Солнечную систему, где электроны соответствовали планетам, а ядро — Солнцу. Кекуле открыл кольцевую форму молекулы бензола, представив себе змею, пожирающую свой хвост.
У рассуждений по аналогии выдающаяся интеллектуальная родословная. Еще Аристотель выразил их в своем законе подобия: если две вещи схожи, мысль об одной из них будет склонна вызывать мысль о другой. Эмпирики, например Локк и Юм, пошли по этому пути. Истина, говорил Ницше, — это движущаяся армия метафор. Аналогии любил Кант, а Уильям Джеймс полагал, что чувство одинаковости — киль и позвоночник человеческого мышления. Некоторые современные психологи даже утверждают, что человеческое познание целиком соткано из аналогий. Мы полагаемся на них, чтобы найти дорогу в новом городе и чтобы понять такие выражения, как «увидеть свет» и «не терять лица». Подростки, которые в каждое предложение вставляют словечко «типа», согласятся, типа, что аналогия — это, типа, важная штука.
С учетом всего этого неудивительно, что аналогия играет видную роль в машинном обучении. Однако дорогу себе она пробивала медленно, и поначалу ее затмевали нейронные сети. Первое воплощение аналогии в алгоритме появилось в малоизвестном отчете, написанном в 1951 году Эвелин Фикс и Джо Ходжесом — статистиками из Университета Беркли, — и потом десятки лет не публиковалось в мейнстримных журналах. Однако тем временем начали появляться, а потом множиться другие статьи об алгоритме Фикс и Ходжеса, пока он не стал одним из самых исследуемых в информатике. Алгоритм ближайшего соседа — так он называется — будет первым шагом в нашем путешествии по обучению на основе аналогий. Вторым станет метод опорных векторов, который, как буря, налетел на машинное обучение на переломе тысячелетий и лишь недавно встретил достойного соперника в лице глубокого обучения. Третья и последняя тема — это полноценное аналогическое рассуждение, которое несколько десятилетий было базовым в психологии и искусственном интеллекте и примерно столько же — в машинном обучении.
Аналогизаторы — наименее сплоченное из пяти «племен». В отличие от приверженцев других учений, которых объединяет сильное чувство идентичности и общие идеалы, аналогизаторы представляют собой скорее свободное собрание ученых, согласных с тем, что в качестве основы обучения нужно полагаться на суждения о сходстве. Некоторые, например ребята, занимающиеся методом опорных векторов, могут даже не захотеть встать под общий зонтик. Но за окном идет дождь из глубоких моделей, и мне кажется, действовать сообща им не повредит. Аналогия — одна из центральных идей в машинном обучении, и аналогизаторы всех мастей — ее хранители. Может быть, в грядущем десятилетии в машинном обучении будет доминировать глубокая аналогия, соединяющая в один алгоритм эффективность ближайшего соседа, математическую сложность метода опорных векторов и мощь и гибкость рассуждения по аналогии. (Вот я и выдал один из своих секретных научных проектов.)
Попробуй подобрать мне пару
Алгоритм ближайшего соседа — самый простой и быстрый обучающийся алгоритм, какой только изобрели ученые. Можно даже сказать, что это вообще самый быстрый алгоритм, который можно придумать. В нем не надо делать ровным счетом ничего, и поэтому для выполнения ему требуется нулевое время. Лучше не бывает. Если вы хотите научиться узнавать лица и в вашем распоряжении есть обширная база данных изображений с ярлыками «лицо / не лицо», просто усадите этот алгоритм за работу, расслабьтесь и будьте счастливы. В этих изображениях уже скрыта модель того, что такое лицо. Представьте, что вы Facebook и хотите автоматически определять лица на фотографиях, которые загружают пользователи, — это будет прелюдией к автоматическому добавлению тегов с именами друзей. Будет очень приятно ничего не делать, учитывая, что ежедневно в Facebook люди загружают свыше трехсот миллионов фотографий. Применение к ним любого из алгоритмов машинного обучения, которые мы до сих пор видели (может быть, кроме наивного байесовского), потребовало бы массы вычислений. А наивный Байес недостаточно сообразителен, чтобы узнавать лица.
Конечно, за все надо платить, и цена в данном случае — это время проверки. Джейн Юзер только что загрузила новую картинку. Это лицо или нет? Алгоритм ближайшего соседа ответит: найди самую похожую картинку во всей базе данных маркированных фотографий — ее «ближайшего соседа». И если на найденной картинке лицо, то и на этой тоже. Довольно просто, но теперь придется за долю секунды (в идеале) просканировать, возможно, миллиарды фотографий. Алгоритм застают врасплох, и, как ученику, который не готовился к контрольной, ему придется как-то выходить из положения. Однако в отличие от реальной жизни, где мама учит не откладывать на завтра то, что можно сделать сегодня, в машинном обучении прокрастинация может принести большую пользу. Вообще говоря, всю область, в которую входит алгоритм ближайшего соседа, называют «ленивым обучением», и в таком термине нет ничего обидного.
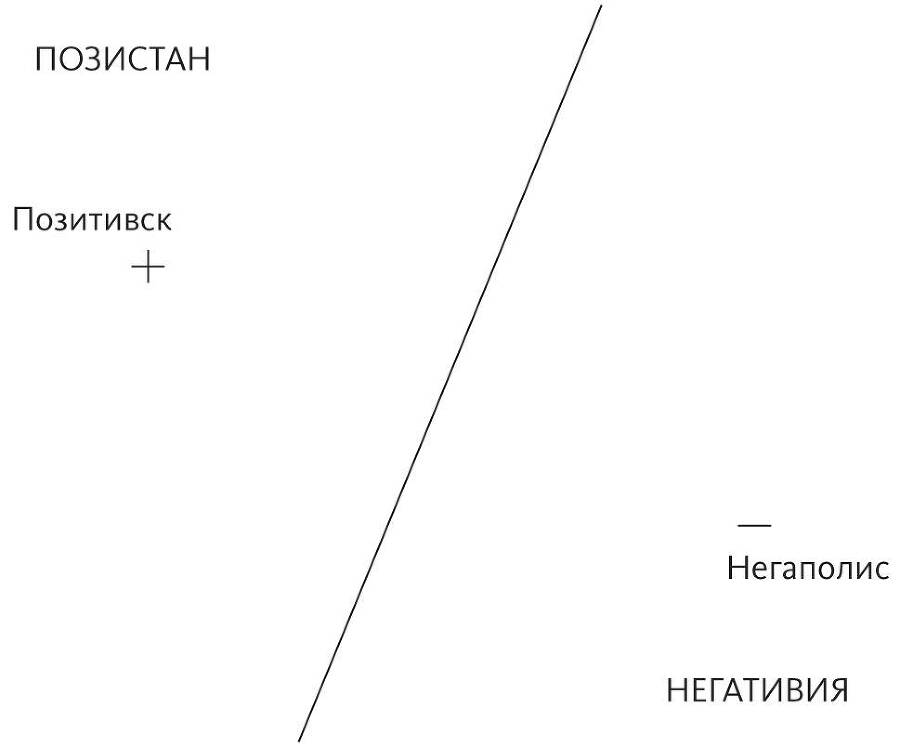
Ленивые обучающиеся алгоритмы намного умнее, чем может показаться, потому что их модели, хотя и неявные, могут быть невероятно сложными. Давайте рассмотрим крайний случай, когда для каждого класса у нас есть только один пример. Допустим, мы хотим угадать, где проходит граница между двумя государствами, но знаем мы только расположение их столиц. Большинство алгоритмов машинного обучения зайдет здесь в тупик, но алгоритм ближайшего соседа радостно скажет, что граница — это прямая линия, лежащая на полпути между двумя городами.
Точки на этой линии находятся на одинаковом удалении от обоих столиц. Точки слева от нее ближе к Позитивску, поэтому ближайший сосед предполагает, что они относятся к Позистану, и наоборот. Конечно, если бы это была точная граница, нам бы крупно повезло, но и это приближение, вероятно, намного лучше, чем ничего. Однако по-настоящему интересно становится, когда мы знаем много городов по обеим сторонам границы:
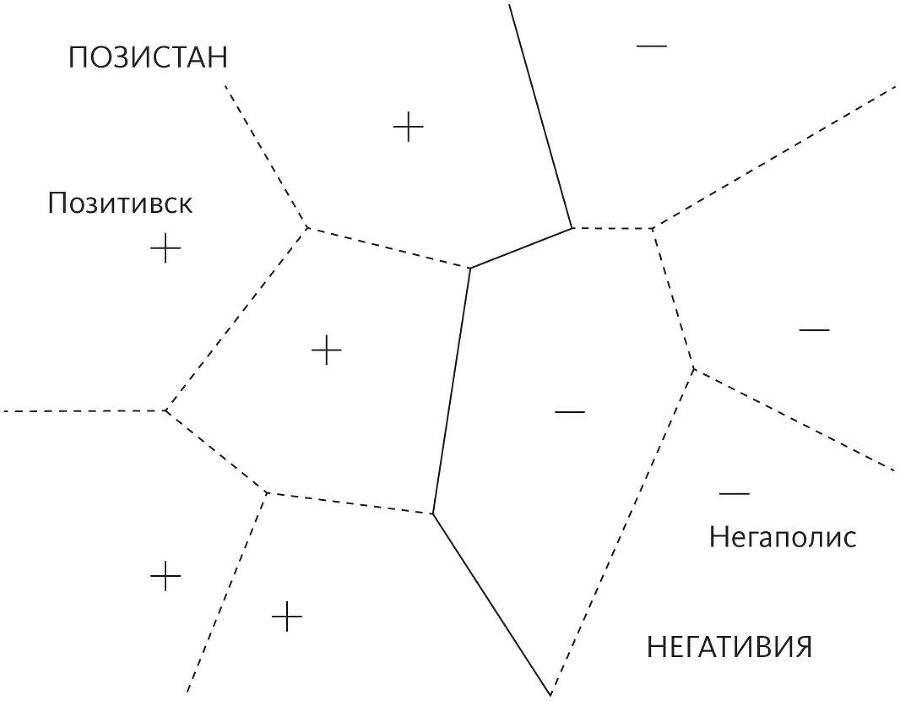
Ближайший сосед способен провести очень сложную границу, хотя он просто запоминает, где находятся города, и в соответствии с этим относит точки к тому или иному государству. «Агломерацией» города можно считать все точки, которые к нему ближе, чем к любому другому. Границы между такими агломерациями показаны на рисунке пунктиром. Теперь и Позистан, и Негативия — просто объединение агломераций всех городов этих стран. В отличие от этого алгоритма, деревья решений (например) способны лишь проводить границы, проходящие попеременно с севера на юг и с востока на запад, что, вероятно, будет намного худшим приближением настоящей границы. Таким образом, хотя алгоритмы на основе дерева решений будут изо всех сил стараться за время обучения определить, где проходит граница, победит «ленивый» метод ближайшего соседа.
Все дело в том, что построить глобальную модель, например дерево решений, намного сложнее, чем просто одно за другим определить положение конкретных элементов запроса. Представьте себе попытку определить с помощью дерева решений, что такое лицо. Можно было бы сказать, что у лица два глаза, нос и рот, но что такое глаз и как его найти на изображении? А если человек закроет глаза? Дать надежное определение лица вплоть до отдельных пикселей крайне сложно, особенно учитывая всевозможные выражения, позы, контекст, условия освещения. Алгоритм ближайшего соседа этого не делает и срезает путь: если в базе данных изображение, больше всего похожее на то, которое загрузила Джейн, — это лицо, значит на загруженном изображении тоже лицо. Чтобы все работало, в базе данных должна найтись достаточно похожая картинка, например лицо в аналогичном положении, освещении и так далее, поэтому чем больше база данных, тем лучше. Для простой двухмерной проблемы, например угадывания границы между двумя странами, маленькой базы данных будет достаточно. Для очень сложной проблемы, например определения лиц, где цвет каждого пикселя — это измерение вариативности, понадобится огромная база данных. Сегодня такие базы существуют. Обучение с их помощью может быть слишком затратным для трудолюбивых алгоритмов, которые явно проводят границу между лицами и не-лицами, однако для ближайшего соседа граница уже скрыта в расположении точек данных и расстояниях, и единственная затрата — это время запроса.