Логический вывод в байесовских сетях не ограничен вычислением вероятностей. К нему относится и нахождение наиболее вероятного объяснения признаков, например заболевания, которое лучше всего объясняет симптомы, или слов, которые лучше всего объясняют звуки, услышанные Siri. Это не то же самое, что просто выбрать на каждом этапе самое вероятное слово, потому что слова, которые схожи по отдельности исходя из звуков, могут реже встречаться вместе, как в примере «Позови к позицию». Однако и в таких задачах срабатывают аналогичные виды алгоритмов (именно их использует большинство распознавателей речи). Самое главное, что вывод предусматривает принятие наилучших решений не только на основе вероятности разных исходов, но и с учетом соответствующих затрат (или, говоря научным языком, полезности). Затраты, связанные с проигнорированным письмом от начальника, который просит что-то сделать завтра, будут намного выше, чем затраты на ознакомление с ненужным рекламным письмом, поэтому часто целесообразно пропустить письма через фильтр, даже если они довольно сильно напоминают спам.
Беспилотные автомобили и другие роботы — показательный пример работы вероятностного вывода. Машина ездит туда-сюда, создает карту территории и все увереннее определяет свое положение. Согласно недавнему исследованию, у лондонских таксистов увеличиваются размеры задней части гиппокампа — области мозга, участвующей в создании карт и запоминании, — когда они учатся ориентироваться в городе. Наверное, здесь действуют аналогичные алгоритмы вероятностного вывода с той лишь важной разницей, что людям алкоголь, по-видимому, не помогает.
Учимся по-байесовски
Теперь, когда мы знаем, как (более-менее) решать проблему логического вывода, можно приступать к обучению байесовских сетей на основе данных, ведь для байесовцев обучение — это всего лишь очередная разновидность вероятностного вывода. Все что нужно — применить теорему Байеса, где гипотезы будут возможными причинами, а данные — наблюдаемым следствием:
P(гипотеза | данные) = P(гипотеза) × P(данные | гипотеза) / P(данные).
Гипотеза может быть сложна, как целая байесовская сеть, или проста, как вероятность, что монетка упадет орлом вверх. В последнем случае данные — это просто результат серии подбрасываний. Если, скажем, мы получили 70 орлов в сотне подбрасываний, сторонник частотного подхода оценит, что вероятность выпадения орла составляет 0,7. Это оправдано так называемым принципом наибольшего правдоподобия: из всех возможных вероятностей орлов 0,7 — то значение, при котором вероятность увидеть 70 орлов при 100 подбрасываниях максимальна. Эта вероятность — P(данные | гипотеза), и принцип гласит, что нужно выбирать гипотезу, которая ее максимизирует. Байесовцы, однако, поступают разумнее. Они говорят, что никогда точно не известно, какая из гипотез верна, и поэтому нельзя просто выбирать одну гипотезу, например значение 0,7 для вероятности выпадения орла. Надо скорее вычислить апостериорную вероятность каждой возможной гипотезы и при прогнозировании учесть все. Сумма вероятностей должна равняться единице, поэтому, если какая-то гипотеза становится вероятнее, вероятность других уменьшается. Для байесовца на самом деле не существует такого понятия, как истина: есть априорное распределение гипотез, и после появления данных оно становится апостериорным распределением по теореме Байеса. Вот и все.
Это радикальный отход от традиционных научных методов. Все равно что сказать: «Вообще, ни Коперник, ни Птолемей не правы. Давайте лучше предскажем будущие траектории планет исходя из того, что Земля вращается вокруг Солнца, а потом — что Солнце вращается вокруг Земли, а результаты усредним».
Конечно, здесь речь идет о взвешенном среднем, где вес гипотезы — это ее апостериорная вероятность, поэтому гипотеза, которая лучше объясняет данные, будет иметь большее значение. Тем не менее ученые шутят, что быть байесовцем — значит никогда не говорить, что ты хоть в чем-то уверен.
Не стоит упоминать, что постоянно таскать за собой множество гипотез вместо одной тяжело. При обучении байесовской сети приходится делать предсказания путем усреднения всех возможных сетей, включая все возможные структуры графов и все возможные параметры значений для каждой структуры. В некоторых случаях можно вычислить среднее по параметрам в замкнутой форме, но с варьирующимися структурами такого везения ждать не приходится. Остается, например, применить MCMC в пространстве сетей, перепрыгивая из одной возможной сети к другой по ходу цепи Маркова. Соедините эту сложность и вычислительные затраты с неоднозначностью байесовской идеи о том, что объективной реальности вообще не существует, и вы поймете, почему в науке последние 100 лет доминирует частотный подход.
У байесовского метода есть, однако, спасительное свойство и ряд серьезных плюсов. В большинстве случаев апостериорная вероятность практически всех гипотез чрезвычайно мала и их можно спокойно проигнорировать: даже рассмотрение одной, наиболее вероятной гипотезы обычно дает очень хорошее приближение. Представьте, что наше априорное распределение для проблемы броска монетки заключается в том, что все вероятности орлов одинаково правдоподобны. После появления результатов последовательных подбрасываний распределение будет все больше и больше концентрироваться на гипотезе, которая лучше всего согласуется с данными. Например, если h пробегает по возможным вероятностям орлов, а монета падает орлом вверх в 70 процентах случаев, получится что-то вроде:
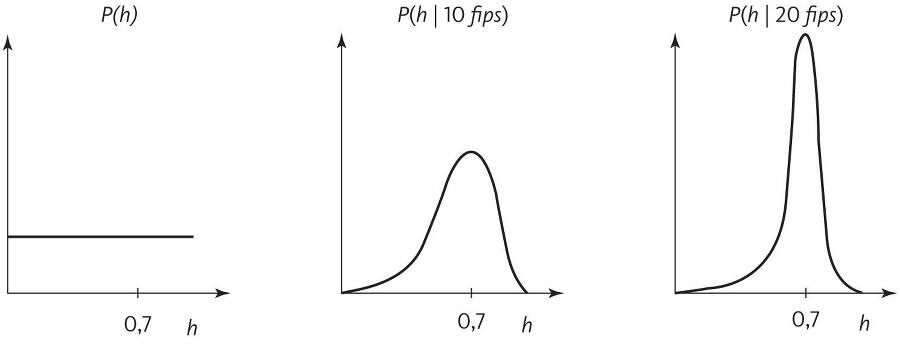
Апостериорная вероятность броска становится априорной для следующего броска, и, бросок за броском, мы все больше убеждаемся, что h = 0,7. Если просто взять одну наиболее вероятную гипотезу (в данном случае h = 0,7), байесовский подход станет довольно похож на частотный, но с одним очень важным отличием: байесовцы учитывают априорную P(гипотеза), а не просто вероятность P(данные | гипотеза). (Данные до P(данные) можно проигнорировать, потому что они одинаковы для всех гипотез и, следовательно, не влияют на выбор победителя.) Если мы хотим сделать допущение, что все гипотезы априори одинаково вероятны, байесовский подход сведется к принципу наибольшего правдоподобия. Поэтому байесовцы могут заявить сторонникам частотного подхода: «Смотрите, то, что вы делаете, — частный случай того, что делаем мы, но наши допущения хотя бы явные». А если гипотезы не одинаково правдоподобны априори, неявное допущение наибольшей правдоподобности заключается в том, что они ведут к неправильным ответам.
Это может показаться чисто теоретической дискуссией, но на самом деле ее практические последствия огромны. Если мы видели, что монету подбросили только один раз и выпал орел, принцип наибольшего правдоподобия подскажет, что вероятность выпадения орла должна быть равна единице. Это будет крайне неточно, и мы окажемся совершенно неподготовлены, если монетка упадет решкой. После многократных подбрасываний оценка станет надежнее, но во многих проблемах подбрасываний никогда не будет достаточно, как бы ни был велик объем данных. Представьте, что в наших обучающих данных слово «суперархиэкстраультрамегаграндиозно» никогда не появляется в спаме, но однажды встречается в письме про Мэри Поппинс. Спам-фильтр, основанный на наивном байесовском алгоритме с оценкой вероятности наибольшего правдоподобия, решит, что такое письмо не может быть спамом, пусть даже все остальные слова вопиют: «Спам! Спам!» Напротив, сторонник байесовского подхода дал бы этому слову низкую, но не нулевую вероятность появления в спаме, и в таком случае другие слова бы его перевесили.
Проблема лишь усугубится, если попытаться узнать и структуру байесовской сети, и ее параметры. Мы можем сделать это путем восхождения по выпуклой поверхности, начиная с пустой сети (без стрелок) и добавляя стрелки, которые больше всего увеличивают вероятность, пока ни одна из них не будет приводить к улучшению. К сожалению, это быстро вызовет очень сильное переобучение, и получится сеть, приписывающая нулевую вероятность всем состояниям, которые не появляются в данных. Байесовцы могут сделать нечто гораздо более интересное: использовать априорное распределение, чтобы закодировать экспертное знание о проблеме. Это их ответ на вопрос Юма. Например, можно разработать исходную байесовскую сеть для медицинской диагностики, опросив врачей, какие заболевания, по их мнению, вызывают те или иные симптомы, и добавить соответствующие стрелки. Это «априорная сеть», и априорное распределение может штрафовать альтернативные сети по числу стрелок, которые они в нее добавляют или убирают. Тем не менее врачам свойственно ошибаться, и данным разрешено перевесить их мнение: если рост правдоподобия в результате добавления стрелки перевешивает штраф, она будет добавлена.