Наш первый шаг к Верховному алгоритму будет на удивление простым. Как оказывается, несложно соединить много разных обучающихся алгоритмов в один, используя так называемое метаобучение. Его используют Netflix, Watson, Kinect и бесчисленное множество других программ, и это одна из самых мощных стрел в колчане машинного обучения. Это также ступенька к более глубокому объединению алгоритмов, о котором мы поговорим дальше.
Из многих моделей — одна
Вот вам задача: за 15 минут соедините деревья решений, многослойные перцептроны, системы классификации, наивный байесовский алгоритм и метод опорных векторов в один алгоритм, который будет обладать лучшими свойствами каждого из элементов. Быстро: что вы можете сделать? Очевидно, что детали отдельных алгоритмов в нем использовать нельзя: просто не хватит времени. Давайте попробуем следующее решение. Представьте, что каждый из обучающихся алгоритмов — эксперт в комитете. Каждый внимательно рассматривает подлежащий классификации случай — какой диагноз поставить пациенту? — и уверенно дает прогноз. Вы сами — не эксперт, а председатель этого комитета, и ваша работа — объединить рекомендации в окончательное решение. В руках у вас, по сути, новая проблема классификации, где вместо симптомов пациентов входом будет мнение экспертов, но машинное обучение можно применить к этой проблеме таким же образом, как эксперты применяли его к исходным данным. Такой подход называется метаобучением, потому что это обучение обучающимся алгоритмам. Сам метаалгоритм может быть любым, от дерева решений до простого взвешенного голосования. Чтобы узнать веса или дерево решений, атрибуты каждого исходного примера заменяются прогнозами обучающихся алгоритмов. Алгоритмы, которые часто предсказывают правильный класс, получают высокий вес, а неточные будут чаще игнорироваться. В случае дерева решений использование обучающегося алгоритма может зависеть от предсказаний других алгоритмов. Как бы то ни было, чтобы получить прогноз алгоритма для данного примера, сначала надо применить алгоритм к исходному обучающему набору, исключив этот пример, и использовать получившийся в результате классификатор, иначе есть риск, что в комитете будут доминировать алгоритмы, страдающие переобучением, поскольку они могут предсказывать правильный класс, просто его запоминая. Победитель Netflix Prize использовал метаобучение для соединения сотен алгоритмов машинного обучения. Watson использует его для выбора окончательного ответа из имеющихся кандидатов. Нейт Сильвер соединяет результаты опросов аналогичным образом, чтобы спрогнозировать результаты выборов.
Этот тип метаобучения называют стэкингом, а придумал его Дэвид Уолперт, автор теоремы «Бесплатных обедов не бывает», с которой мы познакомились в главе 3. Еще более простой метаалгоритм — это бэггинг, изобретенный статистиком Лео Брейманом. Бэггинг генерирует случайные вариации обучающего набора путем перевыборки, применяет к каждой вариации один и тот же алгоритм машинного обучения и соединяет результаты путем голосования. Это нужно для того, чтобы уменьшить дисперсию: объединенная модель гораздо менее чувствительна к капризам данных, чем любая единичная, поэтому это замечательно легкий способ улучшить точность. Если модели — деревья решений и мы будем еще больше варьировать их, формируя случайный поднабор атрибутов в каждом дереве, получится так называемый случайный лес. Случайный лес — это один из самых точных имеющихся классификаторов. Kinect компании Microsoft использует его для определения ваших действий и регулярно выигрывает соревнования по машинному обучению.
Один из самых сообразительных метаалгоритмов — бустинг, созданный двумя теоретиками обучения, Йоавом Фройндом и Робом Шапире. Бустинг не соединяет разные обучающиеся алгоритмы, а раз за разом применяет к данным один и тот же классификатор, используя новую модель, чтобы исправить ошибки предыдущей путем присвоения весов обучающим примерам. Вес каждого неправильно классифицированного примера увеличивается после каждого цикла обучения, заставляя последующие циклы больше сосредоточиваться на нем. Название «бустинг» — усиление — связано с тем, что этот процесс может резко улучшить классификатор, который незначительно, но стабильно лучше случайного угадывания, и сделать его почти идеальным.
Метаобучение исключительно успешно, но это не очень глубокий способ объединения моделей. Кроме того, он дорог и требует многократного обучения, а соединенные модели могут получиться довольно непрозрачными. («Я уверен, что у вас рак предстательной железы, потому что на это указывают дерево решений, генетический алгоритм и наивный байесовский классификатор, хотя многослойный перцептрон и метод опорных векторов с этим не согласны».) Более того, все объединенные модели — на самом деле просто одна хаотичная модель. Нельзя ли получить единый обучающийся алгоритм, который делает то же самое? Можно.
Верховный алгоритм
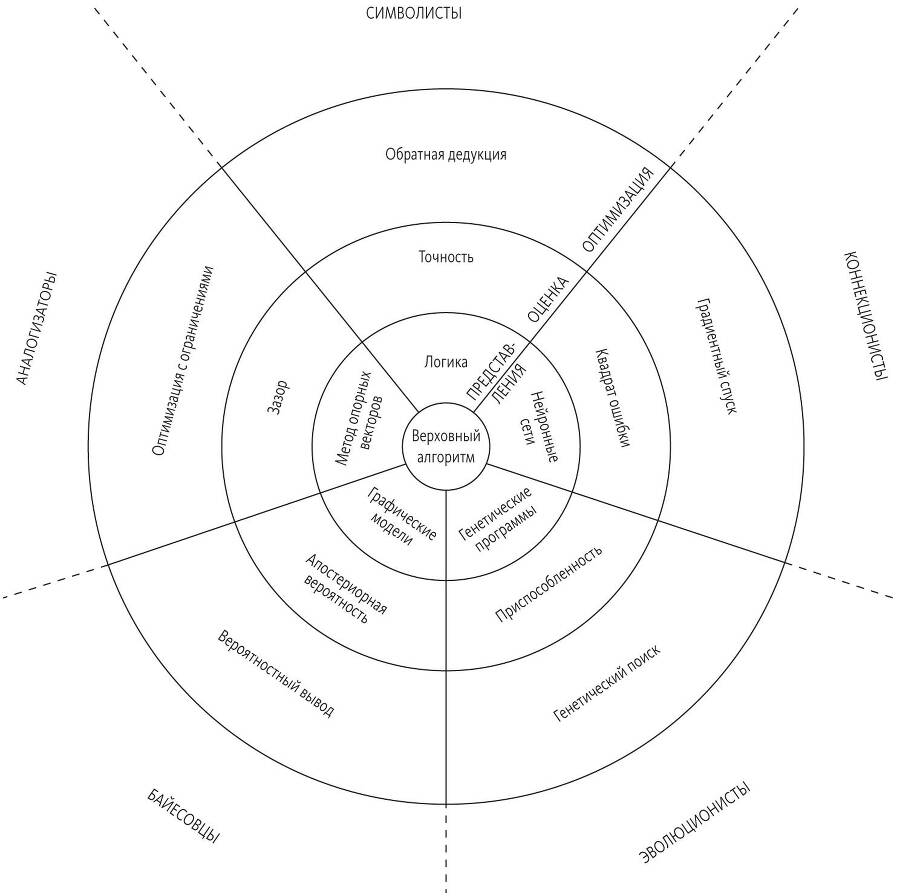
Наш объединенный обучающийся алгоритм, наверное, лучше всего ввести с помощью аллегории. Если представить себе машинное обучение в виде континента, разделенного на территории пяти «племен», то Верховный алгоритм будет столицей, расположенной в уникальном месте, где сходятся их границы. Вы приближаетесь к городу издалека и видите, что состоит он из трех концентрических, обнесенных стеной колец. Внешний и без сомнения самый широкий круг — это Городок оптимизации. Дома здесь — алгоритмы всех форм и размеров. Одни только строятся, и вокруг них суетятся местные жители, другие сияют свежестью, третьи выглядят старыми и заброшенными. Выше на холме стоит Цитадель оценки. Из ее особняков и дворцов постоянно исходят приказы алгоритмам внизу. На самой вершине в небо взлетает Башня представлений. Здесь живут отцы города. Их непреложные законы определяют, что можно сделать, а чего нельзя, и не только в городе, но и на всем континенте. На вершине центральной, самой высокой башни развевается флаг Верховного алгоритма: красно-черный, с пятиконечной звездой, внутри которой надпись, но вы пока не можете ее разобрать.
Город разделен на пять секторов, по одному для каждого из пяти «племен». Сектора простираются от Башни представлений вниз, к внешним стенам, опоясывающим Башню, группы дворцов в Цитадели оценки и улицы и дома Городка оптимизации, над которой они возвышаются. Пять секторов и три кольца делят город на 15 районов — 15 форм, 15 кусочков мозаики, которую вам надо сложить:
Вы пристально вглядываетесь в карту, пытаясь расшифровать ее секрет. Пятнадцать кусочков довольно точно подходят друг к другу, но вам надо понять, как они соединяются, чтобы получить всего три элемента: представление, оценку и оптимизацию Верховного алгоритма. Каждый обучающийся алгоритм состоит из этих элементов, но они разнятся от «племени» к «племени».
Представления — формальный язык, на котором алгоритм машинного обучения выражает свои модели. Формальный язык символистов — логика, частные случаи которой — правила и деревья решений. Для коннекционистов это нейронные сети. Для эволюционистов — генетические программы, включая системы классификации. Для байесовцев — графические модели, общий термин для байесовских и марковских сетей. Для аналогизаторов — частные случаи, возможно, с весами, как в методе опорных векторов.
Элемент оценки — функция присвоения баллов, которая говорит, насколько хороша модель. Символисты используют точность и информационный выигрыш. Коннекционисты — непрерывное измерение погрешности, например квадрат ошибки, который представляет собой сумму квадратов различий между предсказанными и истинными значениями. Байесовцы применяют апостериорную вероятность, аналогизаторы (как минимум специалисты по методу опорных векторов) — зазор. В дополнение к оценке того, насколько хорошо модель подходит к данным, все «племена» учитывают другие желательные свойства, например простоту модели.