Для нас самое главное то, что S-образные кривые ведут к новому решению проблемы коэффициентов доверия. Раз Вселенная — это симфония фазовых переходов, давайте смоделируем ее с помощью фазового перехода. Именно так поступает головной мозг: подстраивает систему фазовых переходов внутри к аналогичной системе снаружи. Итак, давайте заменим ступенчатую функцию перцептрона сигмоидой и посмотрим, что произойдет.
Альпинизм в гиперпространстве
В алгоритме перцептрона сигнал ошибки действует по принципу «все или ничего»: либо правильно, либо неправильно. Негусто, особенно в случае сетей из многих нейронов. Можно понять, что ошибся нейрон на выходе (ой, это была не ваша бабушка?), но как насчет какого-то нейрона в глубинах мозга? И вообще, что значат правота и ошибка для глубинного нейрона? Однако если выход нейрона непрерывный, а не бинарный, картина меняется. Прежде всего мы можем оценить, насколько ошибается выходной нейрон, по разнице между получаемым и желаемым выходом. Если нейрон должен искрить активностью («Ой, бабушка! Привет!») и он немного активен, это лучше, чем если бы он не срабатывал вовсе. Еще важнее то, что теперь можно распространить эту ошибку на скрытые нейроны: если выходной нейрон должен быть активнее и с ним связан нейрон A, то чем более активен нейрон A, тем больше мы должны усилить соединение между ними. Если A подавляется нейроном B, то B должен быть менее активным и так далее. Благодаря обратной связи от всех нейронов, с которыми он связан, каждый нейрон решает, насколько больше или меньше надо активироваться. Это, а также активность его собственных входных нейронов диктует ему, усиливать или ослаблять соединения с ними. Мне надо быть активнее, а нейрон B меня подавляет? Значит, его вес надо снизить. А нейрон C очень активен, но его соединение со мной слабое? Усилим его. В следующем раунде нейроны-«клиенты», расположенные дальше в сети, подскажут, насколько хорошо я справился с задачей.
Всякий раз, когда «сетчатка» обучающегося алгоритма видит новый образ, сигнал распространяется по всей сети, пока не даст выход. Сравнение полученного выхода с желаемым выдает сигнал ошибки, который затем распространяется обратно через все слои и достигает сетчатки. На основе возвращающегося сигнала и вводных, полученных во время прохождения вперед, каждый нейрон корректирует веса. По мере того как сеть видит все новые и новые изображения вашей бабушки и других людей, веса постепенно сходятся со значениями, которые позволяют отличить одно от другого. Метод обратного распространения ошибки, как называется этот алгоритм, несравнимо мощнее перцептрона. Единичный нейрон может найти только прямую линию, а так называемый многослойный перцептрон — произвольно запутанные границы, при условии что у него есть достаточно скрытых нейронов. Это делает обратное распространение ошибки верховным алгоритмом коннекционистов.
Обратное распространение — частный случай стратегии, очень распространенной в природе и в технологии: если вам надо быстро забраться на гору, выбирайте самый крутой склон, который только найдете. Технический термин для этого явления — «градиентное восхождение» (если вы хотите попасть на вершину) или «градиентный спуск» (если смотреть на долину внизу). Бактерии умеют искать пищу, перемещаясь согласно градиенту концентрации, скажем, глюкозы, и убегать от ядов, двигаясь против их градиента. С помощью градиентного спуска можно оптимизировать массу вещей, от крыльев самолетов до антенных систем. Обратное распространение — эффективный способ такой оптимизации в многослойном перцептроне: продолжайте корректировать веса, чтобы снизить возможность ошибки, и остановитесь, когда станет очевидно, что корректировки ничего не дают. В случае обратного распространения не надо разбираться, как с нуля корректировать вес каждого нейрона (это было бы слишком медленно): это можно делать слой за слоем, настраивая каждый нейрон на основе уже настроенных, с которыми он соединен. Если в чрезвычайной ситуации вам придется выбросить весь инструментарий машинного обучения и спасти что-то одно, вы, вероятно, решите спасти градиентный спуск.
Так как же обратное распространение решает проблему машинного обучения? Может быть, надо просто собрать кучу нейронов, подождать, пока они наколдуют все, что надо, а потом по дороге в банк заехать получить Нобелевскую премию за открытие принципа работы мозга? К сожалению, в жизни все не так просто. Представьте, что у вашей сети только один вес; зависимость ошибки от него показана на этом графике:
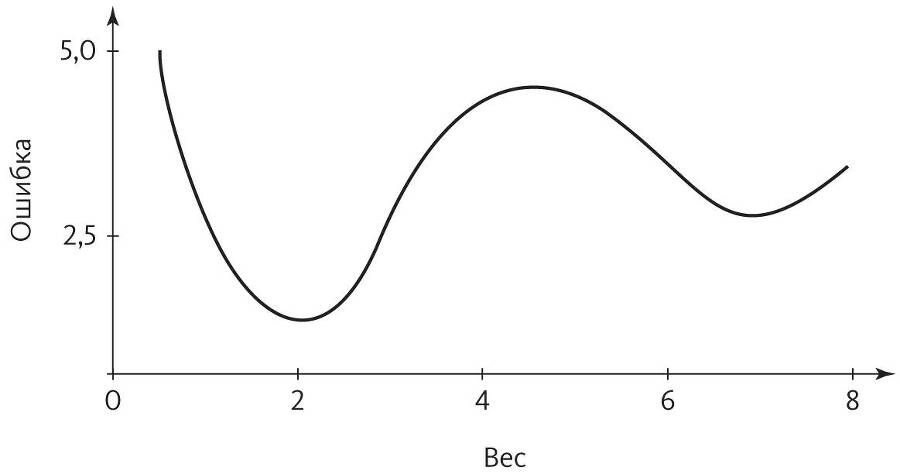
Оптимальный вес, в котором ошибка самая низкая, — это 2,0. Если сеть начнет работу, например, с 0,75, обратное распространение ошибки за несколько шагов придет к оптимуму, как катящийся с горки мячик. Однако если начать с 5,5, мы скатимся к весу 7,0 и застрянем там. Обратное распространение ошибки со своими поэтапными изменениями весов не сможет найти глобальный минимум ошибки, а локальные минимумы могут быть сколь угодно плохими: например, бабушку можно перепутать со шляпой. Если вес всего один, можно перепробовать все возможные значения c шагом 0,01 и таким образом найти оптимум. Но когда весов тысячи, не говоря уже о миллионах или миллиардах, это не вариант, потому что число точек на сетке будет увеличиваться экспоненциально с числом весов. Глобальный минимум окажется скрыт где-то в бездонных глубинах гиперпространства — ищи иголку в стоге сена.
Представьте, что вас похитили, завязали глаза и бросили где-то в Гималаях. Голова раскалывается, с памятью не очень, но вы твердо знаете, что надо забраться на вершину Эвереста. Как быть? Вы делаете шаг вперед и едва не скатываетесь в ущелье. Переведя дух, вы решаете действовать систематичнее и осторожно ощупываете ногой почву вокруг, чтобы определить самую высокую точку. Затем вы робко шагаете к ней, и все повторяется. Понемногу вы забираетесь все выше и выше. Через какое-то время любой шаг начинает вести вниз, и вы останавливаетесь. Это градиентное восхождение. Если бы в Гималаях существовал один Эверест, причем идеальной конической формы, все было бы прекрасно. Но, скорее всего, место, где все шаги ведут вниз, будет все еще очень далеко от вершины: вы просто застрянете на каком-нибудь холме у подножья. Именно это происходит с обратным распространением ошибки, только на горы оно взбирается в гиперпространстве, а не в трехмерном пространстве, как наше. Если ваша сеть состоит из одного нейрона и вы будете шаг за шагом подниматься к наилучшим весам, то придете к вершине. Но в многослойном перцептроне ландшафт очень изрезанный — поди найди высочайший пик.
Отчасти поэтому Минский, Пейперт и другие исследователи не понимали, как можно обучать многослойные перцептроны. Они могли представить себе замену ступенчатых функций S-образными кривыми и градиентный спуск, но затем сталкивались с проблемой локальных минимумов ошибки. В то время ученые не доверяли компьютерным симуляциям и требовали математических доказательств работоспособности алгоритма, а для обратного распространения ошибки такого доказательства не было. Но, как мы уже видели, в большинстве случаев локального минимума достаточно. Поверхность ошибки часто похожа на дикобраза: много крутых пиков и впадин, и на самом деле неважно, найдем ли мы самую глубокую, абсолютную впадину — сойдет любая. Еще лучше то, что локальный минимум бывает даже предпочтительнее, потому что он меньше подвержен переобучению, чем глобальный.
Гиперпространство — обоюдоострый меч. С одной стороны, чем больше количество измерений, тем больше места для очень сложных поверхностей и локальных экстремумов. С другой стороны, чтобы застрять в локальном экстремуме, надо застрять во всех измерениях, а во многих одновременно застрять сложнее, чем в трех. В гиперпространстве есть перевалы, проходящие через всю (гипер)местность, поэтому с небольшой помощью со стороны человека обратное распространение ошибки зачастую способно найти путь к идеально хорошему набору весов. Может быть, это не уровень моря, а только легендарная долина Шангри-Ла, но на что жаловаться, если в гиперпространстве миллионы таких долин и к каждой ведут миллиарды перевалов?