Обратите внимание, что обучение с подкреплением сталкивается с той же дилеммой изучения–применения, с которой мы познакомились в главе 5: чтобы максимизировать награды, вы, естественно, всегда хотите выбирать действие, ведущее к состоянию с наибольшим значением, но это не дает открыть потенциально большие награды в других местах. Алгоритмы обучения с подкреплением решают эту проблему, иногда выбирая лучшее действие, а иногда — случайное. (В головном мозге, кажется, для этого есть даже «генератор шумов».) На ранних этапах, когда можно получить много информации, имеет смысл больше изучать. Когда территория известна, лучше будет сосредоточиться на применении знания. Люди делают это на протяжении жизни: дети учатся, а взрослые используют (кроме ученых, которые похожи на вечных детей). Детская игра намного серьезнее, чем может показаться: если эволюция создала существо, которое в первые несколько лет своей жизни беспомощно и только обременяет родителей, такая расточительность должна давать большие преимущества. По сути, обучение с подкреплением — своего рода ускоренная эволюция, которая позволяет попробовать, отбросить и отточить действия в течение одной жизни, а не многих поколений, и по этим меркам оно крайне эффективно.
Начало серьезным исследованиям обучения с подкреплением положили в 1980-х годах работы Рича Саттона и Энди Барто из Массачусетского университета. Ученые чувствовали, что обучение в очень большой степени зависит от взаимодействия со средой, а контролирующие алгоритмы этого не улавливают, и нашли вдохновение в психологии обучения животных. Саттон продолжил заниматься этой темой и стал ведущим сторонником обучения с подкреплением. Еще один ключевой шаг был сделан в 1989 году, когда Крис Уоткинс из Кембриджа, которого изначально мотивировали экспериментальные наблюдения за обучением детей, пришел к современной формулировке обучения с подкреплением как оптимального контроля в неизвестной среде.
Тем не менее алгоритмы обучения с подкреплением, которые мы видели до сих пор, не очень реалистичны, потому что не знают, что делать в данном состоянии, если раньше в нем не были, а в реальном мире не бывает двух совершенно одинаковых ситуаций. Нужно уметь делать обобщения, выводя из посещенных состояний новые. К счастью, этому мы уже научились: достаточно просто обернуть обучение с подкреплением вокруг одного из алгоритмов обучения с учителем, с которыми мы познакомились раньше, например многослойного перцептрона. Теперь нейронная сеть будет предсказывать значение состояния, а сигналом ошибки для обратного распространения станет разница между предсказанными и наблюдаемыми значениями. Но есть и проблема. В обучении с учителем целевое значение состояния всегда одно и то же, а в обучении с подкреплением оно продолжает меняться в силу обновлений соседних состояний, поэтому обучение с подкреплением и обобщением часто не умеет приходить к стабильному решению, если только обучающийся алгоритм внутри не простейший, например линейная функция. Несмотря на это, обучение с подкреплением в сочетании с нейронными сетями принесло ряд заметных успехов. Одним из первых достижений стала программа, играющая в нарды на уровне человека. Позже алгоритм обучения с подкреплением, разработанный в лондонском стартапе DeepMind, победил хорошего игрока в Pong и другие простые аркады. Для прогнозирования ценности действий на основе «сырых» пикселей экрана игровой приставки в нем использовалась глубокая сеть. Благодаря непрерывному зрению, обучению и контролю система имела как минимум поверхностное сходство с искусственным мозгом. Неудивительно, что Google заплатила за DeepMind полмиллиарда долларов, хотя у компании не имелось ни продукции, ни выручки и сотрудников было немного.
Кроме компьютерных игр, ученые использовали обучение с подкреплением для управления гимнастами — человечками из палочек, парковки задним ходом, пилотирования вертолетов вверх ногами, управления автоматическими телефонными диалогами, выделения каналов в сетях сотовой связи, вызова лифта, составления расписаний загрузки космического челнока и многих других целей. Обучение с подкреплением повлияло на психологию и нейробиологию. В мозге оно осуществляется благодаря нейромедиатору дофамину, который позволяет распространить разницу между ожидаемыми и фактическими наградами. Обучением с подкреплением можно объяснить условные рефлексы по Павлову, и, в отличие от бихевиоризма, такой подход допускает, что у животных есть внутренние психические состояния. Этот вид обучения используют пчелы-сборщицы и мыши, ищущие сыр в лабиринте. Человеческая повседневность — это поток почти незаметных чудес, которые возможны отчасти благодаря обучению с подкреплением. Вы встаете, одеваетесь, завтракаете, едете на работу, и все это автоматически, думая о чем-то другом. Где-то в глубине обучение с подкреплением постоянно дирижирует процессом и тонко настраивает удивительную симфонию движений. Элементы обучения с подкреплением, также называемые привычками, составляют большую часть наших действий: проголодался — идешь к холодильнику и берешь что-нибудь перекусить. Как показал Чарльз Дахигг в книге The Power of Habit[103], понимание и управление этим циклом намеков, рутинных действий и наград — ключ к успеху не только для отдельных людей, но и для бизнеса, и даже для общества в целом.
Из всех отцов обучения с подкреплением самый большой энтузиаст этого метода — Рич Саттон. Для него обучение с подкреплением — Верховный алгоритм, и решение этой проблемы равноценно решению проблемы искусственного интеллекта. C другой стороны, Крис Уоткинс не удовлетворен этим подходом и видит много того, что могут делать дети и не могут алгоритмы обучения с подкреплением: решать проблемы, решать их лучше после какого-то количества попыток, планировать, усваивать все более абстрактное знание. К счастью, для этих высокоуровневых способностей у нас тоже есть обучающиеся алгоритмы, и самый важный из них — алгоритм образования фрагментов, или chunking.
Повторенье — мать ученья
Учиться — значит становиться лучше с практикой. Сейчас вы, может быть, и не помните, как сложно было научиться завязывать шнурки. Сначала не получалось вообще ничего, хотя вам было целых пять лет. Потом шнурки, наверное, развязывались быстрее, чем вы успевали их завязать. Но постепенно вы научились завязывать их быстрее и лучше, пока движения не стали совершенно автоматическими. То же самое происходило, например, с ползанием, ходьбой, бегом, ездой на велосипеде и вождением автомобиля, чтением, письмом и арифметикой, игрой на музыкальных инструментах и занятиями спортом, приготовлением пищи и работой на компьютере. По иронии судьбы, больше всего пользы приносит самое болезненное обучение: поначалу сложен каждый шаг, вы раз за разом терпите неудачу, и, даже если получается, результаты не впечатляют. Освоив замах в гольфе или подачу в теннисе, можно годами оттачивать мастерство, но все эти годы дадут меньше, чем первые несколько недель. С практикой вы становитесь искуснее, но скорость не постоянна: сначала улучшения приходят быстро, потом все медленнее, а затем совсем замедляются. Неважно, осваиваете вы игры или учитесь играть на гитаре: кривая зависимости улучшения результатов от времени — насколько хорошо вы что-то делаете и сколько времени это занимает — имеет очень характерную форму:
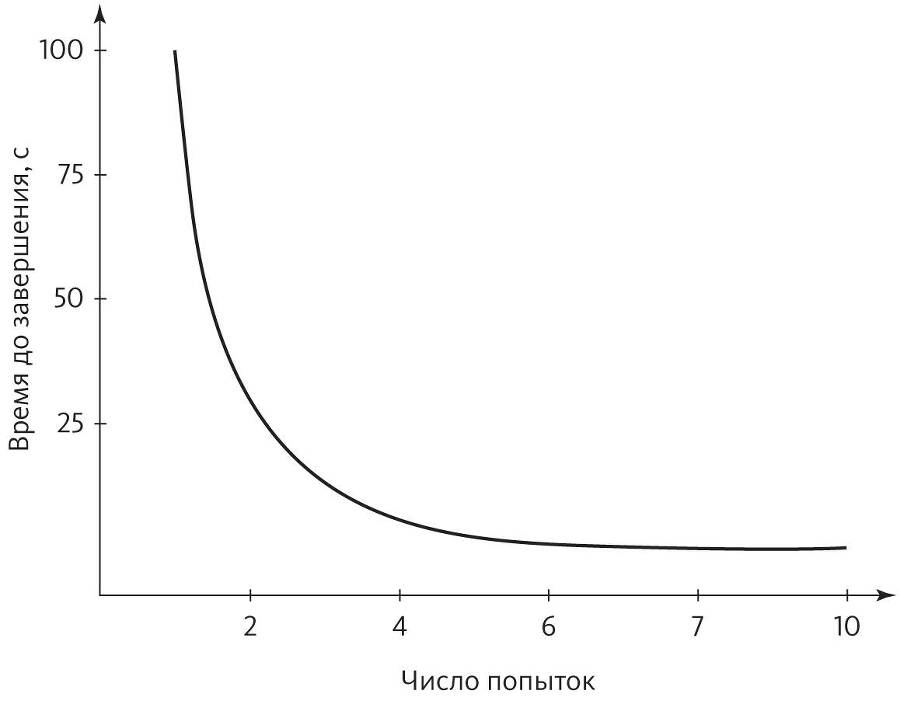
Этот тип кривой называют степенным законом, потому что изменение эффективности зависит от возведения времени в какую-то отрицательную степень. Например, на рисунке выше время до завершения пропорционально числу попыток, возведенному в минус вторую степень (или, эквивалентно, единице, разделенной на квадрат числа попыток). Практически все человеческие навыки следуют степенному закону, и разным умениям соответствуют разные степени. (А вот Windows с практикой не ускоряется — Microsoft есть над чем поработать.)