Каким же образом следует подходить к вопросу изучения эволюции языка? Если взять биологию, то лучший способ понять пути развития эволюции состоит в изучении окаменелостей. Однако находить ископаемые довольно сложно. Для этого требуется сочетать тщательное планирование и хорошую стратегию. С точки зрения успешного поиска окаменелостей мало кто может сравниться с Натаном Мирвольдом, возможно, величайшим охотником на динозавров в своем поколении (этот человек множества талантов также стал одним из основателей Microsoft Research и написал книгу о современной кухне) [45]. И дело вовсе не в том, что Мирвольду везет больше, чем другим, и что каждый беловатый камень, который он в своих экспедициях берет в руки, оказывается черепом динозавра Tyrannosaurus rex. Мирвольд и его команда используют подробные геологические карты, спутниковые фотографии и свою собственную программу экологического анализа. Все это помогает им понять, где заниматься поисками и где белые камни действительно имеют шансы оказаться окаменелостями. В результате, начиная с 1999 года, им удалось обнаружить десять скелетов тираннозавров – при том что за 90 предшествовавших лет было найдено всего 18 таких скелетов. Выражаясь словами самого Мирвольда, «мы господствуем на рынке T. rex».
Мы решили господствовать на рынке лингвистических окаменелостей. Подобно тому, как окаменелости эпохи динозавров рассказывают нам о биологической эволюции, лингвистические окаменелости помогают нам понять, как развивается язык. Однако для того, чтобы повысить шансы на успех в поиске таких окаменелостей, нам был необходим некий руководящий принцип, помогающий понять, где именно копать. И оказалось, что нужный нам инструмент был создан 80 лет назад человеком, который, как и мы сами, искренне любил считать.
1937: Одиссея данных
Джордж Кингсли Ципф работал в Гарварде в 1930-е и 1940-е годы, возглавляя отделение германской литературы. У него имелась комбинация довольно редких навыков – с одной стороны, он был гуманитарием, а с другой – разбирался в количественных измерениях.
Будучи филологом, Ципф проводил кучу времени в размышлениях о словах. Ему казалось вполне очевидным, что не все слова созданы равными. Определенный артикль the используется в английском языке постоянно, но мы редко слышим слово quiescence («неподвижность»). Ципф счел этот дисбаланс довольно странным и захотел понять, в чем дело.
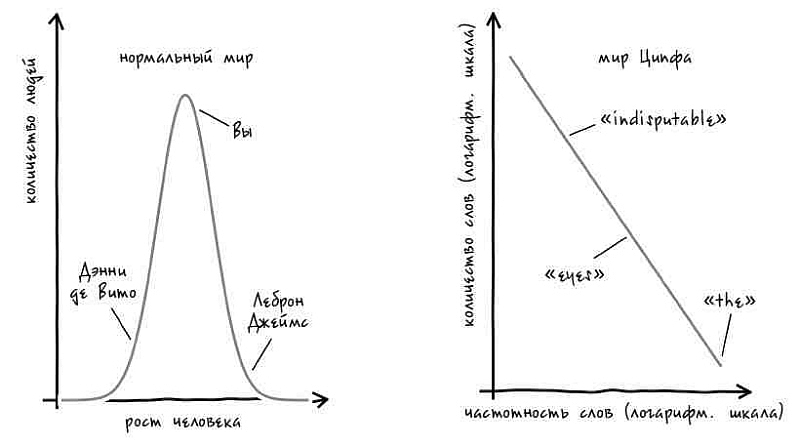
Понять суть проблемы можно вот как. Представьте себе, что английский язык – это страна, в которой каждое слово является гражданином. А еще представьте, что высота каждого слова-гражданина пропорциональна частоте его употребления – the будет гигантом, а quiescence – карликом[46]. Каково было бы жить среди людей со столь странным ростом? Именно такой «детский» вопрос и заинтересовал Ципфа.
Чтобы представить такой мир наглядно, Ципфу пришлось бы провести перепись всех слов и посчитать, сколько раз использовалось каждое из них. В наши дни это легко и просто сделать с помощью компьютера (программы из одной строки) [47]. Именно поэтому для написания концептуальной книги Legendary, Lexical, Loquacious Love не требовались десятилетия. Но в 1937 году таких возможностей не было. Современные компьютеры просто не существовали, а словом computer («компьютер») обозначался человек, занимавшийся арифметическими вычислениями[48].
Для подсчета слов Ципфу пришлось бы пойти проверенным путем – вручную записывать каждый случай появления того или иного слова в тексте. Разумеется, это была бы невероятно скучная работа.
Думается, что он испытал восторг, узнав о работе Майлса Л. Хенли[49]. Хенли, большой поклонник «Улисса», опубликовал результат кропотливой и героической работы, которой дал довольно скучное название Word Index to James Joyce’s Ulysses («Индекс слов в книге Джеймса Джойса „Улисс“»). Эта книга (представлявшая собой то, что ученые называют «конкорданс») предлагала исследователям «Улисса» и прочим энтузиастам список всех слов книги. Мало какая другая книга вызвала бы у Ципфа больший интерес. Теперь для того, чтобы разобраться со своей первоначальной задачей, ему нужно было взять индекс Хенли и посчитать, какова длина каждой из статей[50]. Работа стала на порядок проще.
Обратите внимание, что Ципф намного опередил свое время в понимании того, что только начинают понимать ученые наших дней, – как логически анализировать информацию. Ципф умело переформулировал важные для себя вопросы в свете доступных ему данных. Вместо того чтобы заняться неразрешимой проблемой подсчета всех слов, он сфокусировался на вполне решаемой проблеме подсчета слов в книге «Улисс». И если бы он был жив в наши дни, то оказался бы у дверей Google в тот же самый момент, когда компания объявила о своем проекте по оцифровке книг.
Вооружившись индексом Хенли, Ципф проранжировал слова в «Улиссе» по частоте употребления[51]. Первое место занял определенный артикль the, использованный 14 877 раз – то есть он представлял собой каждое восемнадцатое слово. Десятым по частоте оказалось слово I («я») с 2653 случаями употреблений. Слово say, встречавшееся в книге 265 раз, оказалось на сотой позиции. Слово step с 26 случаями употреблений заняло в рейтинге Ципфа тысячное место. А чтобы оказаться на десятитысячной позиции, слову indisputable («бесспорный») было достаточно появиться в тексте всего два раза.
Изучая получившийся список, Ципф заметил кое-что любопытное – а именно обратную связь между позицией слова и частотой его использования. Если номер позиции слова был в 10 раз выше – пятисотое место вместо пятидесятого, – то оно встречалось в 10 раз реже. Таким образом his («его»), оказавшееся на восьмом месте с 3326 упоминаниями, встречается в 10 раз чаще, чем слово eyes («глаза») (восьмидесятая позиция, 330 случаев употреблений). Иными словами, можно было сказать, что редких слов гораздо больше, чем можно было ожидать. В «Улиссе» лишь 100 слов используется более 2653 раз. Однако в книге есть сто слов, использующихся более 265 раз, тысяча слов, использующихся более 26 раз, и так далее.
Кроме того, как вскоре обнаружил Ципф, это было характерно не только для слов в «Улиссе» Джойса. Такая же закономерность проявлялась в словах из газет, текстов, написанных на китайском языке и латыни, и практически во всех остальных информационных источниках, к которым он обращался. Это открытие, называемое в наши дни законом Ципфа, оказалось универсальным организующим принципом для всех известных языков[52].
Мир глазами Ципфа
До Ципфа ученые полагали, что большинство вещей, поддающихся измерению, ведут себя подобно человеческому росту.
Рост человека не очень сильно варьируется. Рост 90% жителей США составляет от 155 см до 185 см. Разумеется, рост некоторых особенно высоких баскетболистов достигает 220 см и выше, а рост самого низкого взрослого человека в мире составляет менее 62 см. Однако подобные случаи встречаются крайне редко. Но даже с учетом этих крайностей самые высокие люди всего в 4–5 раз выше самых низкорослых[53]. У математиков имеется особый термин для описания распределения такого рода, при котором значения настолько тесно группируются вокруг среднего значения. Подобное часто встречающееся распределение называется «нормальным». До Ципфа люди считали, что мы живем в нормальном мире, где нормальным оказывалось бы все окружающее.