Эти глаголы до сих пор описываются как неправильные во многих учебниках. Однако в реальности прежде всемогущий альянс постепенно распадается[75]. Два участника группы, глаголы spell и learn, стали правильными к 1800 году. С тех пор правильными стали еще четыре глагола – burn, smell, spell и spill.
Результаты дают основания полагать, что эта тенденция зародилась в Соединенных Штатах. Однако затем она распространилась и на Великобританию, где каждый год количество людей, равное числу жителей Кембриджа, начинает использовать форму burned вместо burnt [76]. По сути, в наши дни выжить в числе неправильных глаголов этой группы удалось лишь форме dwelt. Так что студент зря описывал свою злость на курсы английского языка словом burnt. На самом деле правильное слово для обозначения его злости уже звучит как burned.
Глава 3
Кабинетные лексикограферологи
К 2007 году работа с неправильными глаголами убедила нас в том, что подсчет слов позволяет отслеживать определенные, постепенно происходящие культурные изменения. Однако отслеживать неправильные глаголы просто, поскольку они встречаются достаточно часто. К примеру, слово went (прошедшее время от go – «идти») появляется примерно один раз через каждые 5000 слов или примерно один раз на 20 страниц. Вы постоянно видите его в каждой прочитанной книге. Но как только человек начинает заниматься исследованием чего-то, кроме неправильных глаголов и изучает более сложные проблемы, он рано или поздно попадает на темную сторону закона Ципфа. Часто встречающихся слов (типа went) довольно мало. Подавляющее большинство слов встречается значительно реже.
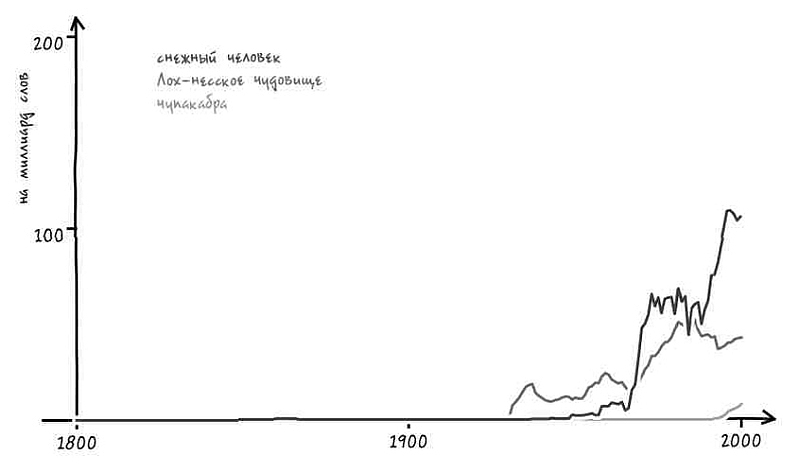
Давайте предположим, что мы пытаемся найти кое-что более загадочное, вроде снежного человека, известного в английском языке под именем Sasquatch[77]. Пугливый Sasquatch появляется в английских текстах примерно один раз на каждые 10 миллионов слов, или примерно один раз на каждую сотню книг. Выслеживать Sasquatch гораздо сложнее, чем любой привычный неправильный глагол.
Тем не менее найти Sasquatch не очень сложно. Куда реже нам встречается Loch Ness monster («Лох-несское чудовище») – лишь одно появление на каждые 200 книг. Но если вы действительно хотите протестировать, насколько ловко отыскиваете загадочных созданий, попробуйте найти Chupacabra («чупакабру») [78]. Этого кровососа впервые заметили в 1995 году в Пуэрто-Рико. О нем неизвестно практически ничего. Но мы можем сказать, что Chupacabra встречается значительно реже Sasquatch. Ее можно встретить лишь один раз на каждые 150 миллионов слов (или около 1500 книг). Невероятно начитанный человек может встретить слово Chupacabra всего один раз за всю свою жизнь. Так что вот вам еще одно упоминание – Chupacabra. Цените этот момент.
Для отслеживания столь редких слов нам нужно было получить доступ к большим данным – к миллионам книг. И для этого мы могли отправиться лишь в одно место.
Психология 29-летнего миллиардера
В 2002 году дела в компании Google шли отлично, и у одного из ее основателей, Ларри Пейджа, появилось немного свободного времени. Что было делать? В конечном счете миссия Google состояла в том, чтобы «упорядочить всю имеющуюся в мире информацию», и Пейдж знал, что в книгах информации содержится очень много.
Он задумался: насколько сложно превратить физическую библиотеку в цифровую, способную храниться в киберпространстве? Ответа на этот вопрос не знал никто. Поэтому Пейдж и Марисса Майер (работавшая тогда продукт-менеджером в Google, а в 2013 году бывшая исполнительным директором компании Yahoo!) решили провести эксперимент. Вооружившись метрономом, они принялись переворачивать страницы 300-страничной книги в определенном темпе. На это ушло 40 минут. При таком темпе на простое переворачивание страниц всех книг в библиотеке с семью миллионами томов (например, в библиотеке альма-матер Пейджа, Университета штата Мичиган) ушло бы около 500 лет. И, разумеется, в Университете Мичигана хранились далеко не все книги мира. Например, перелистывание страниц всех книг мира для цифрового сканирования и перевода содержимого в читаемую машиной форму заняло бы тысячелетия. Это казалось невозможным.
Но, разумеется, вы мыслите не как 29-летний миллиардер. Для этого гиганта эпохи интернет-бизнеса, детище которого совсем скоро должно было войти в рейтинг крупнейших мировых компаний Fortune 500, человекотысячелетие представляет собой обычный товар, который можно купить.
Поэтому когда президент Университета штата Мичиган Мэри Сью Коулман сказала Пейджу, что полная оцифровка книг университета потребует тысячи лет, он предложил в ответ услуги Google и заявил, что для решения этой задачи ему понадобится всего шесть лет[79].
И вот так Google начала проект по оцифровке каждой из когда-либо написанных книг – для того, чтобы собрать воедино всю мировую библиотеку и загрузить ее на жесткий диск компьютера.
Страницы Пейджа
Перед тем как Google смогла заняться покупкой и сканированием всех книг, компания нуждалась в списке, позволявшем понять, какие книги ей потребуются, а какие уже отсканированы. Поэтому Google собрала информацию о книжных каталогах из сотен библиотек и компаний, а затем объединила эти каталоги для создания списка, содержащего информацию о каждой из когда-либо написанных книг (или, точнее, о каждой книге, дожившей до наших дней. К примеру, в этот список не вошли книги, утраченные при пожаре в Александрийской библиотеке). Итоговый список включил 130 миллионов книг[80].
Затем компании нужно было приобрести и отсканировать каждую книгу. В некоторых случаях издатели отправляли компании книги сразу же после печати. Это позволяло Google сканировать книгу «с разрушением» – сотрудники разделяли книги на отдельные страницы, а затем очень быстро сканировали их одну за другой, сохраняя все изображения в цифровом формате, который можно было легко просматривать на компьютере. В случае всех остальных книг компания обратилась в библиотеки всего мира, проверяя полку за полкой и отдел за отделом. Как обычно, когда дело доходит до библиотек, книги нужно было вовремя вернуть – даже такая компания, как Google, не могла позволить себе платить штрафы за несвоевременный возврат. Поэтому Google разработала неразрушающую технологию. Она наняла на работу небольшую армию переворачивателей страниц, которые, наподобие Пейджа и Майер, целый день переворачивали страницы, в то время как мощные камеры фотографировали их содержимое[81]. За прошлое десятилетие этот эскадрон бесконечного сканирования перевернул примерно миллиард страниц. Время от времени на изображениях можно заметить след от пальца.
Наконец благодаря «оптическому распознаванию текста» (при котором компьютерная программа находит и распознает в изображении буквы и цифры) оцифрованные образы превращаются в сырой текст. В результате появляется текстовый файл (похожий на то, что вы создаете при печати в текстовом редакторе), содержащий всю книгу.
Усилия Google по оцифровке оказались невероятно успешными, и это был подлинный триумф логики 29-летнего миллиардера. Через 10 лет после того, как Пейдж перевернул первые страницы книги с Мариссой Майер, и через 9 лет после его публичного объявления о проекте Google оцифровала свыше 30 миллионов книг[82].