Что такое одноуровневая память
Прежде чем погрузиться внутрь одноуровневой памяти, давайте попытаемся осмыслить общую картину, рассмотрев ее концепции и компоненты. Затем обсудим, почему одноуровневая память столь важна для AS/400 и разберем некоторые детали ее работы, взяв в качестве примера программу, выполняющую последовательное чтение индексированного файла базы данных (READ на ЯВУ или FETCH в SQL). В рамках этого примера мы разберем использование нескольких объектов: программы, индекса, курсора, области данных и др. Некоторые из них находятся в памяти, а некоторые нет.
Начнем с краткого обзора адресации этих и любых других объектов. Над MI нет различий между памятью и диском (или другим вспомогательным хранилищем). OS/ 400 работает только с объектами, их именами и открытым содержимым. MI работает со своими объектами — декомпозицией объектов OS/400 — с помощью их идентификаторов (указателей). Других способов задания объектов на уровне MI нет.
Программы, курсоры, области данных и другие объекты могут быть найдены простым указанием их имени. Чтобы использовать объект как ресурс, исполняющейся программе нужно «знать» только его имя и тип (как Вы помните, указание библиотеки необязательно, так как если она не задана, то будет просматриваться список библиотек). Имя объекта сразу же отображается в виртуальный адрес. Виртуальные адреса всех поименованных объектов находятся в библиотеках. Данный адрес помещается в указатель в процессе операции разрешения (описывалась в главе 5). Таким образом, системный указатель содержит виртуальный адрес заголовка объекта, который, в свою очередь, может содержать указатели на другие части данного объекта OS/400 и связанных с ним объектов MI.
Для обращения к данным объекта, или для исполнения команд программы, они должны быть перенесены в память. В нашем примере последовательного чтения базы данных, фрагмент программы, содержащий команды на выполнение чтения, должен быть перенесен с диска в память, прежде чем команды исполнятся. Такой перенос с диска в память происходит ниже уровня MI, так как MI не различает диск и память.
Можно считать, что все объекты находятся в памяти. То, что размер физической памяти слишком мал для хранения всех объектов — ограничение современных аппаратных технологий. Когда требуется фрагмент объекта, которого в памяти нет, этот отсутствующий фрагмент переносится и замещает некоторую неиспользуемую часть памяти. Можно также для наглядности представлять себе память как набор экранов, используемых для просмотра огромного пространства, содержащего все объекты. Процесс переноса страниц в память и из нее тогда будет выглядеть как изменения изображений на одном или нескольких экранах.
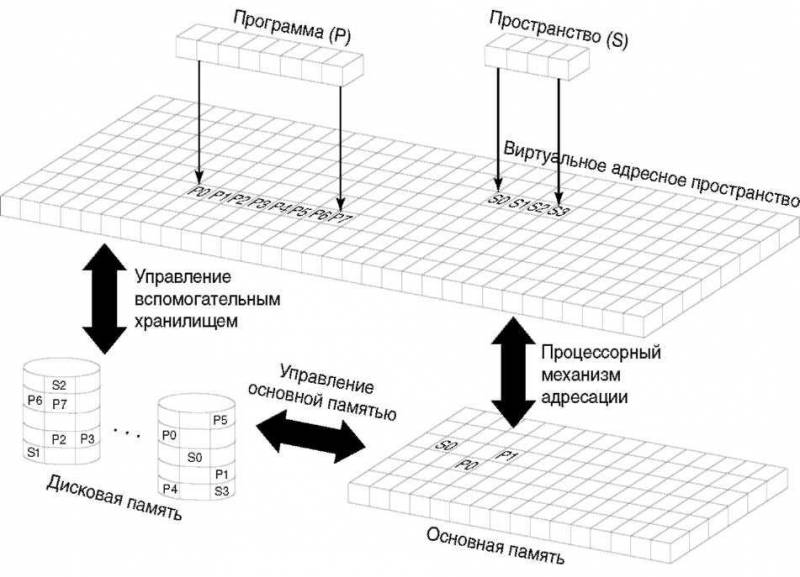
Рисунок 8.1 иллюстрирует отображение объектов на виртуальные адреса ниже уровня MI. Физическое расположение разных фрагментов объектов здесь показано на примере двух: программы и пространства. Для простоты восприятия даны очень маленькие объекты, но концепция неизменна для объектов любого размера. Кроме того, на рисунке изображены два основных компонента управления памятью SLIC: управление вспомогательной памятью и управление основной памятью. Вкратце, их функции таковы: управление вспомогательной памятью распределяет виртуальным адресам объекта дисковое пространство, а управление основной памятью руководит перемещениями между дисковой и основной памятью.
Рисунок 8.1. Объекты в одноуровневом хранилище
На рисунке видно, что память состоит из соответствующих экранам из предыдущей аналогии, страничных фреймов (их называют так, потому что они содержат страницы), размер которых на машинах IMPI был равен 512 байтам, а теперь на PowerPC — 4 КБ (4 096 байтов). Объект на диске разделен на страницы того же размера, что и страницы памяти. Со страницей диска связан виртуальный адрес объекта. Он может обозначать любой байт в пространстве объекта, и следовательно, указывать в середину страницы. Большой объект может занимать несколько страниц, но система спроектирована так, что на странице не могут содержаться части более чем одного объекта.
Удивительно, но мне часто задают вопрос: «Для чего нужна виртуальная адресация до байта? Почему не адресовать просто объекты, как это делают команды MI?». Для полного ответа, необходимо начать с того, что AS/400 (как CISC, так и RISC-мо-дели) работают на самых обычных процессорах, получающих команды и данные из памяти. Механизм адресации процессора, показанный на рисунке 8.1, ничего «не знает» об объектах. Системные объекты MI находятся в памяти, и процессор использует побайтную адресацию для получения информации о них: записей файла, команд программы и т. д. Процессор IMPI использует для доступа к памяти 48-разрядный виртуальный адрес, транслируя его в реальный; процессор PowerPC — эффективные адреса, которые транслирует сначала в виртуальные, а потом в реальные адреса. В обоих процессорах адреса следующей команды и используемых данных хранятся в аппаратных регистрах.
Страница, перенесенная в память одним процессом (заданием), становится доступной любому другому. Множество заданий могут использовать команды программ совместно. Записи, считанные из базы данных последними, вероятно, все еще находятся в памяти. Объем дискового ввода-вывода значительно сокращается при многократном считывании одних и тех же записей. Предположим, что в нашем примере чтения базы данных используется индекс, разделяемый с другими пользователями системы. Если этот индекс был недавно считан одним из них, то часть или весь индекс, вероятно, все еще в памяти, и не нужно ждать выборки страниц индекса с диска. В обычной системе с более ограниченными возможностями разделения данных в память пришлось бы перенести новую копию индекса, несмотря на то, что одна там уже есть.
Получив виртуальный адрес, аппаратура сначала проверяет, не присутствует ли уже соответствующая страница в памяти. Если она там, то она и используется. Если нет, то отсутствующая страница будет считана с диска.
Трансляция виртуального адреса в реальный состоит в поиске в страничной таблице, расположенной в памяти, страничного фрейма, соответствующего виртуальному адресу. Аппаратный просмотр таблицы страниц в поисках группы записей PTEG (page table entry group) ведется с помощью алгоритма хеширования (описывается далее в этой главе). Каждая PTEG содержит восемь записей таблицы страниц, которые просматриваются по одной. Если заданная страница не найдена, то происходит страничная ошибка — аппаратное прерывание, по которому управление основной памятью SLIC определяет дисковый адрес, соответствующий виртуальному, и обращается к процессору ввода-вывода с просьбой прочитать страницу с диска.
Для ускорения поиска страниц, использовавшихся последними, процессор содержит набор регистров, называемый справочным буфером трансляции TLB (translation lookaside buffer), где запоминаются последние использовавшиеся записи таблицы страниц. Так как регистры TLB встроены в процессор, то загрузка из памяти, где расположена таблица страниц, при обращении виртуальному адресу недавно использованной страницы, не требуется. Если же виртуального адреса в TLB нет, то на следующей стадии процесса трансляции аппаратура обращается к таблице страниц.
Процессоры PowerPC, используемые в последних моделях AS/400, могут также работать в режиме неактивных тегов. Данный режим никогда не используется OS/400, но для полноты описания поговорим и о его адресации. Итак, если процессор PowerPC работает в режиме неактивных тегов, то аппаратура сначала обращается к справочному буферу сегментов SLB (segment lookaside buffer) — другому набору регистров микросхемы процессора, содержащему использованные последними фрагменты таблицы сегментов. Если совпадения в регистрах SLB не найдено, то аппаратура обращается к таблице сегментов в памяти перед тем, как обратиться к регистрам TLB и таблице страниц. Другими словами, в режиме неактивных тегов процесс трансляции адресов трехшаговый: эффективный — виртуальный — реальный.