Среди недостатков Hadoop – потребность тщательно следить за тем, чтобы при программировании в параллельном окружении создавался правильный ответ. Многие выкладки, которые просты для выполнения в однопотоковом окружении, требуют совершенно другого подхода в параллельных системах. Существуют два типа параллелизма: на уровне узлов или исполняемых модулей и на уровне системы. Параллелизм на уровне узлов заключается в простом выполнении одной и той же программы на каждом узле. Узлы не взаимодействуют между собой и не обмениваются информацией. Гораздо сложнее параллелизм на уровне системы, поскольку он предполагает координацию работы всех узлов и обмен информацией между ними для получения правильного результата. Таким образом, программисты должны быть внимательны при написании программы, с тем чтобы она соответствовала уровню параллелизма, который требуется для выполнения данной задачи.
Любые данные, в любом формате, любого объема
Способность Hadoop работать с любыми объемами данных в любом формате делает ее важной опорой единого аналитического окружения.
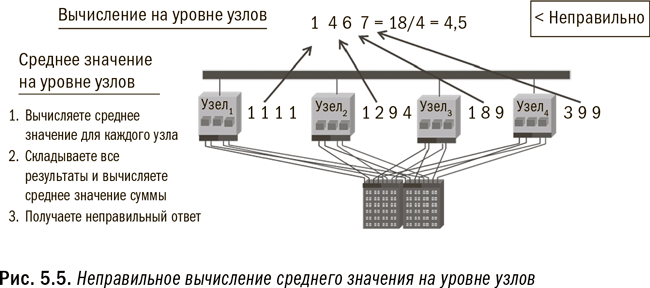
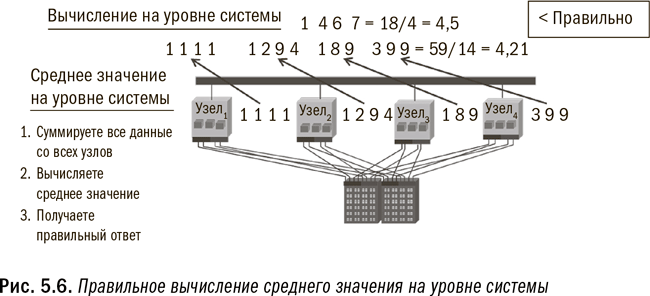
Например, вы не можете получить среднее значение, применяя процесс на уровне узлов или исполняемого модуля, поскольку каждый модуль сначала вычислит среднее значение на основе имеющихся у него данных, а затем сообщит вам свое среднее значение. Но, как вы помните из курса введения в статистику, вычисление среднего значения из средних значений не даст вам искомого правильного ответа. Вам нужно подсчитать общую сумму, чтобы затем вычислить общее среднее значение. (В качестве иллюстрации см. рис. 5.5 и 5.6.) Для обеспечения точности вычислений в Hadoop программисты должны заложить в программу надлежащий уровень параллелизма. В противоположность этому параллельное реляционное окружение построено таким образом, что параллелизм на уровне системы является в ней стандартом.
Сегодня на рынок приходят пакеты, дополняющие Hadoop синтаксисом наподобие SQL или даже методологией извлечения данных. Однако эти варианты все еще не являются настолько надежными, чтобы удовлетворять требованиям крупных организаций. Это возвращает нас к необходимости использовать каждую платформу в соответствии с ее назначением. Как указывалось в четвертой главе, с некоторыми задачами Hadoop справляется лучше других опций, но есть и задачи, где она проявляет себя неважно.
Как узнать, какой тип обработки подходит для Hadoop? Простейший тест должен определить: могут или нет ваши вычисления осуществляться параллельно и независимо друг от друга на отдельных узлах? Если независимая обработка подмножества данных каждого исполняемого модуля даст вам такой же ответ, как и обработка всего массива данных в одной большой системе, то Hadoop подойдет для таких вычислений. На рис. 5.5 и 5.6 проиллюстрированы примеры неправильного и правильного ее применения. Если же вы хотите узнать средний объем продаж по каждому отдельному потребителю, ответ будет правильным при условии, что все данные по каждому потребителю хранятся в одном модуле. Но если для получения ответа требуется передача данных между модулями, то, чтобы получить такой же ответ, как если бы все данные обрабатывались разом, Hadoop придется очень постараться. Разумеется, я чрезмерно упрощаю ситуацию, из которой имеются свои исключения, но эта рекомендация во многих случаях поможет вам выбрать правильное направление.
Еще один способ определить, насколько Hadoop подходит для управления алгоритмом, – это узнать, какого типа обработки, последовательной или непоследовательной, требует алгоритм. В реляционных системах SQL получает отвечающий комплект и шаги для прохождения каждой колонки цифр по маршруту, применяя к каждой записи заданные функции. SQL плохо справляется с задачами, когда для обработки необходимо перепрыгивать от колонки к колонке и от итерации к итерации (часто на основе результатов предыдущей итерации). Hadoop же использует такие языки программирования, как Java, Python или C++, которые лучше подходят для сложного управления данными, поскольку в этом случае не требуется последовательной построчной обработки.
Одна из интересных особенностей, связанных с использованием в Hadoop языков C++, Java и Python, состоит в том, что Hadoop не столько создает новые функции, сколько расширяет возможности масштабирования существующей функциональности. Любая программа, написанная сегодня на Java для Hadoop, могла быть написана несколько лет назад и реализована в традиционной однопоточной системе. Пусть используемый язык и не нов, зато ново окружение, где он применяется, что в огромной степени масштабирует применение Java.
Подведем итог: Hadoop в ее нынешнем виде лучше всего подходит для начального хранения данных из крупных источников и для начальных уточнения и обработки этих данных. Также Hadoop стоит использовать для хранения малоценных или нечасто используемых данных. Наконец, Hadoop замечательно подходит для архивирования. Однако в ближайшем будущем большинство организаций редко когда смогут использовать Hadoop для поддержки операционно-аналитических процессов в режиме реального времени.
Вспомогательные технологии
Вспомогательные технологии могут быть добавлены к единому аналитическому окружению с целью поддержки его опор. Эти вспомогательные технологии предназначены для специфических типов обработки или аналитики, являются гораздо более специализированными и применимы только в определенных случаях. Технологии, которые мы рассмотрим в этом разделе, будут продолжать развиваться, и со временем их список может расшириться. Также вполне возможно, что предлагаемая этими технологиями функциональность в конечном итоге будет встроена в одну или несколько опор и добавления вспомогательных компонентов не потребуется. Давайте рассмотрим некоторые из наиболее распространенных вспомогательных технологий по состоянию на начало 2014 г.
Технологии аналитики в памяти
Технологии аналитики в памяти загружают данные непосредственно в большой пул памяти, а затем приводят в действие сложные алгоритмы. Такие технологии стоят дорого ввиду необходимости иметь большой объем памяти, зато их производительность невероятно высока. Подход «вычисления в памяти» особенно эффективен в тех случаях, когда необходимо продолжать выстраивать и перестраивать большое количество сложных моделей. SAS предлагает устройство для аналитики в памяти вместе с несколькими различными платформами.
Сегодня распространено применение аналитики в памяти к моделям оценки риска в крупных финансовых учреждениях – им может требоваться обновление моделей риска для тысяч разных сценариев и ценных бумаг по крайней мере на ежедневной основе при принятии решений об инвестициях и хеджировании рисков.
Устройства на основе графических процессоров
Устройства на основе графических процессоров (Graphics Processing Units, GPU) предназначены для решения другого типа задач, нежели устройства для аналитики в памяти. Индивидуальный GPU поддерживает масштабную вычислительную обработку, но не обязательно работу с большими массивами данных. При применении GPU к аналитическим процессам заимствуется технология, изначально разработанная для создания сложной компьютерной графики на персональных компьютерах. GPU управляют монитором ПК путем применения сотен и даже тысяч слабых процессоров к массиву данных. Обработка миллионов пикселей для видеоигры требует огромной параллельной обработки. Хотя GPU уступают в скорости и надежности серийным микропроцессорам, они могут быть использованы для сжатия математических данных. Устройства на основе GPU предлагает, например, компания Fuzzy Logix.