Единый мозг со специализированными подсистемами
Единое аналитическое окружение на основе текстуры будет функционировать как единый мозг с несколькими специализированными подсистемами. При таком способе интеграции различных технологий единое целое будет обладать гораздо большим потенциалом, чем его отдельные компоненты, – точно так же, как это происходит в случае человеческого головного мозга.
Оба формата XML и JSON имеют структуру, но она далеко не такая чистая, четко определенная и неизменная, как в традиционных форматах, таких как файлы фиксированной ширины или файлы с разделителями. Форматы XML и JSON часто называют слабоструктурированными. Извлечение информации из данных, представленных в таких форматах, требует некоторых дополнительных усилий, но зато придает необходимую гибкость. На рис. 5.3 приведен пример файла JSON. При взгляде на него легко понять, что означает каждый элемент данных, однако этот формат не очень удобен, когда дело доходит до написания кода для анализа данных и извлечения отдельных полей.

Большое преимущество реляционных технологий корпоративного класса состоит в том, что они позволяют не только масштабировать объем данных и мощность обработки, но и надежно управлять ресурсами, чтобы справиться с широким разнообразием требований, предъявляемых к данным в крупной организации. Это важно, поскольку наряду с операционной аналитикой в режиме реального времени нужно будет осуществлять масштабную пакетную обработку, выполнять запросы для создания отчетности и многое другое. Без управления ресурсами такая смешанная рабочая нагрузка создаст серьезную проблему.
Концепцию смешанной рабочей нагрузки можно представить в виде транспортного затора, когда грузовики, легковые автомобили, мотоциклы, спецмашины, фургоны и т. д. соперничают между собой за полосы движения. В базах данных вместо разных типов транспортных средств поступают запросы разных типов, разных размеров и с разными приоритетами. Если не регулировать потоки этих запросов, система перестанет с ними справляться и возникнет «пробка». В то же время надежная подсистема управления ресурсами организует все запросы по их приоритетности и объему ресурсов: выделяются полосы для спецтранспорта, платные полосы для тех, кто нуждается в привилегиях, и т. п. В результате каждому предоставляются наилучшие условия. Хорошая подсистема управления ресурсами позволяет многим пользователям и процессам эффективно использовать систему совместно.
Главная опора операционной аналитики
Реляционная опора обычно является лучшим местом для развертывания операционной аналитики. С учетом ее масштабируемости по всем необходимым параметрам, а также ее способности легко интегрироваться почти со всеми корпоративными приложениями реляционная технология играет важную роль в превращении традиционной аналитики в операционную.
Реляционные технологии корпоративного класса поддерживают массовый параллелизм и обладают возможностями по обеспечению строгой безопасности. Другими словами, системы могут жестко контролировать, кто и к каким данным имеет доступ, а также позволяют многим пользователям одновременно получать доступ к одним и тем же данным. Другие преимущества реляционных систем: доступность, надежность, восстанавливаемость и управляемость. Эти свойства приобретают важнейшее значение, когда, скажем, сотни сотрудников колл-центра плюс тысячи сотрудников на местах, плюс тысячи сотрудников в штаб-квартире нуждаются в доступе к одной и той же информации. Большинство приложений, которые сегодня используются крупными организациями, предназначены для работы с реляционным сервером баз данных, что еще повышает привлекательность реляционных технологий и легкость их интеграции.
Подведем итог: именно на реляционной опоре организации обычно стремятся развернуть операционно-аналитические процессы. Именно на реляционную технологию, благодаря ее возможностям масштабирования, опирается организация, когда наступает время превратить традиционную аналитику в операционную.
Опора для обнаружения данных
В последнее время немало внимания на рынке привлекает идея добавления к единому аналитическому окружению платформы для обнаружения данных. Обнаружение данных не является новой концепцией как таковой, и большинство организаций уже имеют для этого то или иное окружение. Классическое автономное окружение, в котором специалисты-аналитики годами разрабатывали новые виды аналитики, также является формой для обнаружения данных. Отличие состоит в том, что классическое аналитическое окружение редко когда интегрируется с другими корпоративными системами и, как правило, не масштабируется. Настало время оставить эти устаревшие архитектуры в прошлом. Сегодня для процессов обнаружения данных часто используются такие инструменты, как SAS, IBM SPSS и R. Каждый из них может быть использован в рамках интегрированной платформы для обнаружения данных, а не только в рамках автономного окружения.
Следует заметить, что не так давно изменился способ применения аналитических инструментов. Они гораздо плотнее интегрируются с масштабируемыми платформами, которые являются частью корпоративного аналитического окружения. И реляционные технологии, и Hadoop позволяют перейти от автономного изолированного обнаружения данных к платформам для обнаружения данных. Эти платформы являются частью единого корпоративного аналитического окружения.
Платформы для обнаружения данных выходят за пределы аналитической «песочницы» – изолированной программной среды, которая давно уже встраивалась в другие платформы. Аналитическая «песочница» производит логическое разделение большой операционной системы, что дает специалистам-аналитикам возможность не только запрашивать, но и загружать и создавать данные. Она позволяет осуществлять быстрое исследование и моделирование аналитических процессов в нужном масштабе благодаря использованию самых масштабируемых платформ, которые только есть у организации. Недавно такие «песочницы» стали очень популярны в окружении хранилищ реляционных данных. Хотя окружение для обнаружения данных также может содержать аналитические «песочницы», но оно представляет собой нечто большее.
Сегодня платформы для обнаружения данных, которые являются второй опорой единого аналитического окружения, позволяют смешивание и сопоставление всех типов данных, как структурированных, так и нет. Такая платформа должна поддерживать и реляционную, и нереляционную обработку. Она также должна поддерживать практически любой вид аналитической методологии или подхода. Это означает, что она должна поддерживать не только традиционные методы статистики и прогнозирования, но и текстовый анализ (имейлов, документов и т. д.), анализ объектных графов (взаимных связей между людьми, местностями или объектами), геопространственный анализ (пространственных отношений) и многое другое. На рис. 5.4 проиллюстрировано, как платформа для обнаружения данных комбинирует и упрощает обработку аналитики.
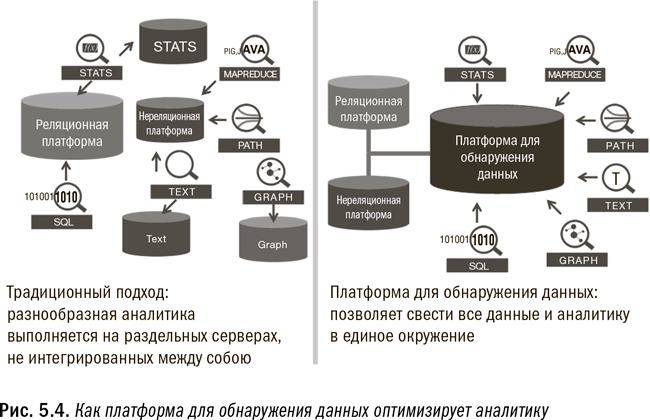
Важная особенность окружения для поиска данных – здесь действуют крайне слабые правила и ограничения. Такие платформы для обнаружения данных, как Teradata Aster и Pivotal Greenplum, не только предоставляют собственные аналитические алгоритмы, но и поддерживают использование общих аналитических инструментов, таких как SAS, SPSS или R. Они также идеально подходят для применения в инновационных центрах{45}. Поисковая платформа может быть встроена или нет в окончательный операционно-аналитический процесс. Разумеется, она используется для обнаружения и определения аналитического процесса, который стоит внедрения. Но как только детализированная аналитическая логика, необходимая для выполнения поиска, определена, ее можно встраивать в процесс обработки напрямую, без использования поисковой платформы. Это происходит благодаря тому, что зачастую можно существенно упростить и оптимизировать аналитический процесс при переходе от фазы обнаружения к фазе обработки. Подробнее об этом мы поговорим в шестой главе.