--4780-- translate: generic_unknown SP updates identified: 76 ( 4.7%)
--4780-- tt/tc: 3,341 tt lookups requiring 3,360 probes
--4780-- tt/tc: 3,341 fast-cache updates, 3 flushes
--4780-- transtab: new 1,553 (33,037 -> 538,097; ratio 162:10) [0 scs]
--4780-- transtab: dumped 0 (0 -> ??)
--4780-- transtab: discarded 6 (143 -> ??)
--4780-- scheduler: 21,623 jumps (bb entries).
--4780-- scheduler: 0/1,828 major/minor sched events.
--4780-- sanity: 1 cheap, 1 expensive checks.
--4780-- exectx: 30,011 lists, 6 contexts (avq 0 per list)
--4780-- exectx: 6 searches, 0 full compares (0 per 1000)
--4780-- exectx: 0 cmp2, 4 cmp4, 0 cmpAll $
Вы видите, что обнаружены некорректные считывания и записи, и интересующие нас блоки памяти приводятся с указанием места, которое для них отведено. Для прерывания выполнения программы в ошибочном месте можно применить отладчик.
У программы
valgrind
есть много опций, включая подавление ошибок определенного типа и обнаружение утечки памяти. Для выявления такой утечки в примере вы должны использовать одну из опций, передаваемых
valgrind
. Для контроля утечек памяти после завершения программы следует задать опцию
--leak-check=yes
. Список опций можно получить с помощью команды
valgrind --help
.
Как это работает
Программа выполняется под контролем средства valgrind, которое перехватывает действия, совершаемые программой, и выполняет множество проверок, включая обращения к памяти. Если обращение относится к выделенному блоку памяти и некорректно, valgrind выводит сообщение. В конце программы выполняется подпрограмма "сбора мусора", которая определяет, есть ли выделенные и неосвобожденные блоки памяти. Об этих потерянных блоках выводится сообщение.
Резюме
В этой главе обсуждались некоторые методы и средства отладки. Система Linux предоставляет ряд мощных инструментов для удаления ошибок из ваших программ. Вы устранили несколько ошибок в программе с помощью отладчика gdb и познакомились с некоторыми средствами статического анализа, такими как
cflow
и
splint
. В заключение были рассмотрены проблемы, возникающие при использовании динамически распределяемой памяти, и некоторые средства, способные помочь обнаружить их, например ElectricFence и
valgrind
.
Утилиты, обсуждавшиеся в этой главе, в основном хранятся на FTP-серверах в Интернете. Авторы, имеющие к ним отношение, могут порой сохранять авторские права на них. Информацию о многих утилитах можно найти в архиве Linux, по адресу http://www.ibiblio.org/pub/Linux. Мы надеемся, что новые версии будут появляться на этом Web-сайте по мере их выхода в свет.
Глава 11
Процессы и сигналы
Процессы и сигналы формируют главную часть операционной среды Linux. Они управляют почти всеми видами деятельности ОС Linux и UNIX-подобных компьютерных систем. Понимание того, как Linux и UNIX управляют процессами, сослужит добрую службу системным и прикладным программистам или системным администраторам.
В этой главе вы узнаете, как обрабатываются процессы в рабочей среде Linux и как точно установить, что делает компьютер в любой заданный момент времени. Вы также увидите, как запускать и останавливать другие процессы в ваших собственных программах, как заставить процессы отправлять и получать сообщения и как избежать процессов-зомби. В частности, вы узнаете о:
□ структуре процесса, его типе и планировании;
□ разных способах запуска новых процессов;
□ порождающих (родительских), порожденных (дочерних) процессах и процессах-зомби;
□ сигналах и их применении.
Что такое процесс?
Стандарты UNIX, а именно IEEE Std 1003.1, 2004 Edition, определяют процесс как "адресное пространство с одним или несколькими потоками, выполняющимися в нем, и системные ресурсы, необходимые этим потокам. Мы будем рассматривать потоки в главе 12, а пока будем считать процессом просто любую выполняющуюся программу.
Многозадачные системы, такие как Linux, позволяют многим программам выполняться одновременно. Каждый экземпляр выполняющейся программы создает процесс. Это особенно заметно в оконной системе, например Window System (часто называемой просто X). Как и ОС Windows, X предоставляет графический пользовательский интерфейс, позволяющий многим приложениям выполняться одновременно. Каждое приложение может отображаться в одном или нескольких окнах.
Будучи многопользовательской системой, Linux разрешает многим пользователям одновременно обращаться к системе. Каждый пользователь в одно и то же время может запускать много программ или даже несколько экземпляров одной и той же программы. Сама система выполняет в это время другие программы, управляющие системными ресурсами и контролирующие доступ пользователей.
Как вы видели в главе 4, выполняющаяся программа или процесс состоит из программного кода, данных, переменных (занимающих системную память), открытых файлов (файловых дескрипторов) и окружения. Обычно в системе Linux процессы совместно используют код и системные библиотеки, так что в любой момент времени в памяти находится только одна копия программного кода.
Структура процесса
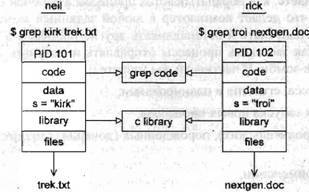
Давайте посмотрим, как организовано сосуществование двух процессов в операционной системе. Если два пользователя neil и rick запускают в одно и то же время программу grep для поиска разных строк в различных файлах, применяемые для этого процессы могут выглядеть так, как показано на рис. 11.1.
Рис. 11.1
Если вы сможете выполнить команду
ps
, как в приведенном далее коде, достаточно быстро и до того, как завершатся поиски строк, вывод будет выглядеть подобно следующим строкам:
$ <b>ps -ef</b>
UID PID PPID С STIME TTY TIME CMD
rick 101 96 0 18:24 tty2 00:00:00 grep troi nextgen.doc
neil 102 92 0 18:24 tty4 00:00:00 grep kirk trek.txt
Каждому процессу выделяется уникальный номер, именуемый идентификатором процесса или PID. Обычно это положительное целое в диапазоне от 2 до 32 768. Когда процесс стартует, в последовательности выбирается следующее неиспользованное число. Когда все номера будут исчерпаны, выбор опять начнется с 2. Номер 1 обычно зарезервирован для специального процесса
init
, который управляет другими процессами. Мы скоро вернемся к процессу
init
. А пока вы видите, что двум процессам, запущенным пользователями neil и rick, выделены идентификаторы 101 и 102.
Код программы, которая будет выполняться командой
grep
, хранится в файле на диске. Обычно процесс Linux не может писать в область памяти, применяемую для хранения кода программы, поэтому программный код загружается в память как доступный только для чтения. На рис. 11.1 видно, что несмотря на то, что в данную область нельзя писать, она может безопасно использоваться совместно.