2. Возможность запуска определенных программ как обычных приложений, а не как частей ядра. Скажем, большинство версий Unix сервера RARP — это обычные приложения, которые считывают запросы RARP с канального уровня (запросы RARP не являются дейтаграммами IP), а затем передают ответы также на канальный уровень.
Три наиболее распространенных средства получения доступа к канальному уровню в Unix — это пакетный фильтр BSD (BPF, BSD Packet Filter), DLPI в SVR4 (Datalink Provider Interface — интерфейс поставщика канального уровня) и интерфейс пакетных сокетов Linux (
SOCK_PACKET
). Мы приводим в этой главе обзор перечисленных средств, а затем описываем
libcap
— открытую для свободного доступа библиотеку, содержащую функции для захвата пакетов. Эта библиотека работает со всеми тремя перечисленными средствами, и использование библиотеки позволяет сделать наши программы не зависящими от фактического способа обеспечения доступа к канальному уровню, применяемому в данной операционной системе. Мы описываем эту библиотеку, разрабатывая программу, которая посылает запросы серверу имен DNS (мы составляем свои собственные дейтаграммы UDP и записываем их в символьный сокет) и считывает ответ при помощи
libcap
, чтобы определить, добавляет ли сервер имен контрольную сумму в дейтаграммы UDP.
29.2. BPF: пакетный фильтр BSD
4.4BSD и многие другие Беркли-реализации поддерживают BPF — пакетный фильтр BSD (BSD Packet Filter). Реализация BPF описана в главе 31 [128]. История BPF, описание псевдопроцессора BPF и сравнение с пакетным фильтром SunOs 4.1.x NIT приведены в [72].
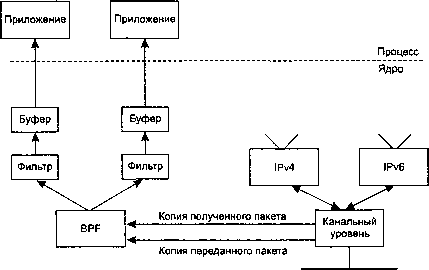
Каждый канальный уровень вызывает BPF сразу после получения пакета и непосредственно перед его передачей выше, как показано на рис. 29.1.
Рис. 29.1. Захват пакета с использованием BPF
Примеры подобных вызовов для интерфейса Ethernet приведены на рис. 4.11 и 4.19 в [128]. Вызов BPF должен произойти как можно скорее после получения пакета и как можно позже перед его передачей, так как это увеличивает точность временных отметок.
Организовать само по себе перехватывание пакетов из канального уровня не очень сложно, однако преимущество BPF заключается в возможности их фильтрации. Каждое приложение, открывающее устройство BPF, может загрузить свой собственный фильтр, который затем BPF применяет к каждому пакету. В то время как некоторые фильтры достаточно просты (например, при использовании фильтра
udp or tcp
принимаются только пакеты UDP и TCP), другие фильтры позволяют исследовать значения определенных полей в заголовках пакетов. Например, фильтр
tcp and port 80 and tcp[13:l] & 0x7 != 0
использовался в главе 14 [128] для отбора сегментов TCP, направлявшихся к порту 80 или от него и содержащих флаги SYN, FIN или RST. Выражение
tcp [13:1]
соответствует однобайтовому значению, начинающемуся с 13-го байта от начала заголовка TCP.
В BPF реализован основанный на регистрах механизм фильтрации, который применяет специфические для приложений фильтры к каждому полученному пакету. Хотя можно написать свою программу фильтрации на машинном языке псевдопроцессора (он описан в руководстве по использованию BPF), проще всего будет компилировать строки ASCII (такие, как только что показанная строка, начинающаяся с
tcp
) в машинный язык с помощью функции
pcap_compile
, о которой мы рассказываем в разделе 29.7.
В технологии BPF применяются три метода, позволяющие уменьшить накладные расходы на ее использование.
1. Фильтрация BPF происходит внутри ядра, за счет чего минимизируется количество данных, которые нужно копировать из ядра в приложение. Копирование из пространства ядра в пользовательское пространство является довольно дорогостоящим. Если бы приходилось копировать каждый пакет, у BPF могли бы возникнуть проблемы при попытке взаимодействия с быстрыми каналами.
2. BPF передает приложению только часть каждого пакета. Здесь речь идет о длине захвата (capture length). Большинству приложений требуется только заголовок пакета, а не содержащиеся в нем данные. Это также уменьшает количество данных, которые BPF должен скопировать в приложение. В программе
tcpdump
, например, по умолчанию это значение равно 68 байт, и этого достаточно для размещения 14-байтового заголовка Ethernet, 20-байтового заголовка IP, 20-байтового заголовка TCP и 14 байт данных. Но для вывода дополнительной информации по другим протоколам (например, DNS или NFS) требуется, чтобы пользователь увеличил это значение при запуске программы
tcpdump
.
3. BPF буферизует данные, предназначенные для приложения, и этот буфер передается приложению только когда он заполнен или когда истекает заданное время ожидания для считывания (read timeout). Это время может быть задано приложением. Программа
tcpdump
, например, устанавливает время ожидания 1000 мс, а демон RARP задает нулевое время ожидания (поскольку пакетов RARP немного, а сервер RARP должен послать ответ сразу, как только он получает запрос). Назначением буферизации является уменьшение количества системных вызовов. При этом между BPF и приложением происходит обмен тем же количеством пакетов, но за счет того, что уменьшается количество системных вызовов, каждый из которых связан с дополнительными накладными расходами, уменьшается и общий объем этих расходов. Например, на рис. 3.1 [110] сравниваются накладные расходы, возникающие при системном вызове read, когда файл считывается в несколько приемов, причем размер фрагментов варьируется от 1 до 131 072 байт.
Хотя на рис. 29.1 мы показываем только один буфер, BPF поддерживает по два внутренних буфера для каждого приложения и заполняет один, пока другой копируется в приложение. Эта стандартная технология носит название двойной буферизации (double buffering).
На рис. 29.1 мы показываем только получение пакетов фильтром BPF: пакеты, приходящие на канальный уровень снизу (из сети) и сверху (IP). Приложение также может записывать в BPF, в результате чего пакеты будут отсылаться по канальному уровню, но большая часть приложений только считывает пакеты из BPF. У нас нет оснований использовать BPF для отправки дейтаграмм IP, поскольку параметр сокета
IP_HDRINCL
позволяет нам записывать дейтаграммы IP любого типа, включая заголовок IP. (Подобный пример мы показываем в разделе 29.7.) Записывать в BPF можно только с одной целью — чтобы отослать наши собственные сетевые пакеты, не являющиеся дейтаграммами IP. Например, демон RARP делает это для отправки ответов RARP, которые не являются дейтаграммами IP.
Для получения доступа к BPF необходимо открыть (вызвав функцию
open
) еще не открытое каким-либо другим процессом устройство BPF. Скажем, можно попробовать
/dev/bpf0
, и если будет возвращена ошибка
EBUSY
, то —
/dev/bpf1
, и т.д. Когда устройство будет открыто, потребуется выполнить примерно 12 команд
ioctl
для задания характеристик устройства, таких как загрузка фильтра, время ожидания для считывания, размер буфера, присоединение канального уровня к устройству BPF, включение смешанного режима, и т.д. Затем с помощью функций
read
и
write
осуществляется ввод и вывод.