Однако, несмотря на столь внушительные успехи, в области поиска нейросетевых архитектур существует ещё множество открытых вопросов. Как сделать процесс поиска наиболее вычислительно эффективным? Эксперименты в этой области пока что требуют значительных вычислительных ресурсов. Можно ли повторить успехи NAS в других областях, не связанных с обработкой изображений, и какие алгоритмы позволят добиться наибольшей эффективности в этом направлении? И наконец, нельзя ли создать универсальные методы, позволяющие осуществлять эффективный поиск нейросетевых архитектур для решения произвольных задач?
Все эти проблемы изучаются в рамках области машинного обучения, получившей название «метаобучение» [meta-learning]. Основная цель метаобучения — улучшение производительности существующих методов машинного обучения; по сути, перед метаобучением стоит задача «научиться учиться» [learn to learn].
Другое важное направление исследований — перенос обучения (знаний) [transfer learning] (мы коротко затрагивали эту тему, рассуждая о возможностях импульсных нейронных сетей). Эта область занимается поиском методов, позволяющих использовать знания, полученные при решении одной задачи, для решения других, сходных с ней. Например, модель, обученная различать различных животных на изображениях, может быть использована для распознавания пород собак. Одной из разновидностей переноса знаний является дообучение, или тонкая настройка [fine-tuning], модели с применением сравнительно небольших датасетов, содержащих примеры решения целевых задач. В некотором роде триумфом переноса обучения стало появление предобученных моделей для обработки естественного языка, основанных на трансформерных архитектурах, — мы подробно обсуждали этот вопрос в ходе рассказа о моделях семейства GPT. Проклятием переноса обучения является проблема «катастрофического забывания» [catastrophic forgetting][3297], которая заключается в том, что в процессе доучивания модель быстро теряет полученные ранее знания. Чтобы не допустить этого, доучивание обычно ограничивают небольшим количеством эпох обучения, а также используют низкие значения скорости обучения. Однако это делает сам процесс доучивания вычислительно более дорогим, менее эффективным и менее стабильным. Для борьбы с катастрофическим забыванием предложен ряд весьма остроумных техник, таких как, например, «эластическая консолидация весов» [elastic weights consolidation][3298], [3299] или «ослабление скоростей весов» [weight velocity attenuation][3300], однако они нередко связаны с существенными дополнительными затратами (вычислительными или в виде использования дополнительного объёма памяти).
Хотя в наши дни нейросетевые модели обычно обучают при помощи различных методов градиентного спуска, исследователи задумываются над тем, чтобы использовать более «умные» алгоритмы для подстройки весов нейронных сетей. Теоретически, «изучив» множество сессий обучения, некоторая модель может научиться более эффективно модифицировать веса нейронной сети, чтобы достигать меньшего значения ошибки за меньшее число шагов обучения. Решением этой задачи по «воспитанию воспитателя» в настоящее время занимается ряд исследователей, и уже получены первые обнадёживающие результаты[3301] в этой области. Не исключено, что развитие именно этого направления позволит совершить очередной прорыв в области машинного обучения в ближайшем будущем.
Возможно, новые исследования позволят найти замену даже такому, казалось бы, фундаментальному элементу нейросетевых технологий, как метод обратного распространения ошибки. Авторы статьи «Градиенты без обратного распространения ошибки» (Gradients without Backpropagation)[3302], вышедшей в свет в начале 2022 г., показывают в своём исследовании, что градиенты весов нейронной сети можно рассчитывать при помощи более быстрого алгоритма, который авторы назвали «прямым градиентом» [forward gradient].
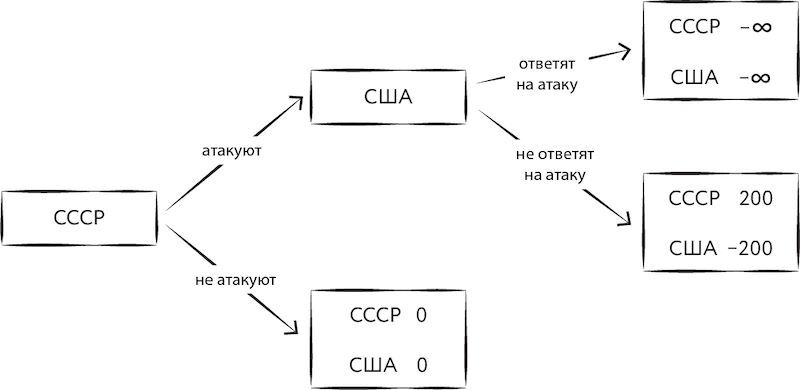
Рост интереса к большим языковым моделям вслед за громким успехом таких проектов, как GPT-3 и ChatGPT, привёл к расширению исследований в этой и смежных областях — мы говорили в разделах 6.6.5 и 6.6.6 о многих актуальных вызовах, стоящих перед создателями будущих LLM. Одной из наиболее амбициозных стратегических целей здесь является выстраивание «мостика» от современных LLM и MLLM к будущим системам общего искусственного интеллекта. Развитие моделей, способных строить цепочки и деревья рассуждений, ставит вопрос о возможности применения продвинутых языковых моделей к задачам стратегического планирования. Ни для кого не секрет, что теория игр, и в частности деревья (и графы) возможных решений, активно использовалась в стратегическом планировании ещё в годы холодной войны (Первой холодной войны?).
Рис. 178. Пример дерева возможных альтернатив для принятия стратегического решения
В наши дни важным инструментом для создания и анализа таких деревьев могут стать большие языковые модели. Поскольку они в некоторой мере уже сегодня являются пусть и упрощёнными, но моделями мира, их можно использовать как для генерации возможных альтернатив, так и для оценки всей совокупности совершённых акторами действий в терминальных узлах дерева. Таким образом, деревья стратегических решений могут стать куда более сложными и разветвлёнными. Все эти идеи наводят на мысль о возможности создания обобщающей теории применения фундаментальных моделей в решении сложных интеллектуальных задач. Например, на роль такой теории может претендовать концепция программ на базе больших языковых моделей [Large Language Model Programs][3303], [3304]. Скорее всего, в ближайшие годы в этой области появится множество новых проектов и стартапов.
В 2022 г. своим видением на развитие ИИ в ближайшее десятилетие поделился Ян Лекун[3305]. По его мнению, сейчас перед отраслью стоят три основных вызова:
системы ИИ должны научиться представлять мир;
системы ИИ должны научиться строить умозаключения и планы путями, совместимыми с обучением на основе градиентных методов оптимизации;
системы ИИ должны научиться строить иерархии планов действий.
Лекун видит решение первой проблемы в развитии методов самообучения [self-supervised learning]. Их успешное применение будет означать, что системы ИИ способны создавать сложные модели мира. При этом, по мнению Лекуна, роль данных для обучения для следующего поколения систем машинного обучения уготована уже не языку и не изображениям, а видео. В настоящее время Meta (бывшая Facebook) прилагает много усилий для сбора видеоданных от первого лица. Впрочем, по словам Лекуна, видео с YouTube также являются подходящим учебным материалом.
Лекун считает, что системы искусственного интеллекта смогут из таких видеороликов узнать о физических основах нашего мира. А эти знания, в свою очередь, станут основой для развития способностей ИИ, связанных с реальным миром (например, хватание предметов или вождение автомобиля). Вообще весьма интересным является вопрос о том, можно ли создать универсальный искусственный интеллект путём машинного обучения, опирающегося только на имеющийся цифровой след человечества, или же для этого необходимо активное взаимодействие с окружающим миром при помощи физических аватаров (или хотя бы программных агентов, взаимодействующих с человеческим обществом при помощи Всемирной сети).