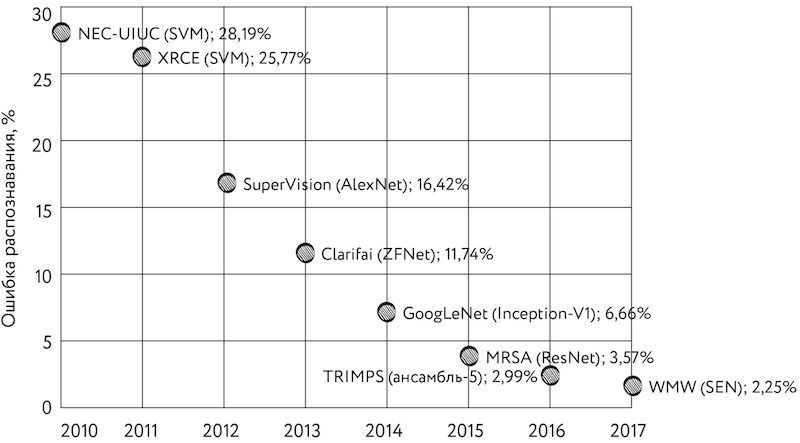
На соревновании ResNet-152 показала величину ошибки в 3,57%, тем самым достигнув сверхчеловеческого уровня точности распознавания и даже превзойдя уровень, продемонстрированный годом ранее ансамблем людей-экспертов.
В 2016 г. победу одержал ансамбль из пяти моделей, которыми были ResNet-200 (с двумя сотнями слоёв), третья и четвёртая версия сети Inception, плод «порочной любви» Inception и ResNet — InceptionResnet-v2, а также Wide residual network [Широкая сеть с остатками]. Ошибка такого ансамбля составила всего 2,99%.
Создатели ансамбля — команда TRIMPS (Third Research Institute of the Ministry of Public Security, Третий исследовательский институт Министерства общественной безопасности [Китая]) — в своём докладе, рассказывающем об их модели, обратили внимание на основные источники ошибок распознавания, среди которых главными были недостатки самого набора изображений и его разметки: неправильные метки, число объектов более пяти, неправильный «уровень» метки (например, картинка, на которой изображена тарелка с едой, имеет метку «ресторан» и т. д.). Подробный анализ «ошибок» современных моделей на базе ImageNet показывает, что ошиблась на самом деле не модель, а человек, выполнявший разметку[1874].
Впрочем, в 2017 г. авторам лучшей модели удалось ещё немного превзойти результат прошлого года. Ошибка снизилась до 2,25% благодаря появлению новой архитектуры, получившей название «Сети сжатия и возбуждения» (Squeeze-and-Excitation Networks). «Строительный блок» таких сетей представляет собой модуль inception со встроенным перепрыгивающим соединением[1875].
Рис. 120. Уменьшение ошибки при распознавании изображений на соревнованиях ILSVRC
6.2.1.5 Конец начала и перспективы развития
2017-й стал последним годом в истории ILSVRC. Эстафета по проведению состязаний по распознаванию изображений перешла к Kaggle (платформе для организации соревнований в области машинного обучения)[1876]. Но эти семь лет успели изменить буквально всё.
Один из организаторов ILSVRC Алекс Берг охарактеризовал произошедшие изменения следующим образом: «Когда мы начинали проект, такие вещи индустрия ещё не делала. Теперь это продукты, которые используют миллионы людей»[1877]. Действительно, менее чем за десять лет системы распознавания изображений из лабораторных прототипов превратились в компоненты множества высокотехнологичных продуктов и сервисов, представленных на рынке.
Хотя ImageNet и не был первым стандартизованным датасетом изображений (к 2009 г. их насчитывалось уже более двух десятков), однако он многократно превзошёл предшественников как по объёму, так и по детальности разметки, которая впервые была выполнена с привязкой к базе данных естественного языка. ILSVRC не были первыми соревнованиями по распознаванию изображений, однако стали самыми популярными среди таковых в истории (в 2010 г. в ILSVRC приняло участие 35 команд, в 2016 г. — 172 команды)[1878]. ILSVRC также не были первыми соревнованиями по распознаванию изображений, в которых победу одержала нейросетевая модель, однако именно победа нейросетевой модели на ILSVRC стала громким медийным поводом, привлекшим внимание общественности к успехам в этой области. И наконец, ILSVRC не были первыми соревнованиями, в которых машины превзошли человека в задаче распознавания образов, хотя именно этот результат теперь принято использовать в качестве одного из доказательств революционного прорыва, совершённого в отрасли машинного обучения в последние годы.
Наследниками ImageNet стали многочисленные специализированные датасеты, такие как Medical ImageNet (база данных медицинских изображений)[1879], SpaceNet (база данных фотоснимков объектов, выполненных из космоса)[1880], ActivityNet (база данных видеозаписей различной человеческой активности)[1881], EventNet (база данных с семантически размеченными видео)[1882] и так далее.
На последнем слайде выступления организаторов ILSVRC в 2017 г. размещена цитата Уинстона Черчилля: «Это не конец. Это даже не начало конца. Но, возможно, это конец начала»[1883].
Действительно, прогресс в точности распознавания образов не стоит на месте, а оценить его можно по результатам, приводимым в научных публикациях. Например, точность распознавания образов на массиве CIFAR-100 в 2019 г. выросла до 91,7% (модель EfficientNet)[1884] по сравнению с 89,3% (более ранняя модель от GoogleBrain на основе пирамидальных сетей (Feature Pyramid Networks, FPN) — специальной разновидности свёрточных сетей, в которой признаки, относящиеся к разным слоям свёртки, организованы в специальную пирамидальную иерархию, позволяющую более эффективно распознавать объекты разного масштаба[1885])[1886], [1887] в 2018 г. В 2020 г. при помощи модели EfficientNet-L2 на CIFAR-100 удалось получить точность 96,1% (этот показатель по состоянию на сентябрь 2023 г. продолжает оставаться лучшим). Этот результат был достигнут благодаря технологии, получившей название «Минимизация с учётом резкости» (Sharpness-Aware Minimization). Идея этого подхода заключается в том, чтобы предпочитать такие параметры модели, в окрестностях которых функция потерь будет иметь значения, мало отличающиеся от минимума. Такая стратегия оптимизации позволяет достичь более хорошего обобщения в процессе обучения[1888].
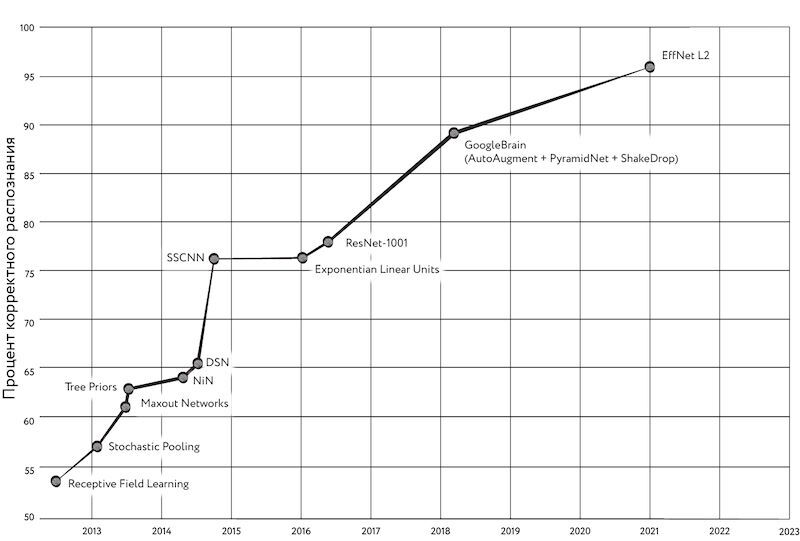
Рис. 121. Увеличение точности распознавания изображений на массиве CIFAR-100
Модели, побеждавшие на ILSVRC, стали основой систем, широко применяющихся для решения самых разных прикладных задач: жестового управления устройствами, распознавания лиц и дорожных объектов в автомобильных автопилотах, опухолей на медицинских снимках, текста, мимики, почерка, состава блюд и так далее — в наши дни под самые разные задачи распознавания опубликовано огромное количество публичных датасетов. Одна только моя команда за 2022-й и начало 2023 года разместила в открытом доступе два таких набора данных: HaGRID[1889], предназначенный для распознавания 18 управляющих жестов для умных устройств, и Slovo[1890] — для распознавания слов русского жестового языка.
Несколько модифицировав архитектуру нейронной сети, можно решать и более сложные задачи, чем просто классификация изображений. Мы уже упоминали некоторые из них при перечислении номинаций в рамках ILSVRC. Например, задача локализации объектов предполагает поиск минимальных по размеру прямоугольников, внутри которых находится интересующий нас объект. Сегодня нейронные сети успешно решают и более сложные варианты задачи распознавания образов, например задачу так называемой сегментации [segmentation], когда сеть должна найти точные контуры интересующих нас объектов. С этой задачей успешно справляются такие архитектуры, как, например, U-Net, разработанная на факультете информатики Фрайбургского университета (Albert-Ludwigs-Universität Freiburg) для задач сегментации медицинских изображений ещё в 2015 г.[1891] С помощью такой сети можно успешно выявлять аномалии на рентгеновских снимках, находить определённые типы клеток на микрофотографиях тканей живых организмов… А можно, скажем, и удалять нежелательных персонажей с красивых коллективных фото.