Ограниченность объёма книги не позволяет нам подробно разобрать некоторые другие интересные эмоциональные наборы данных и модели, построенные на их базе, поэтому я ограничусь здесь лишь коротким упоминанием некоторых из них. В 2020 г. китайские исследователи представили общественности мультимодальный датасет MEmoR[2480], основанный полностью на эмоциональной разметке сериала «Теория Большого взрыва» (Big Bang Theory). Создатели датасета уделили внимание разметке эмоций сразу нескольких персонажей, появляющихся в кадре, что позволяет моделям, обученным на этих данных, строить догадки о динамике эмоций общающихся людей. Мультимодальные датасеты MELD[2481] и EmoryNLP[2482] (оба включают около 13 тысяч фраз) основаны на другом популярном сериале — «Друзья» [Friends], другой мультимодальный датасет MEISD[2483] содержит по 1000 диалогов сразу из восьми популярных телесериалов, а CMU-MOSEI[2484] и MOSI[2485] содержат по несколько тысяч видео с YouTube, снабжённых эмоциональной разметкой.

Некоторые эмоциональные датасеты включают в себя только текстовую модальность, но могут при этом иметь весьма внушительные размеры и сложную разметку. Например, датасет GoEmotions[2486] содержит около 58 000 текстовых комментариев с платформы Reddit, размеченных при помощи алфавита, включающего в себя 27 эмоций. Датасеты, подобные DREAMER[2487], ASCERTAIN[2488] и K-EmoCon[2489], содержат в себе данные, относящиеся к редким модальностям (например, включают в себя электроэнцефалограммы и электрокардиограммы). Датасет AffectNet содержит более миллиона изображений лиц (с опорными точками), размеченных при помощи 1250 эмоционально окрашенных тегов на шести разных языках: английском, немецком, испанском, португальском, арабском и фарси.
6.5.5 Современные достижения в анализе эмоций
Современные модели, предназначенные для распознавания эмоциональной окраски речи в аудиоканале, обычно представляют собой свёрточные или свёрточно-рекуррентные нейронные сети, получающие на вход различные представления звукового сигнала (спектрограммы, последовательности наборов мел-кепстральных коэффициентов и т. п.) и решающие задачу классификации или регрессии. В этом смысле они напоминают модели, предназначенные для решения других задач обработки человеческого голоса: определения пола и возраста говорящего, выявления ключевых слов или полнотекстового распознавания речи. Рассмотрим для примера одну из таких работ[2490], увидевшую свет в 2020 г. и установившую, по заявлению авторов, новые рекорды в точности распознавания эмоциональной окраски сразу для двух датасетов — RAVDESS и IEMOCAP (при этом результат на датасете EMO-DB лишь несущественно уступает наилучшему существующему решению).
Её авторы, исследователи Диас Исса, Мухаммед Фатих Демирджи и Аднан Языджи из Назарбаев Университета (Астана, Казахстан), представили новую архитектуру, в которой на вход нейронной сети подаются мел-кепстральные коэффициенты, хромаграмма (представление, напоминающее спектрограмму, с тем лишь отличием, что по оси y в хромаграмме отложены не диапазоны частот, а звуковысотные классы [pitch class] — классы, образуемые множеством всех звуковых высот, отстоящих друг от друга на целое число октав), мел-спектрограмма, а также два более хитрых представления — на основе так называемых спектральных контрастов и на основе тоннетца [Tonnetz].
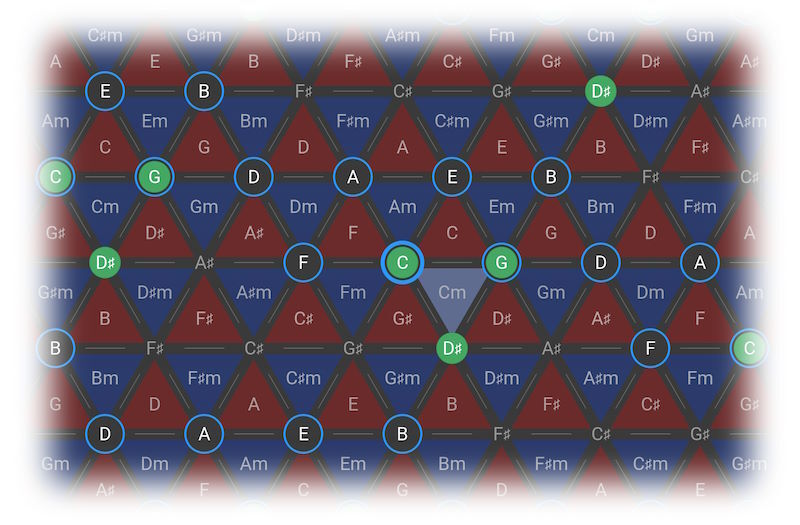
Термином «тоннетц» (от нем. Tonnetz — тоновая сеть), или эйлеровской звуковой сеткой, в теории музыки называют сетевую диаграмму, представляющую звуковысотную систему, задающую набор и возможную последовательность в музыкальном произведении звуковысотных классов. Узлы эйлеровской звуковой сетки соответствуют звуковысотным классам, а треугольники, объединяющие три соседних узла, соответствуют аккордам. В музыкальном произведении, принадлежащем к описываемой тоннетцем звуковысотной системе, друг за другом могут следовать только аккорды, соответствующие соседним треугольникам тоннетца.
Рис. 144. Тоннетц, или эйлеровская звуковая сетка
Тоннетц был впервые предложен[2491] Леонардом Эйлером в 1739 г., затем на долгое время забыт, затем переоткрыт в XIX в. и стал весьма популярен у музыкальных теоретиков — таких, например, как Риман и Эттинген.
В книге одно тянет за собой другое, и трудно понять, где следует остановиться. Что такое спектрограммы, мел-шкала и кепстр, мы более-менее подробно разобрали в разделах, посвящённых распознаванию и синтезу речи. Сведения о хромаграмме, в принципе, удалось вместить в одно вроде бы понятное предложение. Хуже обстоят дела с тоннетцем. Авторы рассматриваемой нами модели использовали функцию librosa.feature.tonnetz из популярной библиотеки для обработки звука Librosa в языке Python для получения соответствующего представления звука. Для описания работы этой функции нужно объяснять, что такое натуральный строй, равномерно темперированный строй, как тоновое пространство из плоскости становится сначала трубкой с нанизанной на её поверхность спиральной матрицей Чу, а потом и вовсе гипертором. И как 12-мерный вектор хромаграммы при помощи операции построения центроидов превращается в набор из шести координат представления, предложенного[2492] Хартом, Сэндлером и Гэссером и основанного на тоннетце Эйлера. Примерно так же дело обстоит и со спектральными контрастами[2493]. В общем, выглядит как бессмысленный экскурс в теорию музыки для тех, кому она не особо-то и нужна. Один из моих коллег (занимающийся среди прочего созданием моделей для распознавания эмоций), выслушав мои страдания, посоветовал написать так: «авторы считают сложные непонятные фичи из теории музыки».
Итак, авторы статьи берут хорошо известные нам фичи, а также ряд сложных и непонятных фичей из теории музыки, получают матрицу размерностью 193 × 1 (т. е. все спектральные представления строятся для всей фразы целиком; таким образом, фраза в итоге описывается набором из 193 чисел) и пихают её на вход свёрточной нейронной сети. Базовая топология сети, использованная авторами, содержит целых шесть слоёв свёртки (размер ядер везде 5 × 1), один слой максимизирующего пулинга (8 × 1), три слоя прореживания и один полносвязный слой.
Эта архитектура затем модифицируется авторами под каждую отдельную задачу путём модификации параметров прореживания, а также удаления некоторых слоёв. В случае с EMO‑DB авторы выделяют отдельные сети для выявления наиболее сложно распознаваемых эмоций, а также объединяют несколько моделей в ансамбли. Впрочем, с датасетом RAVDESS неплохо справляется и базовая архитектура. Вот так выглядит матрица ошибок [confusion matrix] для этого набора данных (авторы разделили все записи на обучающую и тестовую выборки в пропорции 80 : 20, ниже приведена матрица ошибок для тестовой выборки).