Листинг 10.3. Пример файла robots.txt
User-Agent: *
Disallow: /cgi-bin/
User-Agent: MyYandexServer Disallow:
Форматы индексируемых документов
Директивы, описывающие индексируемые форматы документов, являются необязательными для конфигурационного файла, но в ряде случаев могут оказаться полезными, например, при использовании нестандартных расширений индексируемых файлов. В том случае, если форматы все же прописаны в файле конфигурации, каждому из них должна соответствовать отдельная секция DocFormat. Секция описывает один из форматов подлежащих индексированию документов и используемый для его интерпретации парсер (анализатор содержимого документа).
Каждая секция DocFormat должна включать обязательную директиву MimeType. Также могут присутствовать необязательные директивы Extensions, Module, Symbol и Config. Директива MimeType задает произвольное имя документного формата, уникально идентифицирующее этот формат. Обычно в качестве идентификатора формата используется так называемый медиа-тип, значения которого специфицированы для большого количества форматов.
Директива Extensions задает расширения файлов данного формата. Если для получения содержимого документа используется файловая система, документы в файлах с заданными расширениями будут считаться имеющими медиатип, указанный в директиве MimeType. Тем не менее если для получения содержимого документа используется веб-сервер, возвращающий заголовок Content-type, в качестве медиа-типа используется значение этого заголовка. Пример секции DocFormat приведен в листинге 10.4.
Листинг 10.4. Пример секции DocFormat
<DocFormat>
MimeType text/html
Extensions.htm, html, asp
Config attr.cfg
</DocFormat>
Парсеры
Одно из важнейших свойств поисковой системы — возможность индексирования файлов произвольного формата. Это обеспечивается с помощью отдельных модулей — парсеров (еще их называют интерпретаторами форматов документов). Для каждого типа файлов применяется свой модуль. В платную версию поисковика включены парсеры для документов в форматах XML, RTF, PDF, MP3, FLASH, MS Word, MS Excel, MS PowerPoint, помимо входящих в стандартную поставку парсеров для форматов text/html и text/plain. Используя спецификацию, независимые разработчики могут разработать и иные парсеры, необходимые для используемых ими форматов данных, однако подключить их можно только к платной версии.
Из всех парсеров, поставляемых с программой, два являются конфигурируемыми. Это парсеры HTML и XML-документов. Остальные используются "как есть". В документации, входящей в комплект поставки, есть разделы, посвященные вопросам настройки парсеров под решение конкретных задач.
Внимание
На сайте Яндекса представлена программа mystem (http://company.yandex.ru/
technology/products/mystem/mystem.xml). Это — парсер, осуществляющий морфологический анализ текста на русском языке. Программа предназначена для некоммерческого использования.
У большинства типов документов есть своя внутренняя структура, определенные элементы которой несут свойственную лишь им смысловую нагрузку. В почтовых письмах это могут быть поля from, to, Subj, в вебдокументах — это заголовок, тело документа, ключевые слова. В теле могут присутствовать заголовки различных уровней, ссылки, картинки и т. д. Различные части структурированных таким образом документов в Яндексе называются зонами.
Основная задача парсера — выделить из документа нужный для индексирования текст. Текст, выделяемый парсером, может быть помечен как принадлежащий определенной зоне документа или как имеющий определенные свойства (атрибуты). На основании элементов форматирования документа парсер может указать границы предложений и абзацев, а также вес данного отрывка текста.
Разбиение документа на зоны происходит во время индексирования на основании меток, возвращаемых парсером. Впоследствии каждая зона может стать объектом независимого поиска (вспомните то, что мы уже говорили про поиск — поиск по заголовкам документов, заголовкам писем, адресатам, тегам и т. д.). Каждая поисковая зона имеет точки начала и конца в теле документа. Начало и конец зон всегда приходятся на границы слов.
Индексирование с учетом зон и их характеристик обеспечивает в дальнейшем возможность поиска с учетом нахождения требуемых сведений в определенных зонах. Это очень хорошо заметно на примере языка запросов, о котором мы поговорим, применительно к Яndex.Server, чуть позже.
10.1.2. Как группируются результаты
У документа, помимо данных, используемых для организации поиска, существуют дополнительные атрибуты. К ним можно отнести размер документа и время его создания, тип документа и принадлежность к определенному разделу сайта. Эти характеристики используются для сортировки и группировки результатов поиска. Значения этих атрибутов хранятся в специальном дополнительном файле и могут быть изменены без переиндексирования, но обязательно до начала выполнения поиска.
При формировании ответа на запрос всегда происходит выстраивание списка найденных документов. По умолчанию ранжирование выполняется по значению релевантности запросу. Однако бывает необходимо выполнить сортировку по дополнительным признакам, например, по типам документов или по датам. В этом случае сортировка будет выполняться по группировочным атрибутам. Например, новости можно сгруппировать по изданиям, опубликовавшим их, а документы — по разделу сайта, где они размещаются. Ограничение, накладываемое на группирование результатов, заключается в том, что группирование не может быть вложенным (т. е. нельзя сгруппировать уже сгруппированный список).
Однако для одного поискового запроса можно задать сразу несколько группировок, или вариантов структурирования результата. То есть можно получить не один "список найденного", а несколько, и каждый список будет соответствовать одной группировке. При этом способ сортировки результата поиска для всех вариантов может быть только один.
Параметры группировки
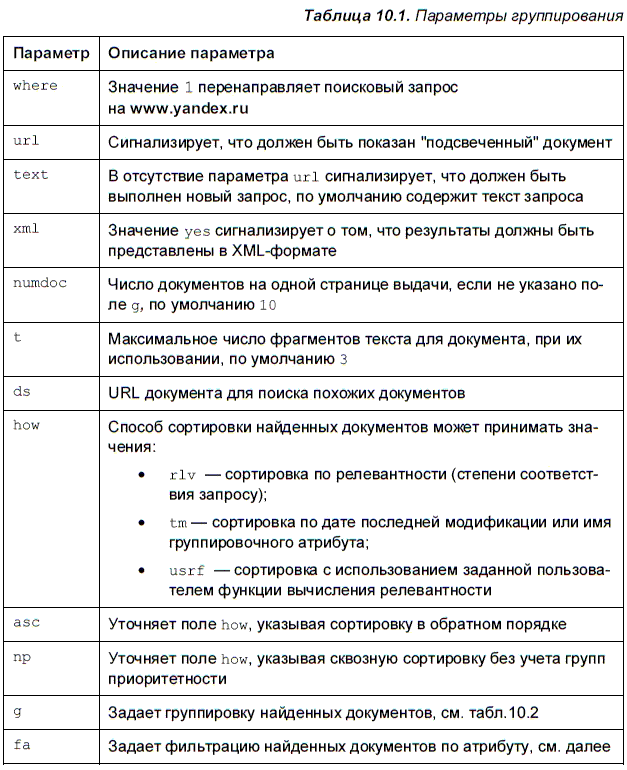
Для выполнения группировки или сортировки результатов в поле запроса требуется добавить определенные параметры, описанные в табл. 10.1.
Полей g может быть несколько — по числу необходимых группировок. Поле g имеет структуру mode.attr.ngrp.ndoc.cur, описанную в табл. 10.2. Необходимо помнить, что по умолчанию при выполнении запроса не делается никаких группировок. Для того чтобы получить ту или иную группировку, необходимо задать поле g. Группировка и сортировка происходят на этапе выполнения запроса, поэтому нельзя использовать функции работы с группами при построении выдачи, если до выполнения поиска не были заданы соответствующие поля.

Поле fa служит для фильтрации найденных документов по значениям указанных группировочных атрибутов. Такая фильтрация выполняется после выполнения поискового запроса, но до начала выполнения группировок. Использование поля fa для фильтрации результатов поиска по группировочным атрибутам предпочтительнее, чем использование поисковых атрибутов в поисковом запросе (если в индексе есть поисковые атрибуты с теми же названиями и числовыми значениями), так как работает быстрее. Поле fa может содержать несколько подвыражений, разделенных точкой с запятой. Каждое подвыражение состоит из названия атрибута, двоеточия и диапазона, в котором должен находиться указанный атрибут у прошедших фильтр документов. Диапазон указывается в виде двух чисел, разделенных дефисом. Если одно из задающих диапазон значений отсутствует, фильтр пройдут документы со значением атрибута, большим или меньшим указанного. Примеры поля fa: