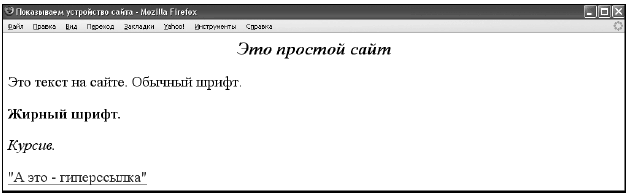
Приведем пример очень простого сайта (рис. 1).
Рис. 1. Пример сайта, как его видно в браузере Мозилла Файрфокс.
Наверху страницы, изображенной на рисунке, то есть не в тексте сайта, а на верхнем поле рамки страницы, рядом с круглым значком браузера, расположена надпись: «Показываем устройство сайта». Она находится в так называемом заголовке страницы (который заключен между открывающим тегом <TITLE> и закрывающим тегом </TITLE>). Обращаем ваше внимание на то, что это заголовок именно всей страницы, а не текста.
Посередине представленного рисунка жирным курсивом выведено: «Это простой сайт». Данная надпись – и есть заголовок текста. Шрифт фразы «Это простой сайт» по размеру превосходит шрифт текста на сайте, он специально выделен как заголовок текста. При разметке с помощью HTML этот текст расположен ниже тега <TITLE>, но при этом вместе с тегом <TITLE> находится внутри тега <Head>. То есть содержимое, заключенное в <TITLE>, – это часть того, что находится в <Head>. Такое расположение дает дополнительную возможность пауку лучше определять ключевые слова на сайте. Ведь если слова вынесены в заголовок текста или, тем более, всей страницы, вероятность того, что страница и текст посвящены теме, формулируемой этими словами, повышается.
Ниже фразы «Это простой сайт» приведены четыре варианта написания основного текста сайта:
– обычный;
– жирный (пишется под тегом <B>);
– курсив (пишется под тегом <i>);
– текстовая гиперссылка (пишется под тегом <A HREF=http://www.url. ru>«Текст гиперссылки»</A>).
Основной текст сайта, вне зависимости от того, каким вариантом шрифта он написан, располагается внутри тега <BODY>. Именно содержимое тега <BODY> представляет собой основной объект для паука и рассматривается им как текст страницы (собственно, это действительно текст страницы).
Чтобы увидеть внутреннюю разметку сайта, надо в браузере Мозилла Файрфокс навести курсор на любой незанятый текстом участок поля и нажать правую кнопку мыши. В всплывающем меню следует выбрать пункт «Просмотр исходного кода страницы».
Применительно к сайту, который мы рассматривали на рис. 1, этот исходный код будет выглядеть следующим образом:
<HTML>
<HEAD>
<TITLE>
Показываем устройство сайта:
</TITLE>
<CENTER>
<B><I>
<SPAN STYLE=«font-size: large»>Это простой сайт</SPAN>
</CENTER>
</B></I>
</HEAD>
<BODY>
<P>
Это текст на сайте. Обычный шрифт.
</P>
<P>
<B>
Жирный шрифт.
</B>
</P>
<P>
<I>
Курсив. </I>
</P>
<A HREF=http://www.url.ru>«А это – гиперссылка»</A>
</BODY>
</HTML>
Здесь можно увидеть все элементы, описанные нами выше. Кроме того, в исходном коде видны теги <P>, которые обеспечивают расположение текста в новой строке и с промежутком по отношению к тексту, расположенному в предыдущей строке.
Разметка HTML по умолчанию не предполагает переноса текста и его форматирования. Поэтому текст, не содержащий никаких тегов, воспроизводится подряд, но с соблюдением пробелов между словами. Для того чтобы текст оказался написан не просто в новой строке, а с промежутком относительно находящейся выше строки, используется, как мы уже показали, тег <P>, а для того, чтобы текст был написан в новой строке, но без промежутка между выше– и нижерасположенной строками, применяется тег <BR>.
Начало сайта, созданного с помощью разметки HTML, отмечено тегом <HTML>, а его окончание – тегом </HTML>.
Описание языков запросов различных поисковых машин
Язык запросов поисковой машины Яндекс
Лучшая, на наш взгляд, работа по изучению операторов поисковой машины Яндекс выполнена специалистом из Санкт-Петербурга Денисом Фурсовым. На его ресурсе[3] постоянно проводятся дополнительные исследования, отслеживаются и оцениваются изменения в работе операторов указанной поисковой машины.
Ниже речь пойдет о том, как с помощью специальных фильтров, основанных на Булевой алгебре, создавать запросы, максимально соответствующие потребностям специалиста, который ищет информацию в Интернете.
При изучении этого вопроса, не следует забывать, что компьютер очень исполнителен, но лишен способности думать, поэтому следует составлять запрос, исходя из того, что он будет обработан компьютером буквально, а не с учетом того, что же на самом деле имел в виду пользователь, создавая свое обращение.
Лучше всех эту мысль проиллюстрировал летом 2005 г. Алексей Амилющенко, главный аналитик отдела маркетинга Яндекса на следующем примере.
Вот еще одна история с семинаров, но ее приходится рассказывать не очень часто. Иногда случается, что заходит разговор о том, что хорошо бы поисковым системам учитывать не только слова, которые есть в индексируемых документах, но и смысл написанного. В ответ говорю, что знаю фразу, про которую и человек-то не скажет, о чем это. Вот она.
Эти типы стали есть в прокатном цехе.
И что тут написано? Я знаю, минимум, три разных смысла. Не подглядывайте в ответ
сразу (он ниже). Попробуйте сначала самостоятельно…
Обычно, когда это предложение видит зал, сначала становится тихо (видно, что думают),
потом начинаются смешки (до кого-то дошло), потом хихикают уже все.
Но к делу, что же здесь все-таки написано?
1. Скучный такой вариант.
Эти типы стали (варианты металлопроката) есть (имеются в наличии) в прокатном цехе.
2. Более творческий, с элементами мизантропии.
Эти типы (неприятные автору личности) стали (начали) есть (принимать пищу) в прокатном цехе.
3. Несколько надуманный, конечно, но…
Эти типы стали (варианты металлопроката) есть (надлежит принимать в пищу) в прокатном цехе.
Вот видите, даже протеиновые мозги не справляются, а вы хотите, чтобы у силиконовых это получалось.
Текст запроса мы будем помещать в квадратные скобки [] для того, чтобы визуально выделить его из текста книги. Если уважаемый читатель решит ввести приведенные ниже запросы в поисковую строку поисковой машины, чтобы проверить их работоспособность на практике, то эти квадратные скобки вводить не надо.
Итак, перейдем непосредственно к операторам запросов Яндекса.
1. Логическое «И».
Яндекс поддерживает три разных оператора, относящихся к логическому «И», что делает его самым гибким из всех поисковиков, работающих с русским языком. Столь развитая, практически уникальная система операторов поисковых запросов дает возможность предельно точно настроить запрос и сформировать такой фильтр для данных в Интернете, который максимально качественно выбирает нужную информацию и отсекает ненужную.
1.1. Пробел.
Слова, разделенные пробелом, должны располагаться недалеко друг от друга. Специалисты поясняют, что термин «недалеко» отнюдь не фиксированная величина и меняется в зависимости от того, с какими словами указанный оператор в каждом конкретном случае используется. Если они часто употребляются, то «недалеко» – значит, на расстоянии нескольких слов друг от друга. Если же они редко встречаются в обиходе, то даже их нахождение в разных концах документа будет восприниматься как «недалеко».
При этом, несмотря на то, что логическое «И» в общем виде Булевой алгебры подразумевает присутствие всех упомянутых слов, Яндекс, тем не менее, действительно выдает сначала те документы, в которых есть все ключевые слова, представленные в запросе. После чего начинает выдавать документы, в которых на одно ключевое слово меньше, чем в запросе, затем – на два слова меньше и так далее.