Некоторые виды информации устаревают или меняются столь стремительно, что пауки просто не в состоянии ее проиндексировать своевременно. При этом часто владельцы поисковых систем вообще не пускают спайдеров на такие страницы, дабы не тратить ресурсы на бесполезное занятие.
Примером такого контента может служить сайт о погоде в реальном масштабе времени.
2. Ресурсы состоят преимущественно из документов в таких форматах, которые не поддерживаются поисковыми машинами.
Как, скажем, страница, содержание которой ограничивается одним лишь изображением.
3. Содержимое страницы генерируется по запросу и формируется пошагово.
Примером в данном случае может служить ресурс, на котором осуществляется расчет цены автомобиля, в зависимости от комплектации и материала отделки салона. Для получения такой страницы пользователь пошагово заполняет формы на сайте, и конечный результат каждый раз формируется заново. Содержимое такой страницы не может быть проиндексировано по той простой причине, что без запроса страницы не существует, а заполнять формы паук не умеет.
4. Содержимое баз данных.
Результат из базы данных также появляется лишь после ввода определенного запроса в форму обращения к ней. Паук, как и в предыдущем случае, не может ни заполнить форму запроса, ни проиндексировать содержимое самой базы.
5. Страница не вводилась в форму добавления сайта, не вводилась ни в какие формы проверки рейтинга на поисковых системах и при этом на нее не ведут никакие ссылки.
Паук никоим образом не может узнать о существовании подобной страницы, а потому никогда ее не посетит.
Эти страницы, кстати, могут представлять большой интерес для конкурентной разведки, поскольку на практике известны случаи, когда на них содержались эксклюзивные предложения для некоторых клиентов. Информация такого рода ориентирована на целевые группы и выкладывается на сайте, клиентам же присылаются ссылки на нужные страницы. Последние представляют бесценную находку для компаний, работающих на рынках с высокой конкуренцией, поскольку содержат ответ на вопрос о том, по каким ценам соперник реально продает свою продукцию.
Мы сталкивались с ситуацией, когда компания смогла вычислить алгоритм составления адресов таких страниц конкурентом, после чего была долгое время в курсе всех его специальных предложений – до момента смены системного администратора конкурента.
Примеры поведения поисковой машины при посещении страницы в Интернете
Придя на страницу, паук первым делом определяет, есть ли на сайте что-либо, что его владелец запрещает индексировать.
Подобный запрет может быть реализован двумя способами. Первый заключается в том, что на сайте создается специальный файл robots.txt либо используется особый тег – так называемый, метатег <noindex>. В этот файл или под метатег «прячут» содержимое страницы, которое, по мнению владельца контента, не должно индексироваться поисковыми машинами.
Единственное отличие между ними состоит в том, что <noindex> работает на той странице, на которой он расположен, тогда как robots.txt может быть использован с целью предотвращения индексации любых отдельных страниц, групп файлов или даже всего веб-сайта.
По своей сути, никаких технических препятствий для индексирования содержимого ресурса этот способ не создает. Однако большинство поисковых машин с уважением относится к подобному способу защиты контента, который, как правило, не попадает в информационные системы. Наиболее близким аналогом столь действенного ограничения доступа в реальном мире можно считать таблички «м» и «ж» на дверях общественных уборных.
На наш взгляд, метод ограничения индексирования с помощью файла robots. txt или метатега <noindex> потому получил столь большое распространение, что он препятствует работе пауков, но не мешает людям просматривать содержимое страниц без каких-либо ограничений.
Второй способ охраны контента значительно надежнее первого и заключается в том, что страница защищается паролем. Паук технически неспособен вводить пароль. Однако и человек, прежде всего, должен этот пароль знать, а кроме того, ему необходимо потратить время и приложить усилия для того, чтобы его ввести. При такой защите ресурса работает уже не этический, а технический способ ограничения индексирования.
После того, как паук попал на страницу, которая не защищена паролем и не внесена в список запрещенных, события развиваются по-разному, в зависимости от того, что на этой странице находится. Рассмотрим возможные их варианты, а также попытаемся понять, к видимому или к невидимому Интернету эти варианты относятся (по Крису Шерману и Гэри Прайсу).
Вариант 1. Паук обнаруживает страницу, написанную в HTML и содержащую графические элементы.
В таком случае паук может проиндексировать лишь название графического файла, и тогда такой документ будет найден при поиске картинок по ключевому слову, совпадающему с тем, которое есть в названии. Если имя файла не имеет ничего общего с его наполнением, он не сможет быть найден поисковой машиной, даже если будет содержать фотографию с изображением ключевого слова.
Вариант 2. Паук внутри сайта столкнулся со страницей, которая написана на HTML, но содержит поля, требующие заполнения пользователем – например, ввода логина и пароля.
В этом случае есть техническая возможность индексирования содержимого, но только того, к которому имеется доступ. Спрятанная под пароль часть страницы не может быть просмотрена и, как следствие, не может быть проиндексирована спайдером.
Здесь наиболее часто встречаются два варианта. Первый: допустим, на сайте лежат готовые к просмотру страницы, на которые существуют ссылки в Интернете (например, фраза: «Я недавно интересную статью прочитал, она находится здесь:» – и далее следует прямой адрес статьи). В этом случае страница с формой, требующей заполнения, создана лишь для того, чтобы пользователь мог выбрать нужный ресурс из имеющихся. Текст на странице с формой будет виден пауку и проиндексируется, а сами страницы, на которые ведет форма, индексируются «в обход» процедуры ее заполнения, в другое время и, возможно, другим пауком, за счет ссылок на внутренние страницы сайта из других источников. В таком случае и страница с формой, и внутренние страницы будут относиться к видимому Интернету.
Во втором варианте форма собирает информацию, на основании которой впоследствии создается необходимая пользователю страница. То есть, никакой внутренней страницы просто не существует до тех пор, пока форма не будет заполнена. Паук этого сделать не может. Данные, которые находятся внутри такого сайта, не могут быть получены никаким иным путем, кроме как посредством заполнения формы, а потому всегда относятся к невидимому Интернету.
Вариант 3. Паук приходит на сайт, содержащий динамические данные, меняющиеся в реальном масштабе времени.
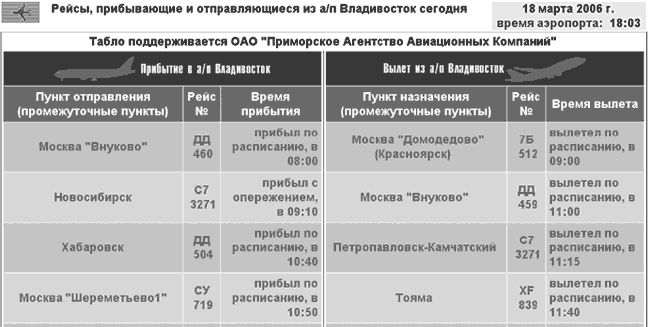
К таким сайтам относится биржевая информация или, скажем, сведения о прибытии авиарейсов (рис. 2). Эти ресурсы обычно причисляют к невидимому Интернету, но не потому, что их технически нельзя проиндексировать, а потому, что их индексация не имеет практического смысла.
Рис. 2. Пример мониторинга движения рейсов на сайте www.airagency.ru
Вариант 4. Паук попадает на страницу, которая содержит текст в формате, не поддерживаемом данной поисковой машиной.
Например, Рамблер, как мы уже говорили, не поддерживает документы Power Point (.ppt). Ряд поисковых машин не индексируют документы в Postscript-файлах (это формат, в котором могут сохраняться для передачи в типографию файлы, созданные в программе Microsoft Publisher). До недавнего времени к таким форматам относился и PDF, однако сначала Гугл, а за ним и остальные поисковые машины стали индексировать подобные документы. Первоначально ограничение в работе с PDF-файлами было обусловлено тем, что на каждый новый формат приходилось расходовать дополнительные средства, распространенность же PDF-файлов вначале была невелика. Однако, по мере того, как правительственные организации многих стран стали выкладывать в Интернет документы именно в этом формате, поисковые машины начали с ним работать.