Другие поисковые системы 1990-х имели шанс сделать то же самое, но не воспользовались им. Около 2000 года в Yahoo! разглядели этот потенциал, но идея осталась идеей. Именно Google распознал золотой песок в пустой породе своих взаимодействий с пользователями и позаботился о том, чтобы собрать его <…> Google использует информацию, образующуюся как побочный продукт взаимодействия с пользователем, или «выхлоп данных», который автоматически перерабатывается для улучшения существующих услуг или создания совершенно новых продуктов[134].
То, что рассматривалось как отходы производства – «выхлоп данных», оседающий на серверах Google во время работы поискового «движка», – быстро было переосмыслено как критический элемент превращения поисковой системы Google в процесс непрерывного самообучения и самосовершенствования.
На этой ранней стадии развития Google петля обратной связи, связанная с улучшением ее функций поиска, создавала нужный баланс сил: поиску требовались люди, на которых он мог бы учиться, а людям требовался поиск, который позволял им учиться. Благодаря этому симбиозу алгоритмы Google обучались и выдавали всё более релевантные и полные результаты поиска. Чем больше запросов, тем больше обучения; чем больше обучения, тем более релевантны результаты. Больше актуальности – больше поисков и больше пользователей[135]. К тому времени, когда молодая компания провела свою первую пресс-конференцию в 1999 году, чтобы объявить о покупке акций компании на 25 миллионов долларов со стороны двух наиболее уважаемых фирм венчурного капитала Кремниевой долины, Sequoia Capital и Kleiner Perkins, поиск Google уже обрабатывал по семь миллионов запросов в день[136]. Несколько лет спустя Хэл Вэриан, который в 2002 году пришел в Google в качестве главного экономиста, заметит:
Каждое действие, которое выполняет пользователь, считается сигналом, который нужно проанализировать и передать обратно системе[137].
Алгоритм Page Rank, названный в честь его основателя, уже давал Google значительное преимущество в определении наиболее популярных результатов для поисковой выдачи. Но в течение следующих нескольких лет именно сбор, хранение, анализ и изучение побочных продуктов этих поисковых запросов превратят Google в золотой стандарт веб-поиска.
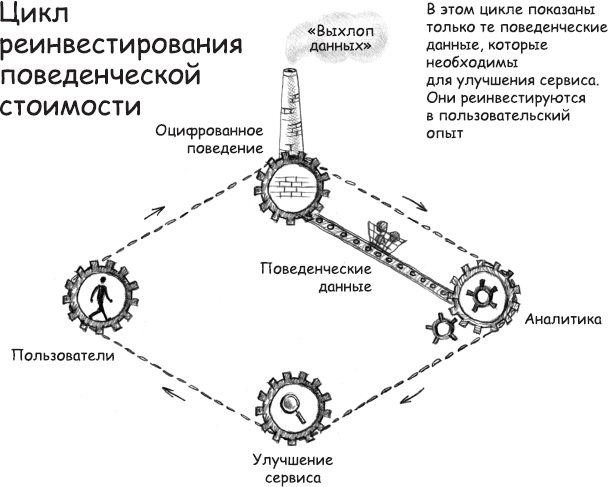
Здесь необходимо понимать одно важное отличие. В этот ранний период поведенческие данные работали на благо пользователя. Пользовательские данные бесплатно создавали ценность, и эта ценность реинвестировалась в пользовательский опыт в виде совершенствования качества услуг – улучшения, которые пользователи тоже получали бесплатно. Пользователи предоставляли сырье в форме поведенческих данных, и эти данные собирались для повышения скорости, точности и актуальности, а также для создания дополнительных продуктов, таких как перевод. Я называю это циклом реинвестирования поведенческой стоимости (или ценности), в котором все поведенческие данные реинвестируются в улучшение продукта или услуги (рис. 1).
Этот цикл повторяет логику iPod; в Google он работал прекрасно, но с одним важным отличием: отсутствием устойчивых рыночных трансакций. В случае с iPod цикл запускался покупкой высокоприбыльного материального продукта. Последующие взаимодействия улучшали iPod и вели к росту продаж этого продукта. Клиенты были субъектами коммерческого процесса, который стремился подстроиться под их запросы и дать «то, что я хочу, когда хочу и где хочу». В Google цикл был подобным же образом ориентирован на индивида как на свой субъект, но без материального продукта, который можно было продать, он парил над рынком, представляя собой взаимодействие с «пользователями», а не рыночные трансакции с клиентами.
РИС. 1. Цикл реинвестирования поведенческой стоимости
Это помогает объяснить, почему не следует думать о пользователях Google как о его клиентах: в его случае нет никакого экономического обмена, цены и прибыли. Не играют пользователи и роль наемных работников. Когда капиталист нанимает рабочих и обеспечивает их заработной платой и средствами производства, то продукты, которые они производят, принадлежат капиталисту, который может их продать и получить прибыль. Здесь дело обстоит не так. Пользователям не платят за их труд, и им не предоставляют средства производства (мы подробнее обсудим это позже в этой главе). Наконец, часто говорят, что пользователь является «продуктом». Это тоже неверно, и к этому вопросу мы вернемся еще не раз. Пока достаточно сказать, что пользователи – мы с вами – не продукты, а источники сырья. Как мы увидим, свои необычные продукты надзорный капитализм умудряется извлекать из нашего поведения, оставаясь безразличным к нашему поведению. Его продукты предназначены для связанных с нами предсказаний, но им все равно, что мы делаем и что с нами станет.
Подводя итог: на этом раннем этапе развития Google все то ценное, что пользователи поиска непреднамеренно отдавали компании, им же потом и возвращалось в виде улучшения услуг. В этом цикле реинвестирования предоставление пользователям потрясающих результатов поиска «съедало» всю ценность, которую создавали пользователи, предоставляя дополнительные поведенческие данные. Тот факт, что люди нуждались в Поиске не меньше, чем Поиск нуждался в людях, создавал равновесие сил между Google и его пользователями. С людьми обращались как с самоцелью, как с субъектами нерыночного, замкнутого цикла, который полностью соответствовал заявленной Google миссии «организовать информацию всего мира и сделать ее общедоступной и полезной».
III. Поиск капитализма: нетерпеливые деньги и чрезвычайное положение
К 1999 году, несмотря на весь блеск созданного Google нового мира доступных для поиска веб-страниц, несмотря на его растущие научно-исследовательские возможности и именитых инвесторов, никакого надежного способа превратить вложенные деньги в доходы не было. Цикл реинвестирования поведенческой стоимости привел к созданию превосходного поиска, но это был еще не капитализм. Из-за баланса сил, взимать с пользователей плату за поисковые услуги было финансово рискованным и, возможно, контрпродуктивным. Продажа результатов поиска также создала бы для компании опасный прецедент, назначив цену за индексированную информацию, которую поисковый робот Google уже собрал бесплатно у других. Без такого устройства, как iPod, или доступной для него цифровой музыки не было прибыли, не было излишка, не оставалось ничего такого, что можно было бы продать и превратить в источник дохода.
Реклама в Google была далеко не в почете: команда AdWords состояла из семи человек, большинство из которых разделяли неприязненное отношение учредителей к рекламе. Тон задали Сергей Брин и Ларри Пейдж в эпохальном докладе «Анатомия крупномасштабной гипертекстовой поисковой системы в интернете» на конференции World Wide Web 1998 года, в котором они представили свою концепцию поисковой системы:
Мы ожидаем, что поисковые системы, финансируемые за счет рекламы, будут неизбежно предвзяты в пользу рекламодателей и в ущерб нуждам потребителей. Этот тип предвзятости очень трудно обнаружить, но он все же может оказать существенное влияние на рынок <…> мы считаем, что проблема рекламы создает слишком много смешанных стимулов, поэтому крайне важно иметь конкурентную поисковую систему, которая была бы прозрачной и соответствовала академическим стандартам[138].
Но свою первую прибыль Google начал получать, предоставляя исключительные лицензии на использование веб-сервисов таким порталам, как Yahoo! и японскому BIGLOBE[139]. Небольшую прибыль приносили и спонсирование рекламных объявлений, связанных с ключевыми словами поискового запроса[140]. Существовали и другие модели. Соперничающие с Google поисковые системы, такие как Overture, используемая только гигантским тогда порталом AOL, или Inktomi, поисковая система, принятая Microsoft, брали плату с сайтов, страницы которых они индексировали. Overture также преуспела в привлечении онлайн-рекламы благодаря тому, что позволяла рекламодателям оплачивать высокие места в списке результатов поиска – тот самый формат, который презирали Брин и Пейдж[141].