expr: NUMBER { $$ = $1; }
$1
— значение, вырабатываемое при распознавании
NUMBER
, и оно же является результирующим значением
expr
. В данном случае присваивание
$$ = $1
может быть опущено, так как
$$
всегда принимает значение
$1
(если не устанавливается явно каким либо иным образом). В следующей строке с правилом
expr: expr '+' expr { $$ = $1 + $3; }
результирующее значение
expr
является суммой двух компонентов, тоже
expr
. Отметим, что
$2
соответствует
'+'
т.е. каждый компонент пронумерован.
Строкой выше выражение, за которым следует символ перевода строки (
'\n'
), распознается как
список, и печатается его значение. Если за такой конструкцией следует конец входного потока, процесс разбора завершается правильно. Список может быть пустой строкой; так учитываются пустые входные строки.
Формат входного потока для
yacc
— произвольный. Наш формат рекомендуется как стандартный.
В этой реализации процесс распознавания или разбора входного потока приводит к немедленному вычислению выражения. В более сложных решениях (включая
hoc4
и его последующие версии) процесс разбора порождает код для дальнейшего выполнения.
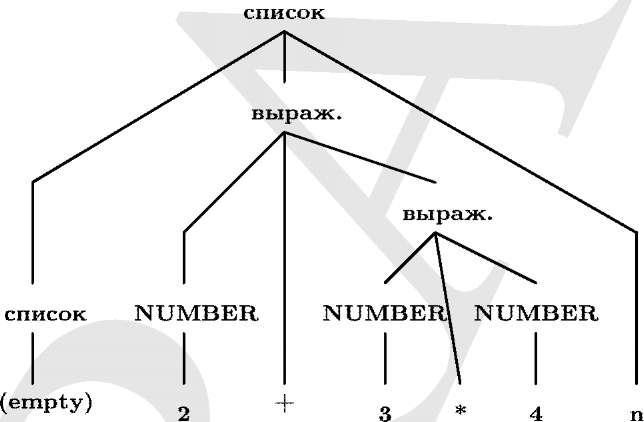
Наглядно представить разбор вам поможет рис. 8.1, где изображено дерево разбора. Кроме того, вы должны знать, как вычисляются значения и как они распространяются от листьев к корню дерева.
Рис. 8.1: Дерево разбора для 2 + 3*4
Реально значения не полностью разобранных правил хранятся в стеке и через стек передаются от одного правила к следующему. Обычно данные в стеке имеют целый тип, но поскольку мы в своей работе используем числа с плавающей точкой, необходимо переопределить значение по умолчанию. Определение
#define YYSTYPE double
устанавливает двойную точность для типа данных стека.
Теперь перейдем к описанию синтаксических классов, распознаваемых лексическим анализатором, если только они не являются литералами, состоящими из одного символа вида
'+'
и
'-'
. Описание
%token
специфицирует одни или несколько таких объектов. При необходимости можно задать левую или правую ассоциативность, используя
%left
или
%right
вместо
%token
.
(Левая ассоциативность означает, что
a-b-с
будет разбираться как
(а - b) - с
, а не
а - (b - с)
.) Приоритет устанавливается порядком появления операции: лексемы из одного определения имеют один и тот же приоритет, а лексемы, специфицированные позднее, — более высокий. Таким образом, в грамматике может быть неоднозначность (т.е. для некоторых входных потоков существует несколько способов разбора), но дополнительная информация в определениях разрешает эту неоднозначность.
Вторую половину файла
hoc.y
составляют процедуры:
/* Продолжение hoc.y */
#include <stdio.h>
#include <ctype.h>
char *progname; /* for error messages */
int lineno = 1;
main(argc, argv) /* hoc1 */
char *argv[];
{
progname = argv[0];
yyparse();
}
Функция main обращается к
yyparse
для разбора входного потока. Переход в цикле от одного выражения к другому происходит в рамках грамматики с помощью последовательности правил вывода для
списка. Приемлемо также обращаться в цикле к
yyparse
из функции
main
, если действия для списка предполагают печать значения и немедленный возврат.
Функция
yyparse
в свою очередь многократно обращается за лексемами из входного потока к функции
yylex
. Наша функция
yylex
проста: в ее задачи входят пропуск пробелов и символов табуляции, преобразование цифровых строк в числовое значение и подсчет входных строк для вывода сообщений об ошибках. Поскольку грамматика допускает только
+
,
-
,
*
,
/
,
(
,
)
и
\n
, при появлении любого другого символа
yyparse
выдает сообщение об ошибке. Получение 0 означает для
yyparse
"конец файла".
/* Продолжение hoc.y */
yylex() /* hoc1 */
{
int с;
while ((c=getchar()) == ' ' || с == '\t')
;
if (c == EOF)
return 0;
if (c == '.' || isdigit(c)) {
/* number */
ungetc(c, stdin);
scanf("%lf", &yylval);
return NUMBER;
}
if (c == '\n')
lineno++;
return с;
}
Переменная
yylval
используется для связи между синтаксическим и лексическим анализаторами; она определена в
yyparse
и имеет тот же тип, что стек
yacc
. Функция
yylex
возвращает
тип лексемы, равно как и ее функциональное значение, и приравнивает
yylval
значению лексемы (если оно есть). Например, число с плавающей точкой имеет тип
NUMBER
и значение, скажем, 12.34. Для некоторых лексем, прежде всего состоящих из одного символа, таких, как
'+'
или
'\n'
, в грамматике используется только тип. В этом случае
yylval
не нужно определять.