2. Послать сообщение. Клиентский процесс запрашивает эту услугу, посылая сообщение вызовом
MsgSend*()
, и переходит в блокированное состояние со статусом SEND. Переход осуществляется обычно на очень короткое время, пока сервер не примет его сообщение и не начнет обработку. Как только сервер принимает посланное сообщение, он разблокируется и меняет статус с RECEIVE на READY. Сервер начинает обработку полученного сообщения, а статус блокировки клиентского процесса меняется на REPLY.
3. Ответить на полученное сообщение. Завершив обработку полученного на предыдущем шаге сообщения, сервер выполняет вызов группы
MsgReply*()
для передачи запрошенного результата ожидающему клиенту. После этого вызова клиент, блокированный на вызове
MsgSend*()
со статусом REPLY, разблокируется (переходит в состояние READY). После выполнения
MsgReply*()
сервер также переходит в состояние READY. Однако чаще всего сервер снова входит в блокированное состояние на вызове
MsgReceive*()
, поскольку его работа организована как бесконечный цикл.
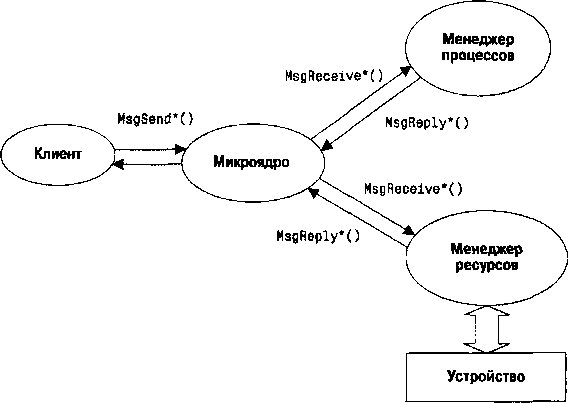
Рис. 5.1. Обмен сообщениями микроядра и менеджер ресурсов
Уже из этого поверхностного описания понятно, что передача сообщений микроядра — это не только средство взаимодействия процессов с обменом данными, но и крайне гибкая система синхронизации всех участников взаимодействия.
Могут возникнуть вопросы: Это один из низкоуровневых механизмов (существуют ли другие нативные механизмы?), на которых базируется ОС QNX? Какое это может иметь отношение к взаимодействиям на уровне POSIX API? Самое прямое! Все традиционные вызовы POSIX (
open()
,
read()
, … и все другие) реализованы в ОС QNX как обмен сообщениями, который только «камуфлируется» под стандарты техникой использования менеджеров ресурсов, о которых разговор еще впереди.
Технология обмена сообщениями микроядра хорошо описана [1] и требует для своего понимания и освоения тщательного изучения. В этой же главе, посвященной совершенно другим предметам, мы не будем детально описывать эту технологию.
Остановимся только на одном обстоятельстве: адресат получателя, которому направляется каждое сообщение, определяется при начальном установлении идентификатора соединения (coid — connect ID) вызовом:
#include <sys/neutrino.h>
int ConnectAttach(int nd, pid_t Did, int chid,
unsigned index, int flags);
Адрес назначения (сервера) в этом вызове определяется триадой {ND/PID/CHID}, где:
nd
— идентификатор сетевого узла. Мы не станем углубляться в идентификацию сетевых узлов сети QNET. Возьмем на заметку лишь тот факт, что обмен сообщениями с одинаковой легкостью осуществляется как с процессом на локальном узле (nd = 0), так и на любом другом сетевом узле.
pid
— PID процесса-сервера, с которым производится соединение.
chid
— идентификатор канала, который открыл процесс с указанным PID, выполнив предварительно
ChannelCreate()
, и к которому устанавливается соединение вызовом
ConnectAttach()
.
Выше мы неоднократно отмечали, что с процессом как с пассивной субстанцией, вообще говоря, невозможно обмениваться сообщениями. Хотя в адресной триаде обмена фигурирует именно PID процесса! Это обстоятельство не меняет положения вещей: именно адресная компонента CHID и определяет тот поток (часто это может быть главный поток приложения), с которым будет осуществляться обмен сообщениями, a PID определяет то адресное пространство процесса, в которое направляется сообщение, адресованное CHID.
Детальнее это выглядит так: в коде сервера именно тот поток, который выполнит
MsgReceive*(chid, ...)
, и будет заблокирован в ожидании запроса от клиента
MsgSend*()
. Аналогично и в коде клиента вся последовательность выполнения блокировок, обозначенная выше, будет относиться именно к потоку, выполняющему последовательные операции:
coid = ConnectAttach(... , chid, ...);
MsgSend*(coid, ...);
Содержимое двух предыдущих абзацев ни одной буквой не противоречит и не отменяет положения традиционного изложения [1] технологии обмена сообщениями микроядра. Тогда зачем же мы даем именно такую формулировку? Для того чтобы акцентировать внимание на том, что все блокированные состояния и их освобождение имеют смысл относительно потоков (и только потоков!), которые выполняют последовательность операций
MsgSend*()
—
MsgReceive*()
—
MsgReply*()
(даже если это единственный поток — главный поток приложения, и тогда мы говорим о блокировании процессов). Проиллюстрируем сказанное следующим приложением (
файл n1.cc):
Обмен сообщениями и взаимные блокировки
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <inttypes.h>
#include <errno.h>
#include <iostream.h>
#include <pthread.h>
#include <signal.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
static const int TEMP = 500; // темп выполнения приложения
static int numclient = 1; // число потоков клиентов
// многопотоковая версия вывода диагностики в поток:
iostream& operator <<(iostream& с, char* s) {
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&mutex);
c << s << flush;
pthread_mutex_unlock(&mutex);
return c;
}
static uint64_t tb; // временная отметка начала приложения
// временная отметка точки вызова:
inline uint64_t mark(void) {
// частота процессора:
const static uint64_t cps =
SYSPAGE_ENTRY(qtime)->cycles_per_sec;