Собственные данные потока
Описанной выше схеме общих данных приложения и локальных данных потока, достаточных для большинства «ординарных» приложений, все-таки определенно не хватает гибкости, покрывающей все потребности. Поэтому в расширениях POSIX реального времени вводится третий специфичный механизм создания и манипулирования с данными в потоке — собственные данные потока (thread-specific data). Использование собственных данных потока — самый простой и эффективный способ манипулирования данными, представленными индивидуальными экземплярами данных для каждого потока.
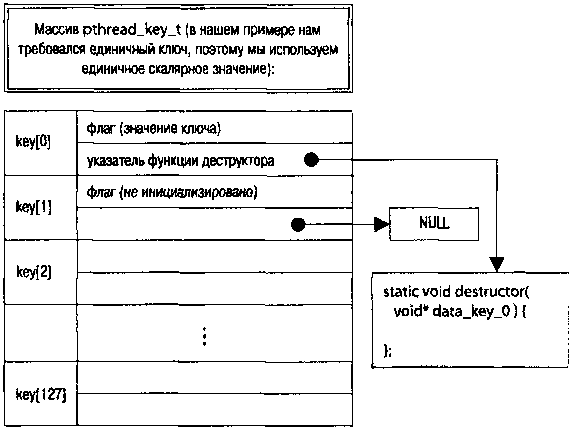
Согласно POSIX операционная система должна поддерживать ограниченное количество объектов собственных данных (POSIX.1 требует, чтобы этот предел не превышал128 объектов на каждый процесс). Ядром системы поддерживается массив из этого количества ключей (тип
pthread_key_t
; это абстрактный тип, и стандарт предписывает не ассоциировать его с некоторым значением, но реально это небольшие целые значения, и в таком виде вся схема гораздо проще для понимания). Каждому ключу сопоставлен флаг, отмечающий, занят этот ключ или свободен, но это внутренние детали реализации, не доступные программисту. Кроме того, при создании ключа с ним может быть связан адрес функции деструктора, которая будет вызываться при завершении потока и уничтожении его экземпляра данных (рис. 2.4).
Рис. 2.4. Ключи экземпляров данных
Когда поток вызывает
pthread_key_create()
для создания нового
типасобственных данных, система разыскивает первое незанятое значение ключа и возвращает его значение (0...127). Для каждого потока процесса (в составе описателя потока) хранится массив из 128 указателей (
void*
) блоков собственных данных, и по полученному ключу поток, индексируя этот массив, получает доступ к своему экземпляру данных, ассоциированных со значением ключа. Начальные значения всех указателей блоков данных -
NULL
, а фактическое размещение и освобождение блоков данных выполняет пользовательская программа (рис. 2.5).
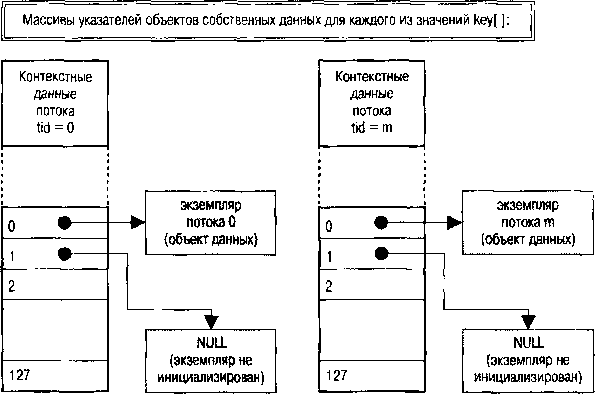
Рис. 2.5. Поток и его собственные данные
На рис. 2.5 представлен массив структур, создаваемый в единичном экземпляре для каждого процессабиблиотекой потоков. Каждый элемент ключа должен быть предварительно инициализирован вызовом
pthread_key_create()
(однократно для всего процесса). Каждый инициализированный элемент массива определяет объекты единого класса во всех использующих их потоках, поэтому для них здесь же определяется деструктор (это в терминологии языка С!). Деструктор — единый для экземпляров данных в каждом потоке. Даже для инициализированного и используемого ключа в качестве деструктора может быть указан
NULL
, при этом никакие деструктивные действия при завершении потока не выполняются.
После размещения блока программа использует вызов
pthread_setspecific()
. Для связывания адреса своего экземпляра данных с элементом массива указателей, индексируемого ключом. В дальнейшем каждый поток использует
pthread_getspecific()
для доступа именно к своему экземпляру данных. Это схема, а теперь посмотрим, как она работает.
Положим, что нам требуется создать
N
параллельно исполняющихся идентичных потоков (использующих единую функцию потока), каждый из которых предполагает работать со своей копией экземпляра данных типа
DataBlock
:
class DataBlock {
~DataBlock() { ... }
...
};
void* ThreadProc(void *data) {
// ... здесь будет код, который мы рассмотрим
return NULL;
}
...
for (int i = 0; i < N; i++)
pthread_create(NULL, NULL, &ThreadProc, NULL);
Последовательность действий потока выглядит следующим образом:
1. Поток запрашивает
pthread_key_create()
— создание ключа для доступа к блоку данных
DataBlock
. Если потоку необходимо иметь несколько (m) блоков собственных данных различной типизации (и различного функционального назначения):
DataBlock_1
,
DataBlock_2
…
DataBlock_m
, то он запрашивает значения ключей соответствующее число раз для каждого типа (
m
).
2. Неприятность здесь состоит в том, что запросить значение ключа для
DataBlock
должен только первый пришедший к этому месту поток (когда ключ еще не распределен). Последующие потоки, достигшие этого места, должны только воспользоваться ранее распределенным значением ключа для типа
DataBlock
. Для разрешения этой сложности в систему функций собственных данных введена функция
pthread_once()
.
3. После этого каждый поток (как создавший ключ, так и использующий его) должен запросить по
pthread_getspecific()
адрес блока данных и, убедившись, что это
NULL
, динамически распределить область памяти для своего экземпляра данных, а также зафиксировать по
pthread_setspecific()
этот адрес в массиве экземпляров для дальнейшего использования.
4. Дальше поток может работать с собственным экземпляром данных (отдельный экземпляр на каждый поток), используя для доступа к нему
pthread_getspecific()
.
5. При завершении любого потока система уничтожит и его экземпляр данных, вызвав для него деструктор, который был установлен вызовом
pthread_key_create()
, единым для всех экземпляров данных, ассоциированных с этим значением ключа.
Теперь запишем это в коде, заодно трансформировав в новую функцию
ThreadProc()
код ранее созданной версии этой же функции
SingleProc()
для исполнения в одном потоке, не являющийся реентерабельным и безопасным в многопоточной среде. (О вопросах реентерабельности мы обязательно поговорим позже.)
void* SingleProc(void *data) {
static DataBlock db( ... );
// ... операции с полями DataBlock
return NULL;
}
Примечание
To, что типы параметров и возвращаемое значение
SingleProc()
«подогнаны» под синтаксис ее более позднего эквивалента
ThreadProc()
, не является принципиальным ограничением - входную и выходную трансформации форматов данных реально осуществляют именно в многопоточном эквиваленте. Нам здесь важно принципиально рассмотреть общую формальную технику трансформации нереентерабельного кода в реентерабельный.