Очевидно, что личное восприятие риска отличается от его научной оценки. Эксперты по оценке риска судят о риске на основе данных о ежегодной смертности; события, вызывающие наибольшее количество смертей, расцениваются как самые рискованные. Например, эксперты сочли автотранспорт источником большего риска, чем использование ядерной энергии (поскольку в автокатастрофах погибает больше людей), в то время как выборки, составленные из студентов колледжей и членов Лиги женщин-избирателей, посчитали ядерную энергию источником большего риска (так как катастрофы, связанные с ее использованием, могут иметь ужасающие воображение последствия).
Главная трудность при интерпретации маловероятных рисков, таких как наводнения или ядерные аварии, состоит в том, что статистические данные о них трудны для осмысления. Трудно соотнести с собственной жизнью тот факт, что конкретное связанное с риском событие случается с одним из 10 000 человек. Нам необходимо так переформулировать эту информацию, чтобы она отвечала на вопрос: «Насколько вероятно, что это случится со мной?» Один из предлагаемых способов осмысления такого рода информации состоит в том, чтобы перевести все подобные риски в стандартные единицы «риска в час» (Slovic, Fischoff, Lichtenstein, 1986). Предположим, например, вы узнаете, что риск, связанный с поездкой на мотоцикле, равен риску, который связан с пребыванием в 75-летнем возрасте в течение одного часа. Поможет ли подобная информация осмысленно интерпретировать риск, связанный с поездкой на мотоцикле? Хотя она может принести пользу при оценке сравнительного риска (поездка на мотоцикле по сравнению с полетом на дельтаплане), сама по себе такая информация бесполезна, поскольку понять, что подразумевается под риском пребывания в 75-летнем возрасте в течение одного часа, все равно трудно.
В качестве избирателей и потребителей мы постоянно сталкиваемся с необходимостью принятия решений по огромному количеству самых разных проблем, включающих в себя использование ядерной энергии, радиационное заражение пищевых продуктов, хирургические операции, качество воды и воздуха, применение лекарств. Для принятия обоснованного решения всегда необходимо тщательное рассмотрение информации, касающейся оценки риска, связанного с данным решением (например, исторические данные, аналогичные риски и риски, связанные с отдельными компонентами), а также понимание факторов, приводящих к тенденциозности при субъективной оценке риска.
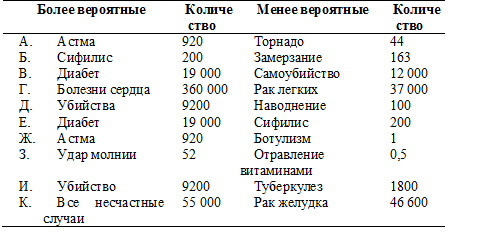
Ниже приводятся ответы на заданные выше вопросы о вероятностях причин смерти, сопровождающиеся действительными частотностями каждой причины (количество смертей на 100 000 000 человек). Проверьте свои ответы и выясните, не сделали ли вы общих ошибок, переоценив события, которые касаются большого количества людей одновременно и лучше запоминаются (такие, как авиакатастрофы), и недооценив те риски, которые мы считаем управляемыми (такие, как вождение автомобиля).
Использование статистики и возможные ошибки, возникающие при этом
Существует три вида лжи: просто ложь, гнусная ложь и статистика.
Дизраэли (1804-1881)
Когда мы хотим узнать что-нибудь о группе людей, часто бывает невозможно или неудобно спрашивать об этом всех членов группы. Предположим, что вы хотите выяснить, действительно ли доноры, сдающие кровь для Красного Креста, как правило, добрые и благородные люди. Поскольку вы не можете обследовать всех, кто сдает кровь, чтобы определить, насколько они добры и заботливы, вы обследуете только часть этого контингента, которая называется выборкой. Количественные показатели, рассчитанные на выборке людей, называется статистическими данными. (Статистикой также называется область математики, которая использует теорию вероятностей для принятия решений о контингентах.) Статистические данные встречаются в любой сфере жизни – от средних результатов игроков в бейсбол до величины военных потерь. Многие люди вполне справедливо относятся к статистике подозрительно. Хафф (Huff, 1954) написал небольшую книжечку, в которой приводятся юмористические примеры статистических ошибок. Книга носит название «Как лгать с помощью статистики» (How to Lie With Statistics). В этой книге есть такая зарифмованная мысль: «Статистика умело грим наложит – немного пудры и немного краски – и факты на себя уж не похожи. Я отношусь к статистике с опаской» (р. 9).
О среднем
Если сказать, что в средней американской семье 2,1 ребенка, то что это будет означать? Это число было получено путем создания выборки из американских семей, подсчета общего количества детей в этих семьях и деления на количество семей в выборке. Это число может дать весьма точное представление о том, что в американских семьях примерно по два ребенка – в некоторых больше, а в некоторых меньше, а может и ввести нас в заблуждение. Возможно, что в половине семей совсем не было детей, а в другой половине было по четыре ребенка или даже больше, а читатель будет ошибочно считать, что в большинстве семей «примерно» два ребенка, в то время как на самом деле нет ни одной такой семьи. Эта ситуация напоминает человека, который держит голову в духовке, а ноги в холодильнике и говорит, что в среднем он чувствует себя вполне комфортно. Не исключено также, что выборка, использованная для получения этого статистического показателя, не репрезентативна для контингента – в данном случае для всех американских семей. Если выборка состояла из студентов колледжей или жителей Манхэттена, то полученный результат завышен. С другой стороны, если в выборку вошли жители сельских районов, то полученный результат занижен. Если выборки не отражают особенности контингента, то их называют нерепрезентативными выборками. Статистические данные, рассчитанные на таких выборках, не дают точной информации о контингенте.
Средние значения тоже могут вводить нас в заблуждение, поскольку существует три различных вида средних значений. Предположим, что у миссис Вонг пятеро детей. Старшая дочь сделала успешную карьеру и занимает пост управляющего большой корпорацией. Она зарабатывает $500 000 в год. Вторая дочь – учительница и зарабатывает $25 000 в год. Третий сын работает официантом и получает $15 000 в год. Оставшиеся дети – безработные артисты, получающие по $5000 в год. Если миссис Вонг хочет похвастаться, как хорошо живут ее дети, она может подсчитать среднее арифметическое их доходов, которое называют еще средним значением. Когда люди думают о средних показателях, они, как правило, имеют в виду среднее арифметическое. Это сумма всех значений, поделенная на число слагаемых. Средний доход детей миссис Вонг равен $550 000: 5 = $110 000. Конечно, любой человек, услышав такую цифру, заключит, что у миссис Вонг очень успешные и состоятельные дети.
Средний доход детей миссис Вонг получился таким высоким из-за того, что в сумму входит одно очень большое слагаемое, в результате чего среднее значение возросло. Средние значения также называют оценками с тяготением к центру. Второй тип оценок с центральной тенденцией – это медиана, или срединное значение. На него не влияет наличие нескольких экстремальных значений величины. Чтобы найти медиану, значения выстраиваются в порядке возрастания или убывания. Значение, оказавшееся в середине ряда, и является медианой. Для примера с доходами детей миссис Вонг это будет выглядеть так:
$5000; $5000; $15 000, $25 000, $500 000
Средним значением, или медианой, будет третье значение, или $15 000. Таким образом, миссис Вонг могла бы также заявить, что ее дети зарабатывают в среднем по $15 000. (Когда число значений четное, медиана равна среднему арифметическому двух срединных значений.)