Это идентично тому, что мы вывели в предыдущем разделе. Но вместо того чтобы суммировать все примеры в наборе данных, мы обобщаем все примеры из текущего мини-пакета.
Переобучение и наборы данных для тестирования и проверки
Одна из главных проблем искусственных нейросетей – чрезвычайная сложность моделей. Рассмотрим сеть, которая получает данные от изображения из базы данных MNIST (28×28 пикселов), передает их в два скрытых слоя по 30 нейронов, а затем в слой с мягким максимумом из 10 нейронов. Общее число ее параметров составляет около 25 тысяч. Это может привести к серьезным проблемам. Чтобы понять почему, рассмотрим еще один упрощенный пример (рис. 2.8).
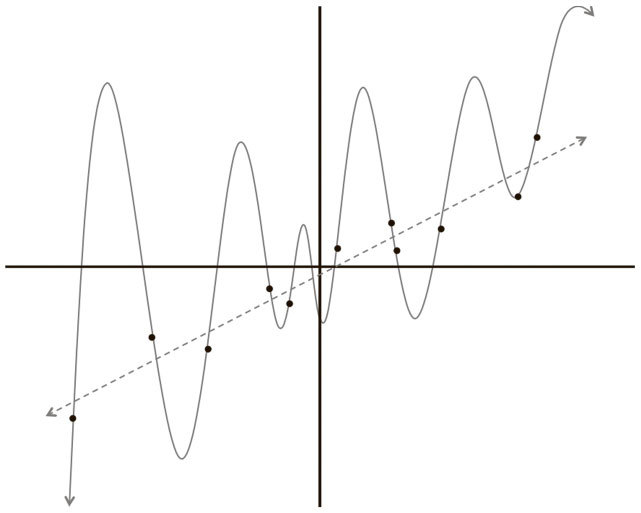
Рис. 2.8. Две модели, которыми может быть описан наш набор данных: линейная и многочлен 12-й степени
У нас есть ряд точек на плоской поверхности, задача – найти кривую, которая наилучшим образом опишет этот набор данных (то есть позволит предсказывать координату y новой точки, зная ее координату x). Используя эти данные, мы обучаем две модели: линейную и многочлен 12-й степени. Какой кривой стоит доверять? Той, которая не попадает почти ни в один обучающий пример? Или сложной, которая проходит через все точки из набора? Кажется, можно доверять линейному варианту, ведь он кажется более естественным. Но на всякий случай добавим данных в наш набор! Результат показан на рис. 2.9.
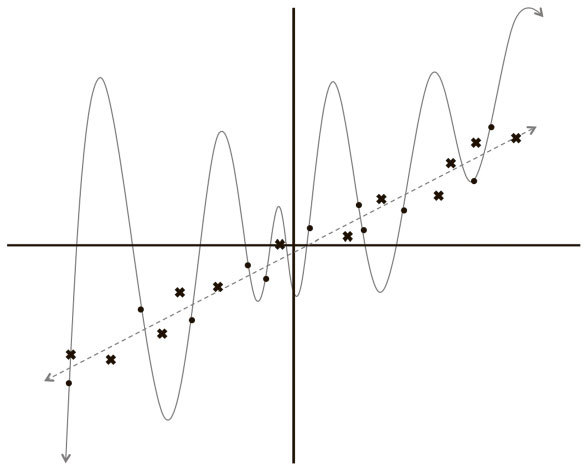
Рис. 2.9. Оценка модели на основе новых данных показывает, что линейная модель работает гораздо лучше, чем многочлен 12-й степени
Вывод очевиден: линейная модель не только субъективно, но и количественно лучше (по показателю квадратичной ошибки). Но это ведет к очень интересному выводу по поводу усвоения информации и оценки моделей машинного обучения. Строя очень сложную модель, легко полностью подогнать ее к обучающему набору данных. Ведь мы даем ей достаточно степеней свободы для искажения, чтобы вписаться в имеющиеся значения. Но когда мы оцениваем такую модель на новых данных, она работает очень плохо, то есть слабо обобщает. Это явление называется переобучением. И это одна из главных сложностей, с которыми вынужден иметь дело инженер по машинному обучению. Нейросети имеют множество слоев с большим числом нейронов, и в области глубокого обучения эта проблема еще значительнее. Количество соединений в моделях составляет миллионы. В результате переобучение – обычное дело (что неудивительно).
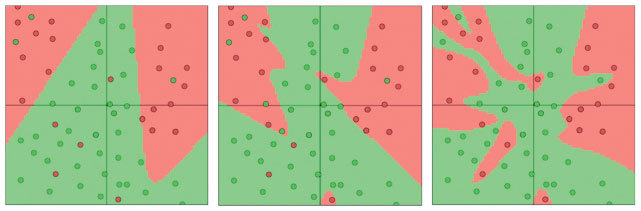
Рассмотрим, как это работает в нейросети. Допустим, у нас есть сеть с двумя входными значениями, выходной слой с двумя нейронами с функцией мягкого максимума и скрытый слой с 3, 6 или 20 нейронами. Мы обучаем эти нейросети при помощи мини-пакетного градиентного спуска (размер мини-пакета 10); результаты, визуализированные в ConvNetJS, показаны на рис. 2.10[12].
Рис. 2.10. Визуализация нейросетей с 3, 6 и 20 нейронами (в таком порядке) в скрытом слое
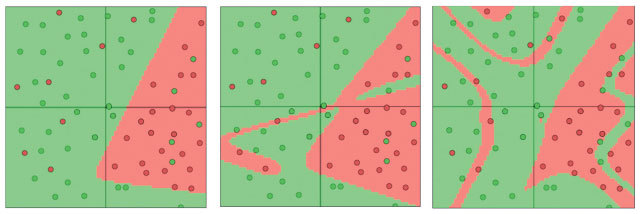
Уже из этих изображений очевидно, что с увеличением числа соединений нейросети усиливается тенденция к переобучению. Усугубляется она и с углублением нейросетей. Результаты показаны на рис. 2.11, где используются сети с 1, 2 или 4 скрытыми слоями, в каждом из которых по 3 нейрона.
Рис. 2.11. Визуализация нейросетей с 1, 2 и 4 скрытыми слоями (в таком порядке), по 3 нейрона в каждой
Отсюда следуют три основных вывода. Во-первых, инженер по машинному обучению всегда вынужден искать компромисс между переобучением и сложностью модели. Если модель недостаточно сложна, она может оказаться недостаточно мощной для извлечения всей полезной информации, необходимой для решения задачи. Но если она слишком сложна (особенно когда у нас есть ограниченный набор данных), высока вероятность, что понадобится переобучение. Глубокое обучение связано с решением очень сложных задач при помощи сложных моделей, поэтому необходимо принимать дополнительные меры против возможного переобучения. О многих из них мы будем говорить в этой главе, а также в следующих.
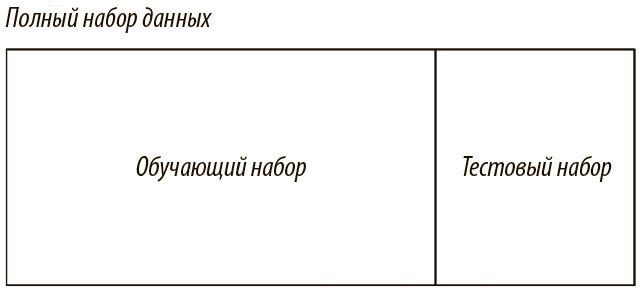
Во-вторых, неприемлемо оценивать модель на основе данных, с помощью которых мы ее обучали. Так, пример на рис. 2.8 дает ошибочное представление о том, что модель многочлена 12-й степени лучше линейной. В результате мы почти никогда не обучаем модель на полном наборе данных. Как показано на рис. 2.12, мы делим данные на наборы для обучения и тестирования.
Рис. 2.12. Мы часто делим данные на несовпадающие наборы для обучения и тестирования, чтобы дать справедливую оценку нашей модели
Это позволяет дать справедливую оценку модели, непосредственно измерив ее способность к обобщению на новых данных, с которыми она еще не знакома. В реальном мире большие массивы данных встречаются редко, и можно подумать, что ошибкой было бы не использовать в обучающем процессе все данные, имеющиеся в нашем распоряжении. Порой очень хочется заново использовать обучающие данные для тестирования или срезать углы, собирая тестовый набор данных. Но будьте осторожны: если последний составлен недостаточно внимательно, мы не сможем сделать значимых выводов по поводу нашей модели.
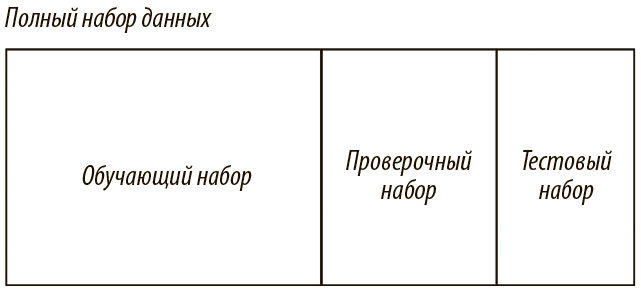
В-третьих, вероятно, наступит момент, когда модель вместо исследования полезных признаков начнет переобучаться. Чтобы этого избежать, нужно предусмотреть немедленное завершение процесса при переобучении, что позволит избежать некорректных обобщений. Для этого тренировочный процесс делится на эпохи. Эпоха – одна итерация обучения на всем наборе. Если у нас есть набор размера d и мы проводим мини-пакетный градиентный спуск с размером пакета b, эпоха будет эквивалентна d/b обновлений. В конце каждой эпохи нужно измерить, насколько успешно наша модель обобщает. Для этого мы вводим дополнительный проверочный набор, показанный на рис. 2.13. В конце эпохи он покажет нам, как модель будет работать с еще не известными ей данными. Если точность на обучающем наборе будет возрастать, а для проверочного останется прежней или ухудшится, пора прекратить процесс: началось переобучение.
Рис. 2.13. В глубоком обучении часто используется проверочный набор, препятствующий переобучению
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.