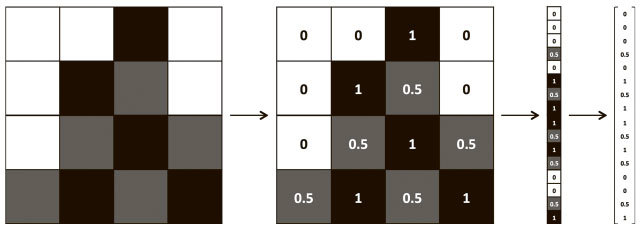
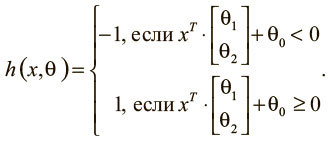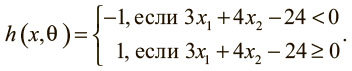Рис. 1.2. Ноль, алгоритмически трудноотличимый от шестерки
Можно задать рамки расстояния между началом и концом петли, но не очень понятно какие. И это только начало проблем. Как различить тройки и пятерки? Четверки и девятки? Можно добавлять правила, или признаки, после тщательных наблюдений и месяцев проб и ошибок, но понятно одно: процесс будет нелегок.
Многие другие классы задач попадают в ту же категорию: распознавание объектов и речи, автоматический перевод и т. д. Мы не знаем, какие программы писать для них, потому что не понимаем, как с этим справляется наш мозг. А если бы и знали, такая программа была бы невероятно сложной.
Механика машинного обучения
Для решения таких задач нужен совсем иной подход. Многое из того, что мы усваиваем в школе, похоже на стандартные компьютерные программы. Мы учимся перемножать числа, решать уравнения и получать результаты, следуя инструкциям. Но навыки, которые мы получаем в самом юном возрасте и считаем самыми естественными, усваиваются не из формул, а на примерах.
Например, в двухлетнем возрасте родители не учат нас узнавать собаку, измеряя форму ее носа или контуры тела. Мы можем отличать ее от других существ, потому что нам показали много примеров собак и несколько раз исправили наши ошибки. Уже при рождении мозг дал нам модель, описывающую наше мировосприятие. С возрастом благодаря ей мы стали на основе получаемой сенсорной информации строить предположения о том, с чем сталкиваемся. Если предположение подтверждалось родителями, это способствовало укреплению модели. Если же они говорили, что мы ошиблись, мы меняли модель, дополняя ее новой информацией. С опытом она становится все точнее, поскольку включает больше примеров. И так происходит на подсознательном уровне, мы этого даже не понимаем, но можем с выгодой использовать.
Глубокое обучение – отрасль более широкой области исследований искусственного интеллекта: машинного обучения, подразумевающего получение знаний из примеров. Мы не задаем компьютеру огромный список правил решения задачи, а предоставляем модель, с помощью которой он может сравнивать примеры, и краткий набор инструкций для ее модификации в случае ошибки. Со временем она должна улучшиться настолько, чтобы решать поставленные задачи очень точно.
Перейдем к более строгому изложению и сформулируем идею математически. Пусть наша модель – функция h(x, θ). Входное значение x – пример в векторной форме. Допустим, если x – изображение в оттенках серого, компоненты вектора – интенсивность пикселей в каждой позиции, как показано на рис. 1.3.
Рис. 1.3. Векторизация изображения для алгоритма машинного обучения
Входное значение θ – вектор параметров, используемых в нашей модели. Программа пытается усовершенствовать их значения на основе растущего числа примеров. Подробнее мы рассмотрим этот вопрос в главе 2.
Чтобы интуитивно понимать модели машинного обучения, рассмотрим пример. Допустим, мы решили узнать, как предсказывать результаты экзаменов, если известно количество часов сна и учебы в день перед испытанием. Мы собираем массив данных и при каждом замере х = [x1 x2]T записываем количество часов сна (x1), учебы (x2) и отмечаем, выше или ниже они средних по классу. Наша цель – создать модель h(х,θ) с вектором параметров θ = [θ0 θ1 θ2]T, чтобы:
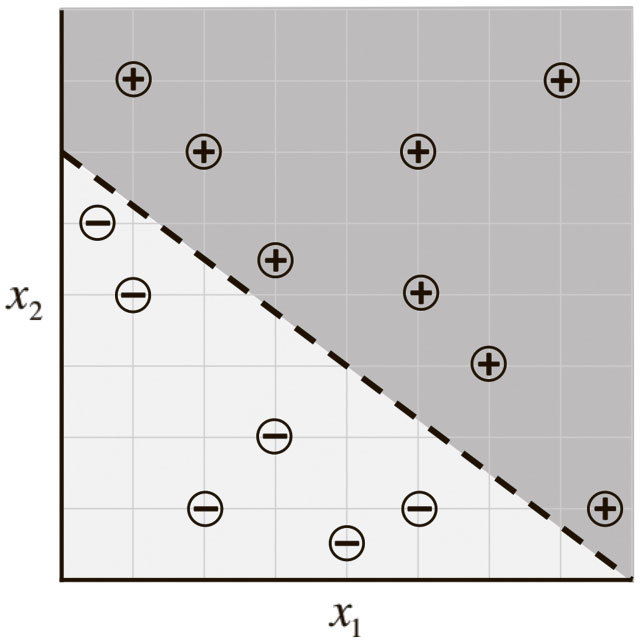
По нашему предположению, проект модели h(х,θ) будет таким, как описано выше (с геометрической точки зрения он описывает линейный классификатор, делящий плоскость координат надвое). Теперь мы хотим узнать вектор параметров θ, чтобы научить модель делать верные предсказания (−1, если результаты ниже среднего уровня, и 1 – если выше) на основании примерного входного значения x. Такая модель называется линейным персептроном и используется с 1950-х[3]. Предположим, наши данные соответствуют тому, что показано на рис. 1.4.
Рис. 1.4. Образец данных для алгоритма предсказания экзаменов и потенциального классификатора
Оказывается, при θ = [−24 3 4]T модель машинного обучения способна сделать верное предсказание для каждого замера:
Оптимальный вектор параметров θ устанавливает классификатор так, чтобы можно было сделать как можно больше корректных предсказаний. Обычно есть множество (иногда даже бесконечное) возможных оптимальных вариантов θ. К счастью, в большинстве случаев альтернативы настолько близки, что разницей между ними можно пренебречь. Если это не так, можно собрать больше данных, чтобы сузить выбор θ.
Звучит разумно, но есть много очень серьезных вопросов. Во-первых, откуда берется оптимальное значение вектора параметров θ? Решение этой задачи требует применения метода оптимизации. Оптимизаторы стремятся повысить производительность модели машинного обучения, последовательно изменяя ее параметры, пока погрешность не станет минимальной.
Мы подробнее расскажем об обучении векторов параметров в главе 2, описывая процесс градиентного спуска[4]. Позже мы постараемся найти способы еще больше увеличить эффективность этого процесса.
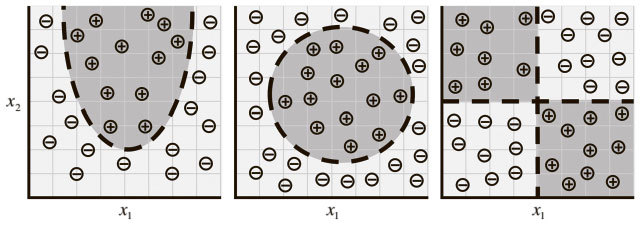
Во-вторых, очевидно, что эта модель (линейного персептрона) имеет ограниченный потенциал обучения. Например, случаи распределения данных на рис. 1.5 нельзя удобно описать с помощью линейного персептрона.
Рис. 1.5. По мере того как данные принимают более комплексные формы, нам становятся необходимы более сложные модели для их описания
Но эти ситуации – верхушка айсберга. Когда мы переходим к более комплексным проблемам – распознаванию объектов или анализу текста, – данные приобретают очень много измерений, а отношения, которые мы хотим описать, становятся крайне нелинейными. Чтобы отразить это, в последнее время специалисты по машинному обучению стали строить модели, напоминающие структуры нашего мозга. Именно в этой области, обычно называемой глубоким обучением, ученые добились впечатляющих успехов в решении проблем компьютерного зрения и обработки естественного языка. Их алгоритмы не только значительно превосходят все остальные, но даже соперничают по точности с достижениями человека, а то и превосходят их.
Нейрон
Нейрон – основная единица мозга. Небольшой его фрагмент, размером примерно с рисовое зернышко, содержит более 10 тысяч нейронов, каждый из которых в среднем формирует около 6000 связей с другими такими клетками[5]. Именно эта громоздкая биологическая сеть позволяет нам воспринимать мир вокруг. В этом разделе наша задача – воспользоваться естественной структурой для создания моделей машинного обучения, которые решают задачи аналогично. По сути, нейрон оптимизирован для получения информации от «коллег», ее уникальной обработки и пересылки результатов в другие клетки. Процесс отражен на рис. 1.6. Нейрон получает входную информацию по дендритам – структурам, напоминающим антенны. Каждая из входящих связей динамически усиливается или ослабляется на основании частоты использования (так мы учимся новому!), и сила соединений определяет вклад входящего элемента информации в то, что нейрон выдаст на выходе. Входные данные оцениваются на основе этой силы и объединяются в клеточном теле. Результат трансформируется в новый сигнал, который распространяется по клеточному аксону к другим нейронам.