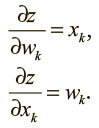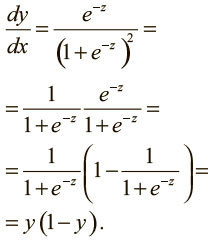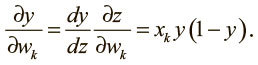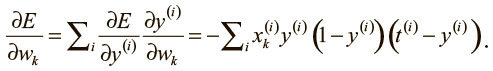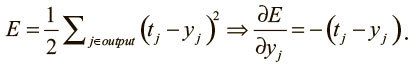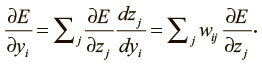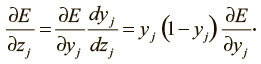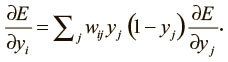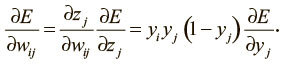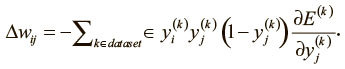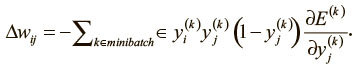Кроме того, как ни удивительно, производная выходного значения по логиту проста, если выразить ее через выходное значение:
Теперь можно использовать правило дифференцирования сложной функции, чтобы вычислить производную выходного значения по каждому из весов:
Объединяя полученные результаты, мы можем вычислить производную функции потерь по каждому весу:
Итоговое правило изменения весов будет выглядеть так:
Как вы видите, новое правило очень похоже на дельта-правило, за исключением дополнительных множителей для учета логистического компонента сигмоидного нейрона.
Алгоритм обратного распространения ошибок
Теперь мы готовы приступить к проблеме обучения многослойных нейросетей, а не только одиночных нейронов. Обратимся к подходу обратного распространения ошибок, предложенному Дэвидом Румельхартом, Джеффри Хинтоном и Рональдом Уильямсом в 1986 году[11]. В чем основная идея? Мы не знаем, что делают скрытые нейроны, но можем вычислить, насколько быстро меняется ошибка, если мы вносим корректировки в эти процессы. На основе этого мы способны определить, как быстро трансформируется ошибка, если изменить вес конкретного соединения. По сути, мы пытаемся найти наибольший уклон! Единственная сложность в том, что приходится работать в пространстве с очень большим числом измерений. Начнем с вычисления производных функции потерь по одному обучающему примеру.
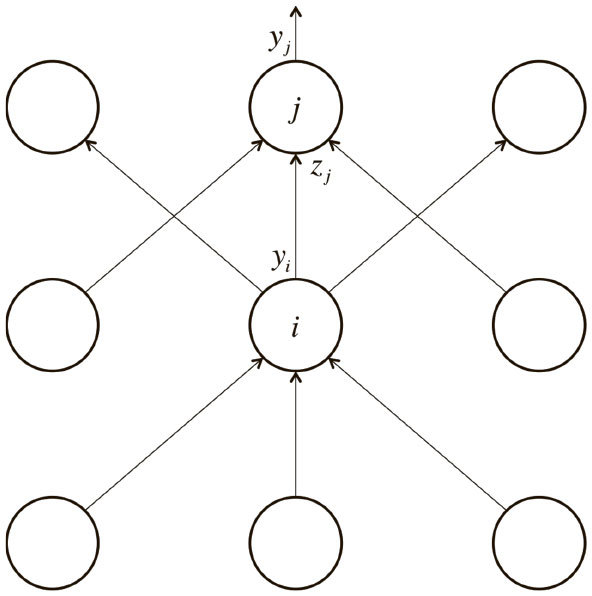
Каждый скрытый нейрон может влиять на многие выходные нейроны. Нам нужно учесть несколько эффектов ошибки, чтобы получить нужную информацию. В качестве стратегии выберем динамическое программирование. Получив производные функций потерь для одного слоя скрытых нейронов, мы применим их для вычисления производных функций потерь на выходе более низкого слоя. Когда мы найдем такие производные на выходе из скрытых нейронов, несложно будет получить производные функций потерь для весов входов в скрытый нейрон. Для упрощения введем дополнительные обозначения (рис. 2.5).
Рис. 2.5. Справочная диаграмма для вывода алгоритма обратного распространения ошибок
Нижний индекс будет обозначать слой нейронов; символ y – как обычно, выходное значение нейрона, а z – логит нейрона. Начнем с базового случая проблемы динамического программирования: вычислим производные функции потерь на выходном слое (output).
Теперь сделаем индуктивный шаг. Предположим, у нас есть производные функции потерь для слоя j. Мы собираемся вычислить производные функции потерь для более низкого слоя i. Для этого необходима информация о том, как выходные данные нейрона в слое i воздействуют на логиты всех нейронов в слое j. Вот как это сделать, используя то, что частная производная логита по входящим значениям более низкого слоя – это вес соединения wij:
Далее мы видим следующее:
Сведя эти факты воедино, мы можем выразить производные функций потерь слоя i через производные функций потерь слоя j:
Пройдя все стадии динамического программирования и заполнив таблицу всеми частными производными (функций потерь по выходным значениям скрытых нейронов), мы можем определить, как ошибка меняется по отношению к весам. Это даст нам представление о том, как корректировать веса после каждого обучающего примера:
Наконец, чтобы завершить алгоритм, как и раньше, мы суммируем частные производные по всем примерам в нашем наборе данных (dataset). Это дает нам следующую формулу изменения:
На этом описание алгоритма обратного распространения ошибок закончено!
Стохастический и мини-пакетный градиентный спуск
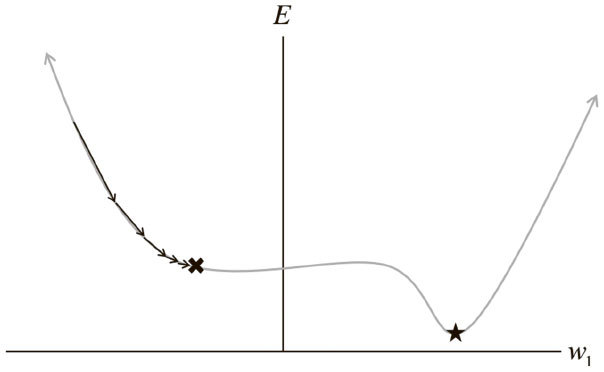
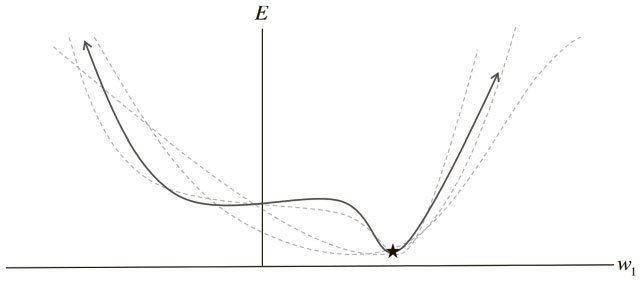
В алгоритмах, описанных в предыдущем разделе, мы использовали так называемый пакетный градиентный спуск. Идея в том, что мы при помощи всего набора данных вычисляем поверхность ошибки, а затем следуем градиенту, определяем самый крутой уклон и движемся в этом направлении. Для поверхности простой квадратичной ошибки это неплохой вариант. Но в большинстве случаев поверхность гораздо сложнее. Для примера рассмотрим рис. 2.6.
Рис. 2.6. Пакетный градиентный спуск чувствителен к седловым точкам, что может привести к преждевременному схождению
У нас только один вес, и мы используем случайную инициализацию и пакетный градиентный спуск для поиска его оптимального значения. Но поверхность ошибки имеет плоскую область (известную в пространствах с большим числом измерений как седловая точка). Если нам не повезет, то при пакетном градиентном спуске мы можем застрять в ней.
Другой возможный подход – стохастический градиентный спуск (СГС). При каждой итерации поверхность ошибки оценивается только для одного примера. Этот подход проиллюстрирован на рис. 2.7, где поверхность ошибки не единая статичная, а динамическая. Спуск по ней существенно улучшает нашу способность выходить из плоских областей.
Рис. 2.7. Стохастическая поверхность ошибки варьирует по отношению к пакетной, что позволяет решить проблему седловых точек
Основной недостаток стохастического градиентного спуска в том, что рассмотрение ошибки для одного примера может оказаться недостаточным приближением поверхности ошибки.
Это, в свою очередь, приводит к тому, что спуск займет слишком много времени. Один из способов решения проблемы – использование мини-пакетного градиентного спуска. При каждой итерации мы вычисляем поверхность ошибки по некой выборке из общего набора данных (а не одному примеру). Это и есть мини-пакет (minibatch), и его размер, как и темп обучения, – гиперпараметр. Мини-пакеты уравновешивают эффективность пакетного градиентного спуска и способность избегать локальных минимумов, которую предоставляет стохастический градиентный спуск. В контексте обратного распространения ошибок изменение весов выглядит так: