Настоящим научным прорывом шестидесятых годов XX века можно назвать работу, связанную с расшифровкой генетического кода. В итоге был создан своего рода маленький словарик, "в общих принципах похожий на азбуку Морзе" — как написал о нем Крик. Этот словарь "соотносит четырехбуквенный язык генетического материала с двадцатью буквами протеина, которые можно уподобить исполнительному языку" [1219].
Не погружаясь в самые глубины субмикроскопической алхимии, хотелось бы отметить, что комбинация любых трех "букв" ДНК побуждает клетки соединять аминокислоты таким образом, чтобы синтезировать из них определенного типа протеины. И именно это обуславливает конечный образ и набор функций каждого живого организма — строго в соответствии с унаследованным им кодом. Учитывая огромное разнообразие жизни на нашей планете, я не могу избавиться от изумления при мысли о том, что в каждом случае мы имеем дело с одним и тем же невероятно простым набором букв, перетасованным особым образом. Соответственно, лишь порядок расположения этих букв определяет разницу между геранью и жирафом, слоном и муравьем, человеком и обезьяной (точно так же, как это происходит в написанных словах). Однако все это, как отмечает Крик, сводится в итоге к чистой математике:
Поскольку язык нуклеиновых кислот содержит всего лишь четыре буквы, существует ровным счетом шестьдесят четыре триплета (4 х 4 х 4). Шестьдесят один из этих "кодонов", как их называют ученые, отвечает за образование той или иной аминокислоты. Три оставшихся кодона отвечают за "конечную цепочку" [1220].
Мы уже говорили о том, что живые клетки используют для создания протеинов лишь 20 аминокислот. И это порождает весьма существенную "двусмысленность" — когда большинство триплетов кодирует более чем одну кислоту, и при этом различные триплеты могут кодировать одну и ту же аминокислоту.
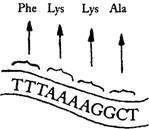
Кодоны, определяющие аминокислоты: ТТТ = фенилаланин (Phenyla Lanine); AAA = лизин (Lysine); AAG = лизин (Lysine); GCT = аланин (Alanine) (по Кэлледайну, 2004, с. 13)
Точно не известно, как именно клетки определяют правильную кислоту, когда в наличии имеется столько альтернативных возможностей. В то же время — я упоминаю об этом безо всякого подтекста — существует лишь две аминокислоты, которые ДНК считает настолько важными, что избегает в этой сфере любой двойственности. Так, за образование каждой из этих кислот отвечает по одному-единственному кодону. Первой из них является метионин. Второй — триптофан, исходная молекула для всех триптаминовых галлюциногенов [1221].
Чудо
Полагаю, читателю уже понятно из вышесказанного, что для жизни — во всяком случае, для жизни на этой планете — необходимы как нуклеиновые кислоты, так и протеины, представляющие собой необычайно сложные и объемные макромолекулы. Нуклеиновые кислоты нужны потому, что они несут генетический код и могут копировать сами себя — две вещи, на которые не способны протеины. С другой стороны, протеины необходимы для всех тех "строительных работ", которые протекают внутри клетки — в том числе для образования и дублирования самой ДНК. Без тех унаследованных инструкций, которые уже содержатся в ДНК — "возьми эту аминокислоту", "соедини ее вместе с той", "теперь остановись" и т. д., и т. д., — не будет синтезирована ни одна протеиновая цепочка и клетки не смогут выполнять свою работу. Но и ДНК, как мы уже отметили, не может быть сформирована в отсутствие протеинов. Таким образом, перед нами две стороны одной медали.
Что возмущало Крика-статистика — так это невозможность случайного возникновения даже одного-единственного протеина, сложенного из длинной цепочки аминокислот. И неважно, насколько питательным был тот самый "добиотический суп" и сколько миллиардов лет варились в нем все необходимые ингредиенты. Взяв за основу среднюю длину протеина в 200 аминокислот (некоторые протеины бывают намного больше), Крик высчитал, что шансы случайного его возникновения равны 1 к 260. То есть на одну удачную попытку — двести шестьдесят неудач. Для того чтобы в полной мере оценить эту цифру, стоит учесть, что количество всех атомов в видимой Вселенной (а не только в нашей Галактике) составляет 1 к 80 — скажем прямо, достаточно скромная пропорция, если принять во внимание шансы, противоречащие случайному образованию протеина [1222]. Насколько же менее правдоподобной будет гипотеза о том, что сама жизнь, которая даже на уровне бактерий отличается сложным клеточным механизмом и подразумевает использование множества протеинов, возникла на планете в результате случайного столкновения молекул!
Это ощущение удивительной слаженности и упорядоченности лишь усиливается при взгляде на двойную спираль ДНК. Вспомните хотя бы о том, что в каждой человеческой клетке — а каждая клетка составляет не более миллионной доли булавочной головки — находится двойная нить ДНК двух метров в длину и десяти атомов в ширину
[1223]. И фактор сжатия здесь намного больше, чем тот, который требуется для размещения двух метров в емкости уровня булавочной головки. Ведь нить ДНК располагается исключительно в ядре клетки, которое куда меньше самой клетки и составляет в диаметре лишь десять микрометров. В результате степень компактности может быть сопоставима лишь с той, которая требуется для размещения пятидесяти миль шнура в ящике для обуви. Две одинаковых полимерных ленты обычно перевиты таким образом, что напоминают двух змей — причем голова каждой из них обращена к хвосту соседки. Таким образом, каждая нить ДНК является "перевернутой" копией другой, соединяются же они у основания в строго определенном порядке (А — всегда с Т, С — всегда с G) [1224]. Ученые обычно называют их "главной копией" и "копией поддержки" — ведь если в одну из нитей вкрадется ошибка, клетка всегда сможет восстановить прежнюю схему, сопоставив "ошибочный вариант" с правильным.
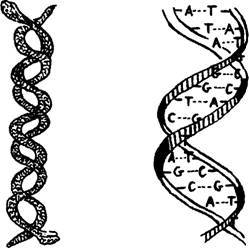
Вследствие "перевернутой" симметрии спиралей молекулу ДНК нередко сравнивают с двумя змеями, которые обвились вокруг друг друга таким образом, что голова одной из них обращена к хвосту другой, и наоборот
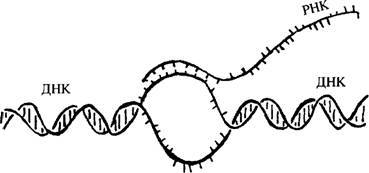
Перевод информации с ДНК на однополосный "передатчик" РНК (по Кэлледайну, 2004, с.65)
Генетическая информация, хранящаяся в каждой клетке, записана с помощью тех химических элементов, которые составляют основу любой ДНК. Именно последовательность данных элементов и отвечает за синтез протеинов. Красота и сложность этой системы заключается в том, что инструкции по синтезу передаются не непосредственно из архива ДНК, но копируются вначале (технический термин — "переводятся") на одинарную ленту молекулы РНК, которая и инициирует процесс синтеза. Все это позволяет избежать прямого обращения к базе данных ДНК, которые хранятся в полной безопасности внутри двойной спирали.
"Знаменательно уже то, — замечает Крик, — что подобный механизм вообще существует в природе. Но еще более примечательным можно счесть то обстоятельство, что в каждой живой клетке — будь то животного, растения или микроорганизма — присутствует его версия" [1225]. И эта универсальность свидетельствует о том, что код ДНК так же древен, как и двадцатибуквенный протеиновый код, с которым он находится в самой тесной связи благодаря механизму "перевода". Без сомнения, и этот код, и вся система ДНК/РНК должны были присутствовать уже в самых первых организмах, от которых берет начало все многообразие жизни на планете. Однако вся эта система, по мнению Крика, "носит слишком сложный характер, чтобы можно было представить, будто она возникла в один момент. По-видимому, она должна была развиться из чего-то более простого" [1226].