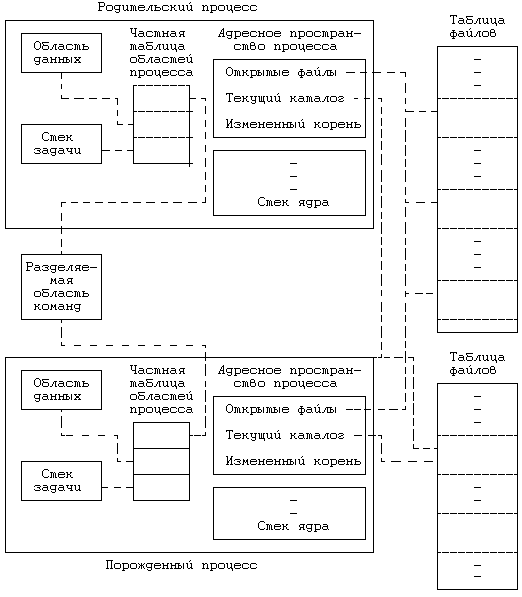
Рисунок 7.3. Создание контекста нового процесса при выполнении функции fork
Если контекст порожденного процесса готов, родительский процесс завершает свою роль в выполнении алгоритма fork, переводя порожденный процесс в состояние «готовности к запуску, находясь в памяти» и возвращая пользователю его идентификатор. Затем, используя обычный алгоритм планирования, ядро выбирает порожденный процесс для исполнения и тот «доигрывает» свою роль в алгоритме fork. Контекст порожденного процесса был задан родительским процессом; с точки зрения ядра кажется, что порожденный процесс возобновляется после приостанова в ожидании ресурса. Порожденный процесс при выполнении функции fork реализует ту часть программы, на которую указывает счетчик команд, восстанавливаемый ядром из сохраненного на уровне 2 регистрового контекста, и по выходе из функции возвращает нулевое значение.
На Рисунке 7.3 представлена логическая схема взаимодействия родительского и порожденного процессов с другими структурами данных ядра сразу после завершения системной функции fork. Итак, оба процесса совместно пользуются файлами, которые были открыты родительским процессом к моменту исполнения функции fork, при этом значение счетчика ссылок на каждый из этих файлов в таблице файлов на единицу больше, чем до вызова функции. Порожденный процесс имеет те же, что и родительский процесс, текущий и корневой каталоги, значение же счетчика ссылок на индекс каждого из этих каталогов так же становится на единицу больше, чем до вызова функции. Содержимое областей команд, данных и стека (задачи) у обоих процессов совпадает; по типу области и версии системной реализации можно установить, могут ли процессы разделять саму область команд в физических адресах.
Рассмотрим приведенную на Рисунке 7.4 программу, которая представляет собой пример разделения доступа к файлу при исполнении функции fork. Пользователю следует передавать этой программе два параметра — имя существующего файла и имя создаваемого файла. Процесс открывает существующий файл, создает новый файл и — при условии отсутствия ошибок — порождает новый процесс. Внутри программы ядро делает копию контекста родительского процесса для порожденного, при этом родительский процесс исполняется в одном адресном пространстве, а порожденный — в другом. Каждый из процессов может работать со своими собственными копиями глобальных переменных fdrd, fdwt и c, а также со своими собственными копиями стековых переменных argc и argv, но ни один из них не может обращаться к переменным другого процесса. Тем не менее, при выполнении функции fork ядро делает копию адресного пространства первого процесса для второго, и порожденный процесс, таким образом, наследует доступ к файлам родительского (то есть к файлам, им ранее открытым и созданным) с правом использования тех же самых дескрипторов.
Родительский и порожденный процессы независимо друг от друга, конечно, вызывают функцию rdwrt и в цикле считывают по одному байту информацию из исходного файла и переписывают ее в файл вывода. Функция rdwrt возвращает управление, когда при считывании обнаруживается конец файла. Ядро перед тем уже увеличило значения счетчиков ссылок на исходный и результирующий файлы в таблице файлов, и дескрипторы, используемые в обоих процессах, адресуют к одним и тем же строкам в таблице. Таким образом, дескрипторы fdrd в том и в другом процессах указывают на запись в таблице файлов, соответствующую исходному файлу, а дескрипторы, подставляемые в качестве fdwt, — на запись, соответствующую результирующему файлу (файлу вывода). Поэтому оба процесса никогда не обратятся вместе на чтение или запись к одному и тому же адресу, вычисляемому с помощью смещения внутри файла, поскольку ядро смещает внутрифайловые указатели после каждой операции чтения или записи. Несмотря на то, что, казалось бы, из-за того, что процессы распределяют между собой рабочую нагрузку, они копируют исходный файл в два раза быстрее, содержимое результирующего файла зависит от очередности, в которой ядро запускает процессы. Если ядро запускает процессы так, что они исполняют системные функции попеременно (чередуя и спаренные вызовы функций read-write), содержимое результирующего файла будет совпадать с содержимым исходного файла. Рассмотрим, однако, случай, когда процессы собираются считать из исходного файла последовательность из двух символов «ab». Предположим, что родительский процесс считал символ «a», но не успел записать его, так как ядро переключилось на контекст порожденного процесса. Если порожденный процесс считывает символ «b» и записывает его в результирующий файл до возобновления родительского процесса, строка «ab» в результирующем файле будет иметь вид «ba». Ядро не гарантирует согласование темпов выполнения процессов.
#include ‹fcntl.h›
int fdrd, fdwt
;
char c;
main(argc, argv)
int argc;
char *argv[];
{
if (argc != 3)
exit(1);
if ((fdrd = open(argv[1], O_RDONLY)) == -1)
exit(1);
if ((fdwt = creat(argv[2], 0666)) == -1)
exit(1);
fork(); /* оба процесса исполняют одну и ту же программу */
rdwrt();
exit(0);
}
rdwrt()
{
for(;;)
{
if (read(fdrd, &c,1) != 1)
return;
write(fdwt, &c,1);
}
}
Рисунок 7.4. Программа, в которой родительский и порожденный процессы разделяют доступ к файлу
Теперь перейдем к программе, представленной на Рисунке 7.5, в которой процесс-потомок наследует от своего родителя файловые дескрипторы 0 и 1 (соответствующие стандартному вводу и стандартному выводу). При каждом выполнении системной функции pipe производится назначение двух файловых дескрипторов в массивах to_par и to_chil. Процесс вызывает функцию fork и делает копию своего контекста: каждый из процессов имеет доступ только к своим собственным данным, так же как и в предыдущем примере. Родительский процесс закрывает файл стандартного вывода (дескриптор 1) и дублирует дескриптор записи, возвращаемый в канал to_chil. Поскольку первое свободное место в таблице дескрипторов родительского процесса образовалось в результате только что выполненной операции закрытия (close) файла вывода, ядро переписывает туда дескриптор записи в канал и этот дескриптор становится дескриптором файла стандартного вывода для to_chil. Те же самые действия родительский процесс выполняет в отношении дескриптора файла стандартного ввода, заменяя его дескриптором чтения из канала to_par. И порожденный процесс закрывает файл стандартного ввода (дескриптор 0) и так же дублирует дескриптор чтения из канала to_chil. Поскольку первое свободное место в таблице дескрипторов файлов прежде было занято файлом стандартного ввода, его дескриптором становится дескриптор чтения из канала to_chil. Аналогичные действия выполняются и в отношении дескриптора файла стандартного вывода, заменяя его дескриптором записи в канал to_par. И тот, и другой процессы закрывают файлы, дескрипторы которых возвратила функция pipe — хорошая традиция, в чем нам еще предстоит убедиться. В результате, когда родительский процесс переписывает данные в стандартный вывод, запись ведется в канал to_chil и данные поступают к порожденному процессу, который считывает их через свой стандартный ввод. Когда же порожденный процесс пишет данные в стандартный вывод, запись ведется в канал to_par и данные поступают к родительскому процессу, считывающему их через свой стандартный ввод. Так через два канала оба процесса обмениваются сообщениями.