алгоритм alloc /* выделение блока файловой системы */
входная информация: номер файловой системы
выходная информация: буфер для нового блока
{
do (пока суперблок заблокирован)
sleep (до того момента, когда с суперблока будет снята блокировка);
удалить блок из списка свободных блоков в суперблоке;
if (из списка удален последний блок)
{
заблокировать суперблок;
прочитать блок, только что взятый из списка свободных (алгоритм bread);
скопировать номера блоков, хранящиеся в данном блоке, в суперблок;
освободить блочный буфер (алгоритм brelse);
снять блокировку с суперблока;
возобновить выполнение процессов (после снятия блокировки с суперблока);
}
получить буфер для блока, удаленного из списка (алгоритм getblk);
обнулить содержимое буфера;
уменьшить общее число свободных блоков;
пометить суперблок как «измененный»;
return буфер;
}
Рисунок 4.19. Алгоритм выделения дискового блока
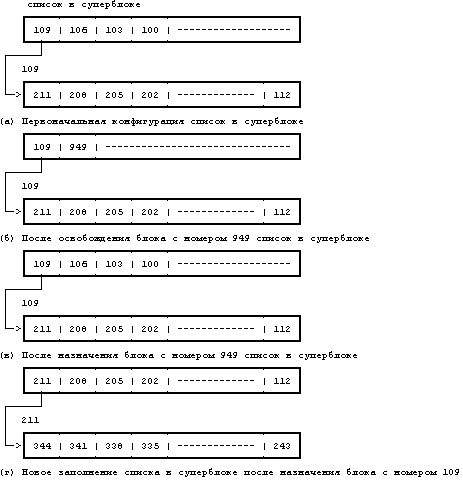
Алгоритмы назначения и освобождения индексов и дисковых блоков сходятся в том, что ядро использует суперблок в качестве кеша, хранящего указатели на свободные ресурсы — номера блоков и номера индексов. Оно поддерживает список номеров блоков с указателями, такой, что каждый номер свободного блока в файловой системе появляется в некотором элементе списка, но ядро не поддерживает такого списка для свободных индексов. Тому есть три причины.
Ядро устанавливает, свободен ли индекс или нет, проверяя: если поле типа файла очищено, индекс свободен. Ядро не нуждается в другом механизме описания свободных индексов. Тем не менее, оно не может определить, свободен ли блок или нет, только взглянув на него. Ядро не может уловить различия между маской, показывающей, что блок свободен, и информацией, случайно имеющей сходную маску. Следовательно, ядро нуждается во внешнем механизме идентификации свободных блоков, в качестве него в традиционных реализациях системы используется список с указателями.
Сама конструкция дисковых блоков наводит на мысль об использовании списков с указателями: в дисковом блоке легко разместить большие списки номеров свободных блоков. Но индексы не имеют подходящего места для массового хранения списков номеров свободных индексов.
Пользователи имеют склонность чаще расходовать дисковые блоки, нежели индексы, поэтому кажущееся запаздывание в работе при просмотре диска в поисках свободных индексов не является таким критическим, как если бы оно имело место при поисках свободных дисковых блоков.
Рисунок 4.20. Запрашивание и освобождение дисковых блоков
4.8 ДРУГИЕ ТИПЫ ФАЙЛОВ
В системе UNIX поддерживаются и два других типа файлов: каналы и специальные файлы. Канал, иногда называемый fifo (сокращенно от «first-in-first-out» — «первым пришел — первым вышел» — поскольку обслуживает запросы в порядке поступления), отличается от обычного файла тем, что содержит временные данные: информация, однажды считанная из канала, не может быть прочитана вновь. Кроме того, информация читается в том порядке, в котором она была записана в канале, и система не допускает никаких отклонений от данного порядка. Способ хранения ядром информации в канале не отличается от способа ее хранения в обычном файле, за исключением того, что здесь используются только блоки прямой, а не косвенной, адресации. Конкретное представление о каналах можно будет получить в следующей главе.
Последним типом файлов в системе UNIX являются специальные файлы, к которым относятся специальные файлы устройств ввода-вывода блоками и специальные файлы устройств посимвольного ввода-вывода. Оба подтипа обозначают устройства, и поэтому индексы таких файлов не связаны ни с какой информацией. Вместо этого индекс содержит два номера — старший и младший номера устройства. Старший номер устройства указывает его тип, например, терминал или диск, а младший номер устройства — числовой код, идентифицирующий устройство в группе однородных устройств. Более подробно специальные файлы устройств рассматриваются в главе 10.
4.9 ВЫВОДЫ
Индекс представляет собой структуру данных, в которой описываются атрибуты файла, в том числе расположение информации файла на диске. Существует две разновидности индекса: копия на диске, в которой хранится информация индекса, пока файл находится в работе, и копия в памяти, где хранится информация об активных файлах. Алгоритмы ialloc и ifree управляют назначением файлу дискового индекса во время выполнения системных операций creat, mknod, pipe и unlink (см. следующую главу), а алгоритмы iget и iput управляют выделением индексов в памяти в момент обращения процесса к файлу. Алгоритм bmap определяет местонахождение дисковых блоков, принадлежащих файлу, используя предварительно заданное смещение в байтах от начала файла. Каталоги представляют собой файлы, которые устанавливают соответствие между компонентами имен файлов и номерами индексов. Алгоритм namei преобразует имена файлов, с которыми работают процессы, в идентификаторы индексов, с которыми работает ядро. Наконец, ядро управляет назначением файлу новых дисковых блоков, используя алгоритмы alloc и free.
Структуры данных, рассмотренные в настоящей главе, состоят из связанных списков, хеш-очередей и линейных массивов, и поэтому алгоритмы, работающие с рассмотренными структурами данных, достаточно просты. Сложности появляются тогда, когда возникает конкуренция, вызываемая взаимодействием алгоритмов между собой, и некоторые из этих проблем синхронизации рассмотрены в тексте. Тем не менее, алгоритмы не настолько детально разработаны и могут служить иллюстрацией простоты конструкции системы.
Вышеописанные структуры и алгоритмы работают внутри ядра и невидимы для пользователя. С точки зрения общей архитектуры системы (Рисунок 2.1), алгоритмы, рассмотренные в данной главе, имеют отношение к нижней половине подсистемы управления файлами. Следующая глава посвящена разбору обращений к операционной системе, обеспечивающих функционирование пользовательского интерфейса, и описанию верхней половины подсистемы управления файлами, из которой вызывается выполнение рассмотренных здесь алгоритмов.
4.10 УПРАЖНЕНИЯ
1. В версии V системы UNIX разрешается использовать не более 14 символов на каждую компоненту имени пути поиска. Алгоритм namei отсекает лишние символы в компоненте. Что нужно сделать в файловой системе и в соответствующих алгоритмах, чтобы стали допустимыми имена компонент произвольной длины?
2. Предположим, что пользователь имеет закрытую версию системы UNIX, причем он внес в нее такие изменения, что имя компоненты теперь может состоять из 30 символов; закрытая версия системы обеспечивает тот же способ хранения записей каталогов, как и стандартная операционная система, за исключением того, что записи каталогов имеют длину 32 байта вместо 16. Если пользователь смонтирует закрытую файловую систему в стандартной операционной среде, что произойдет во время работы алгоритма namei, когда процесс обратится к файлу?