Файловая система состоит из последовательности логических блоков длиной 512, 1024, 2048 или другого числа байт, кратного 512, в зависимости от реализации системы. Размер логического блока внутри одной файловой системы постоянен, но может варьироваться в разных файловых системах в данной конфигурации. Использование логических блоков большого размера увеличивает скорость передачи данных между диском и памятью, поскольку ядро сможет передать больше информации за одну дисковую операцию, и сокращает количество продолжительных операций. Например, чтение 1 Кбайта с диска за одну операцию осуществляется быстрее, чем чтение 512 байт за две. Однако, если размер логического блока слишком велик, полезный объем памяти может уменьшиться, это будет показано в главе 5. Для простоты термин «блок» в этой книге будет использоваться для обозначения логического блока, при этом подразумевается логический блок размером 1 Кбайт, кроме специально оговоренных случаев.
Рисунок 2.3. Формат файловой системы
Файловая система имеет следующую структуру (Рисунок 2.3).
• Блок загрузки располагается в начале пространства, отведенного под файловую систему, обычно в первом секторе, и содержит программу начальной загрузки, которая считывается в машину при загрузке или инициализации операционной системы. Хотя для запуска системы требуется только один блок загрузки, каждая файловая система имеет свой (пусть даже пустой) блок загрузки.
• Суперблок описывает состояние файловой системы — какого она размера, сколько файлов может в ней храниться, где располагается свободное пространство, доступное для файловой системы, и другая информация.
• Список индексов в файловой системе располагается вслед за суперблоком. Администраторы указывают размер списка индексов при генерации файловой системы. Ядро операционной системы обращается к индексам, используя указатели в списке индексов. Один из индексов является корневым индексом файловой системы: это индекс, по которому осуществляется доступ к структуре каталогов файловой системы после выполнения системной операции mount (монтировать) (раздел 5.14).
• Информационные блоки располагаются сразу после списка индексов и содержат данные файлов и управляющие данные. Отдельно взятый информационный блок может принадлежать одному и только одному файлу в файловой системе.
2.2.2 Процессы
В этом разделе мы рассмотрим более подробно подсистему управления процессами. Даются разъяснения по поводу структуры процесса и некоторых информационных структур, используемых при распределении памяти под процессы. Затем дается предварительный обзор диаграммы состояния процессов и затрагиваются различные вопросы, связанные с переходами из одного состояния в другое.
Процессом называется последовательность операций при выполнении программы, которые представляют собой наборы байтов, интерпретируемые центральным процессором как машинные инструкции (т. н. «текст»), данные и стековые структуры. Создается впечатление, что одновременно выполняется множество процессов, поскольку их выполнение планируется ядром, и, кроме того, несколько процессов могут быть экземплярами одной программы. Выполнение процесса заключается в точном следовании набору инструкций, который является замкнутым и не передает управление набору инструкций другого процесса; он считывает и записывает информацию в раздел данных и в стек, но ему недоступны данные и стеки других процессов. Одни процессы взаимодействуют с другими процессами и с остальным миром посредством обращений к операционной системе.
С практической точки зрения процесс в системе UNIX является объектом, создаваемым в результате выполнения системной операции fork. Каждый процесс, за исключением нулевого, порождается в результате запуска другим процессом операции fork. Процесс, запустивший операцию fork, называется родительским, а вновь созданный процесс — порожденным. Каждый процесс имеет одного родителя, но может породить много процессов. Ядро системы идентифицирует каждый процесс по его номеру, который называется идентификатором процесса (PID). Нулевой процесс является особенным процессом, который создается «вручную» в результате загрузки системы; после порождения нового процесса (процесс 1) нулевой процесс становится процессом подкачки. Процесс 1, известный под именем init, является предком любого другого процесса в системе и связан с каждым процессом особым образом, описываемым в главе 7.
Пользователь, транслируя исходный текст программы, создает исполняемый файл, который состоит из нескольких частей:
• набора «заголовков», описывающих атрибуты файла,
• текста программы,
• представления на машинном языке данных, имеющих начальные значения при запуске программы на выполнение, и указания на то, сколько пространства памяти ядро системы выделит под неинициализированные данные, так называемые bss[6] (ядро устанавливает их в 0 в момент запуска),
• других секций, таких как информация символических таблиц.
Для программы, приведенной на Рисунке 1.3, текст исполняемого файла представляет собой сгенерированный код для функций main и copy, к определенным данным относится переменная version (вставленная в программу для того, чтобы в последней имелись некоторые определенные данные), а к неопределенным — массив buffer. Компилятор с языка Си для системы версии V создает отдельно текстовую секцию по умолчанию, но не исключается возможность включения инструкций программы и в секцию данных, как в предыдущих версиях системы.
Ядро загружает исполняемый файл в память при выполнении системной операции exec, при этом загруженный процесс состоит по меньшей мере из трех частей, так называемых областей: текста, данных и стека. Области текста и данных корреспондируют с секциями текста и bss-данных исполняемого файла, а область стека создается автоматически и ее размер динамически устанавливается ядром системы во время выполнения. Стек состоит из логических записей активации, помещаемых в стек при вызове функции и выталкиваемых из стека при возврате управления в вызвавшую процедуру; специальный регистр, именуемый указателем вершины стека, показывает текущую глубину стека. Запись активации включает параметры передаваемые функции, ее локальные переменные, а также данные, необходимые для восстановления предыдущей записи активации, в том числе значения счетчика команд и указателя вершины стека в момент вызова функции. Текст программы включает последовательности команд, управляющие увеличением стека, а ядро системы выделяет, если нужно, место под стек. В программе на Рисунке 1.3 параметры argc и argv, а также переменные fdold и fdnew, содержащиеся в вызове функции main, помещаются в стек, как только встретилось обращение к функции main (один раз в каждой программе, по условию), так же и параметры old и new и переменная count, содержащиеся в вызове функции copy, помещаются в стек в момент обращения к указанной функции.
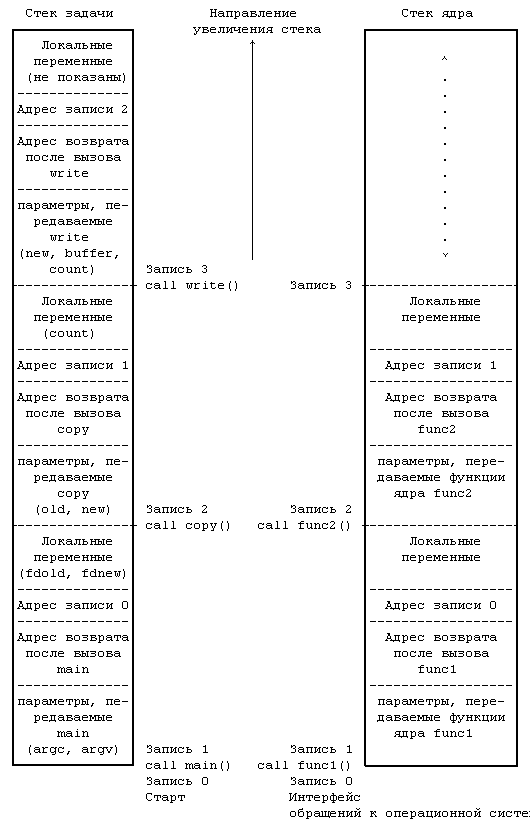
Рисунок 2.4. Стеки задачи и ядра для программы копирования.
Поскольку процесс в системе UNIX может выполняться в двух режимах, режиме ядра или режиме задачи, он пользуется в каждом из этих режимов отдельным стеком. Стек задачи содержит аргументы, локальные переменные и другую информацию относительно функций, выполняемых в режиме задачи. Слева на Рисунке 2.4 показан стек задачи для процесса, связанного с выполнением системной операции write в программе copy. Процедура запуска процесса (включенная в библиотеку) обратилась к функции main с передачей ей двух параметров, поместив в стек задачи запись 1; в записи 1 есть место для двух локальных переменных функции main. Функция main затем вызывает функцию copy с передачей ей двух параметров, old и new, и помещает в стек задачи запись 2; в записи 2 есть место для локальной переменной count. Наконец, процесс активизирует системную операцию write, вызвав библиотечную функцию с тем же именем. Каждой системной операции соответствует точка входа в библиотеке системных операций; библиотека системных операций написана на языке ассемблера и включает специальные команды прерывания, которые, выполняясь, порождают «прерывание», вызывающее переключение аппаратуры в режим ядра. Процесс ищет в библиотеке точку входа, соответствующую отдельной системной операции, подобно тому, как он вызывает любую из функций, создавая при этом для библиотечной функции запись активации. Когда процесс выполняет специальную инструкцию, он переключается в режим ядра, выполняет операции ядра и использует стек ядра.
