Обычно ETL-процессы автоматизируются специальными программами, которые пишут инженеры по данным. К примеру, каждый квартал компания скачивает публичный бухгалтерский отчет конкурентов в PDF-формате. Делается это для того, чтобы держать руку на пульсе, следить за рынком. Очевидно, что в такой ситуации невозможно попросить конкурента выкладывать информацию в более удобном формате. Поэтому инженер по данным пишет программу, которая сначала скачивает PDF-файл в «озеро данных», потом достает пару-тройку нужных значений из него и сохраняет в «хранилище». После чего обновляет графики, которые строятся по этим данным. И в конце удаляет исходный PDF-файл из озера. Подобная программа срабатывает по расписанию, автоматически, непрерывно доставляя свежую информацию руководству и аналитикам. А в хранилище не остается больших ненужных файлов, все преобразуется в максимально компактный и удобный вид.
Машинное обучение
Итак, мы определились как со способом хранения данных, так и с причиной их преобразования в более удобный и компактный формат. Но остались вопросы: какова цель хранения данных, почему их не стоит удалять по прошествии длительного времени, зачем их бесконечно копить? Кратко на эти вопросы можно ответить так: собранные «большие данные» нужны для обучения машин. После прохождения такого обучения компьютеры способны прогнозировать параметры спроса, предлагать меры по улучшению продуктов и услуг, а также выдвигать идеи для построения новых стратегий по продажам. Наличие подобных обученных машин ведет к увеличению прибыли, снижению издержек производства, улучшению бизнес-процессов, и, как следствие всего этого, компания начинает теснить своих конкурентов.
Попробуем понять принцип машинного обучения с помощью небольшого примера. Предположим, в компьютер загрузили фотографии собаки. Затем машине сказали: «Это фотографии собаки». Компьютер запомнит такой образ собаки и само слово. Для контроля этих знаний надо провести экзамен – загрузить в машину фото другой собаки. И компьютер, используя созданную во время обучения логическую модель, скажет: «С вероятностью 95 % это похоже на собаку». Если тренирующий машину специалист будет удовлетворен таким уровнем точности ответа, он завершит обучение и сохранит текущее состояние машины в файл, чтобы воспользоваться им при необходимости в будущем. В этом файле натренированной модели машинного обучения находится логика определения собак по изображению на фотографии. При этом данную модель можно улучшить в будущем, переобучить: сделать ее более точной, используя больше изображений.
Готовая модель с созданной в процессе обучения логикой сохраняется в файл, в память компьютера. Это делается специально, чтобы в следующий раз, когда понадобится прогноз, не приходилось проводить обучение с самого нуля. Обратите внимание, что тренировка машины похожа на процесс обучения человека: чтобы получить качественное образование, необходимо выполнить как можно больше контрольных, пройти много тестов и сдать кучу экзаменов. В случае с изображениями собаки, для достижения более-менее уверенного распознавания потребуется показать машине тысячи фотографий с этими и другими животными. Такой процесс обучения может растянуться на несколько дней даже на мощных компьютерах. А вот само предсказание с помощью готовой модели занимает считанные доли секунды. И может осуществляться на ограниченных вычислительных ресурсах, даже на мобильных телефонах. При этом файл модели редко превышает размер в пару сотен мегабайт.
Часто можно услышать еще такие термины как «нейронное программирование» и «глубокое обучение» (с английского ”Deep Learning”). По сути, это способы построения логики, которые находятся под «капотом» у модели машинного обучения. Конечному пользователю готовой модели абсолютно все равно, как проводилось обучение: будь то «нейронное программирование», «дерево решений» или что-то связанное с «глубоким обучением». Главное, чтобы это была действительно обученная (натренированная) модель с хорошей предсказательной силой (высокой вероятностью верного ответа). А выбор методов по ее построению и тренировке – это задача специалистов. Ведь с точки зрения тех, кто использует готовые модели, все работает одинаково. Это как с автомобилями – они такие разные, но у всех у них есть педаль газа и тормоза. Поэтому, если услышите термины «нейронное программирование» и «глубокое обучение», знайте, что это все то же «машинное обучение».
Кто использует машинное обучение в бизнесе
Чтобы оценить необходимость использования машинного обучения в бизнесе, достаточно взглянуть на лидеров рынка, которые в подавляющем большинстве уже активно его применяют[2] и, по данным консалтинговой компании McKinsey & Company, делают это практически во всех возможных областях (от ретейла и туризма до фармакологии и электрогенерации) и почти в 4 раза чаще, чем остальные фирмы. Судя по такой существенной разнице, машинное обучение является одним из основных инструментов, которыми должна уметь пользоваться организация, если она стремится выбиться в лидеры.
По данным аналитиков, после внедрения машинного обучения у компаний в среднем себестоимость производства снижается на 10–20 %, а выручка растет на 5–10 % в зависимости от сферы деятельности. Это невероятная выгода. Поэтому почти 70 % лидеров рынка говорят о том, что машинное обучение является частью их стратегии и у них составлены многолетние корпоративные планы по его дальнейшему развитию.
Бытует мнение, что при внедрении машинного обучения придется нанимать много сотрудников для поддержания работы созданных систем. Но по статистике лишь 30 % компаний придется увеличить штат на 3 %. И только у 5 % – он вырастет на 10 %. При этом в фирмах, связанных с тяжелой промышленностью, общее количество сотрудников, наоборот, уменьшится на 3–10 %.
Цель цифровизации и сбора больших данных
Распознавание собак на фотографиях – это отличная функция. Но вряд ли с ее помощью можно создать несколько успешных бизнес-продуктов, которые принесут реальную прибыль. Поэтому давайте оставим этот пример и зададимся более глобальным вопросом: «Как за счет больших данных и машинного обучения увеличить прибыль компании или по крайней мере вывести ее на самоокупаемость?» В этом вопросе речь идет о двух совершенно разных состояниях бизнеса. Но они оба могут быть скорректированы, с одной стороны, благодаря аналитике и ее инструментам, с другой – за счет возможности предсказания будущего на основе больших данных. Разберем все по порядку.
Как заработать больше
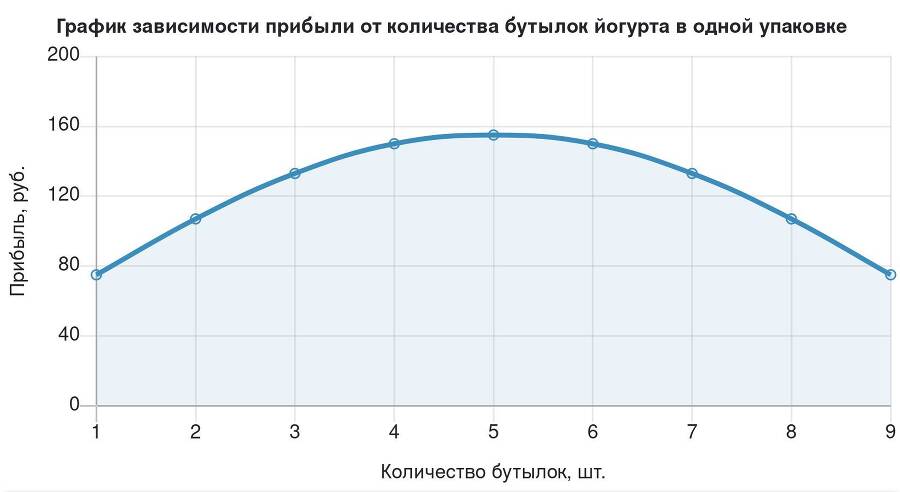
Рассмотрим аналитический процесс (анализ больших бизнес-данных) с точки зрения обычного человека. В качестве примера возьмем продажи питьевых йогуртов. Для проведения анализа люди используют графики. Например, график зависимости средней прибыли компании от количества бутылок йогурта в одной проданной упаковке:
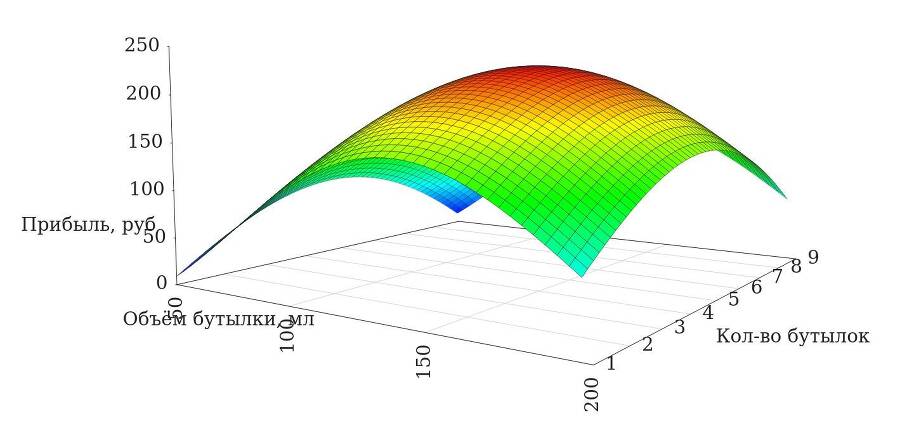
На таком графике любой человек с легкостью может найти самый высокий показатель и сделать вывод: «Если класть в упаковку по 5 йогуртов, чистая прибыль будет максимальной и составит 160 рублей за одну такую проданную упаковку». И это верное заключение, с одной лишь оговоркой. Двухмерный график строится тогда, когда все остальные параметры зафиксированы. Например, этот график справедлив при значении объема бутылки в 100 мл. Но как он поведет себя, если построить его исходя из разных объемов емкости? Давайте попробуем изобразить трехмерный вариант такого графика.
С изменением объема одной бутылки изменяется и чистая прибыль. Поэтому для получения максимальной выгоды надо найти на трехмерном графике наивысшую точку и определить уже два параметра: количество бутылок в упаковке и объем одной бутылки.