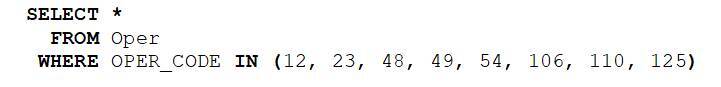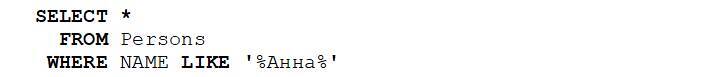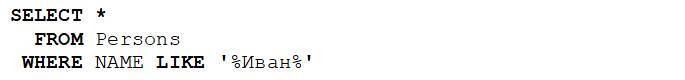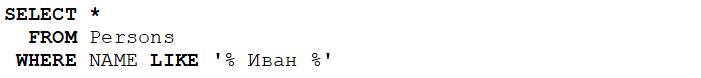6. Операторы сравнения IN, LIKE и BETWEEN
Помимо основных операторов сравнения (больше, меньше, равно, меньше или равно, больше или равно) в языке SQL есть операторы, упрощающие выборку данных по диапазону или множеству. Например, если нужно из таблицы банковских операций отобрать те, у которых код операции 12, 23, 48, 49, 54 или один из еще некоторого множества чисел, то, чтобы не перебирать все эти значения при сравнении со столбцом через оператор OR, можно делать запросы вида:
Отберутся операции, у которых в столбце «OPER_CODE» значение входит в перечисленное множество, иначе говоря, одно из них. Символ звездочки после слова SELECT указывает на то, что будут выбраны все столбцы таблицы «Oper».
Отберем сотрудников, работающих в первом филиале в первом, втором или третьем департаменте.
Надеюсь, что применение оператора IN достаточно хорошо стало понятно. Теперь рассмотрим следующий оператор. В начале выберем сотрудника, зная его точное ФИО:
Получаем результат:
Выбралась конкретная строчка из таблицы, у которой в столбце NAME строгое соответствие запрашиваемому текстовому значению.
Для того, чтобы искать не по точному соответствию, а по фрагменту или маске, можно использовать оператор LIKE (like – это не только с англ. «нравиться», но и «как», в смысле «похож»).
В результате из таблицы сотрудников будут отобраны Анны, а точнее те строчки, у которых в столбце NAME есть фрагмент «Анна». Значки процентов в начале и конце слова означают, что в этом месте может быть еще текст. То есть слово «Анна» должно быть в NAME, но оно может сопровождаться в начале и в конце еще текстом. И такие совпадения будут отобраны. Если в начале или в конце текста не будет, а также, если NAME состоит целиком только из «Анна», то такие строчки тоже будут отобраны. Результат:
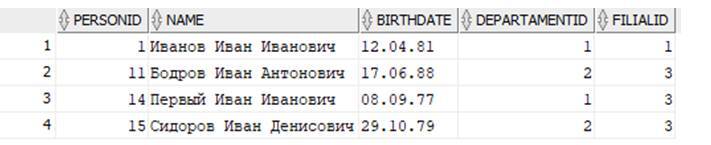
Попробуем отобрать всех сотрудников с именем «Иван»:
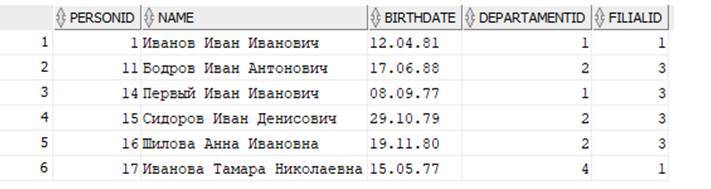
Сколько много данных вернулось! Похоже, здесь есть что–то лишнее:
Мы видим, что помимо сотрудников с именем «Иван» отобрались еще и те, у кого в столбце NAME есть этот фрагмент не в составе имени, а является частью фамилии или отчества. Что же делать? Мы можем в качестве фрагмента поиска указать « Иван » с пробелами в начале и конце! Таким образом это будет означать, что слева и справа есть еще слова, отделенные от «Иван» пробелами – это фамилия и отчество.
Теперь всех отобранных сотрудников точно зовут «Иван»:
Если бы нам нужно было найти всех сотрудников, чья фамилия начинается со слова «Иван», то оператору LIKE необходимо было быть дать значение:
Найдутся сотрудники, у которых в графе NAME значение начинается с «Иван»:
Помимо знака «%» при поиске с LIKE можно использовать символ нижнего подчеркивания – «_». Он означает обязательно один любой символ (буква, цифра, символ). Например, при поиске автомобиля по регистрационному номеру, мы хотим найти тот у которого в номере буква «в», «а» и «а», но между первой и второй буквой идут три цифры, тогда мы можем использовать «маску» поиска, указав после первой «в» три нижних подчеркивания:
Так как в таблице «PersonCars» («Автомобили сотрудников») в столбце CARREGNUMBER регистрационный номер указан с кодом региона и страны, то после букв «а» мы указали «%». Отобранные автомобили имеют номера, начинающиеся на букву «в» и соответствующие маске поиска:
По–умолчанию, поиск с LIKE, а также по точному совпадению, регистрозависимый, то есть, если в таблице PersonCars был бы автомобиль, с большими буквами в регистрационном номере, то мы бы его не отобрали. Упустили. Существуют настройки СУБД, позволяющие делать поиск регистронезависимым, но это, почти всегда, не практикуется. Чуть позже мы сами немного доработаем наш запрос, и он будет работать на любых базах регистронезависимо. Мы будем находить строчки из таблицы, соответствующие маске, и будет не важно, какими буквами написан текст в сравниваемом столбце – мы научимся всегда отбирать нужные данные!
Теперь посмотрим, как можно отбирать данные, где значение в столбце входит в некоторый диапазон. Например, может потребоваться отобрать платежи, совершенные за некоторый временной промежуток. Или мы можем отобрать сотрудников, чьи даты рождения попадают в определенный диапазон. По–простому, мы можем написать так:
Отберутся все строчки из Persons, для которых в столбце BIRTHDATE значение больше или равно начальной дате и одновременно меньше или равно конечной дате. Каждая отбираемая строчка будет проверена одновременно на два условия. Чтобы упростить выбор данных за диапазон, мы можем использовать оператор BETWEEN:
Выглядит проще, не так ли? Теперь имя столбца в условие пишется только один раз. Отберутся строки, для которых дата рождения между «01.01.1980» и «31.12.1989».
Чтобы воспользоваться оператором BETWEEN, его нужно написать сразу после названия столбца, значение которого необходимо принимать для сравнения, затем первую границу диапазона, потом AND и последнюю границу диапазона:
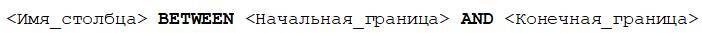
Отлично! Теперь мы можем выбирать данные с условием за диапазон. Первое, что нужно поправить, это правильную подачу дат в SQL–запрос. Почему данная вставка дат не корректная и к чему это может привести? Если мы попробуем выполнить на нашей базе данных один из запросов в котором есть даты в условии, приведенных выше, то мы даже можем получить ошибку от Oracle. И это будет правильно! Сейчас в запрос в кавычках мы пишем дату, но то, что пишется в кавычках для СУБД – это текст. Согласно полученному от нас SQL–запросу, Oracle «понимает», что необходимо отбирать данные, опираясь на столбец, в котором лежат даты и что нас интересуют такие строчки из таблицы, где дата в определенном диапазоне (дат). Чтобы понять, входит ли дата в строке в определенный диапазон (дат), необходимо сначала текст, содержащий начальную и конечную дату диапазона, преобразовать в даты. И Oracle до выполнения запроса, выполняет неявное преобразование текста в даты. Такое преобразование текста в дату называется неявным, так как оно осуществляется без нашего явного на то указания. Но Ораклу нужно выполнить запрос чтобы сравнить даты рождения сотрудников и понять, попадают ли они в диапазон, вот он и выполняет такое преобразование!