То есть после того, как будут получены суммы по клиентам, в результирующем наборе останутся только те клиенты, у которых эти суммы более интересующего нас значения.
Конечно, мы можем отбирать строчки из таблицы заказов тех, где «Сумма сделки» больше, например, определенной. Но у нас задача была другая. Нам необходимо было получить клиентов, сумма заказов за год которых превысила 500.000 р. Поэтому мы применили сначала WHERE, для первичного отбора строчек данных из таблицы «Заказов» тех, которые относятся к прошедшему году, и затем воспользовались группировкой GROUP BY по клиентам с подсчетом «Сумм сделок» по каждому их них с опцией HAVING, чтобы на основе сгруппированной (агрегированной, то есть обобщенной) информации сделать еще одну фильтрацию данных.
HAVING следует писать после GROUP BY:
И это уже полная структура одного предложения SELECT. Полный список ключевых слов, которые можно применять при выборке данных. Из всех перечисленных ключевых слов обязательными являются только SELECT и FROM. Запросы могут быть даже без WHERE и без сортировки – ORBER BY. Главное, что всегда нужно указывать, – это какие столбцы отбирать и откуда.
Конечно, мы будем применять еще и кейсы, и подзапросы, но это все будет строиться на основе структуры, которая приведена выше. Поэтому, ее нужно запомнить.
Для Гуру: в СУБД MS SQL Server и MySQL даже FROM не обязателен при выводе данных, но это исключение и применяется при решении специфических задач. Объясню тебе про это на уроке про псевдотаблиц.
4. Написание простых запросов получения данных
4.1. Выборка некоторых или всех столбцов из таблицы
Дорогой читатель, в начале следующей главы мы разберем как установить ORACLE и создать базу данных на своем компьютере. А также, мы познакомимся с программой SQL Developer, одним из самых распространенных средств работы с базами данных ORACLE. Пройдя по ссылке, ты скачаешь скрипт и загрузишь его в свою новую пока пустую базу данных. После прогрузки скрипта, у тебя появятся таблицы с тестовыми (учебными) данными. И все это за несколько простых шагов!
Теперь у тебя будет фактически подготовленное рабочее (учебное) место!
В конце каждой главы для тебя подготовлены практические задачи! Их нужно постараться сделать максимально самостоятельно. К некоторым задачам будут даваться рекомендации к выполнению, к некоторым – нет. Это значит, что их можно будет решить любым способом. Некоторые задачи можно будет решить только комбинацией методов. Большинство задач – это стандартные задачи, которые решат специалисты по SQL, а некоторые – нестандартные. С помощью них, ты научишься нестандартно и более глубоко понимать SQL. Если ты в течение часа не смог решить некоторую задачу, ее можно отложить и попробовать вернуться к ней, например, попозже или завтра! Многие мои ученики иногда так справлялись с достаточно трудными запросами, и, на второй день, почти всегда говорили, что смогли взглянуть на задачу под другим углом.
После списка задач к каждой главе ты найдешь решения к задачам. Мы подробно вместе прорешаем каждую задачу. Но не нужно этим пользоваться сразу, если у тебя не получается решить задачу. Желательно, ответами пользоваться минимум завтра. Ты получишь больше пользы, если сможете решить задачу сам, пусть и дольше.
В предыдущей главе мы рассмотрели общую структуру любого предложения SELECT. Работая постоянно с запросами, через довольно короткое время, мы запомним назначение и расположение каждого блока и еще чуть позже, будем правильно и максимально эффективно их использовать! Теперь, в качестве примеров, составим несколько простых SQL–запросов.
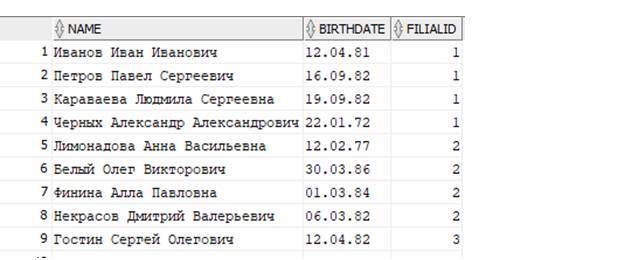
Напишем запрос, выбирающий сотрудников из таблицы Persons, который отображал бы их Фамилию Имя Отчество, Дату рождения и идентификатор филиала, в котором они работают. Фамилия Имя Отчество лежит в колонке NAME, Дата рождения – в колонке BIRTHDATE и идентификатор филиала – в графе FilialID:
Выполняем запрос и получаем результат:
Как видим, вывелись именно запрошенные столбцы из таблицы. И еще, первый столбец, – сквозная нумерация строк возвращаемых данных. Мы его не запрашивали нашей SQL–командой. И на самом деле, это не ORACLE нам его вернул вместе с возвращаемыми запросом данными, а сама программа через которою мы работаем в базе данных (в нашем случае программа SQL Developer) добавила нам его для удобства. Далее не будем обращать на него внимание.
Запрос вернул 21 запись (21 строку). В целях экономии места в книге, мы иногда будем отображать не все возвращаемые данные.
4.2. Использование условий при получении данных. Ключевое слово WHERE
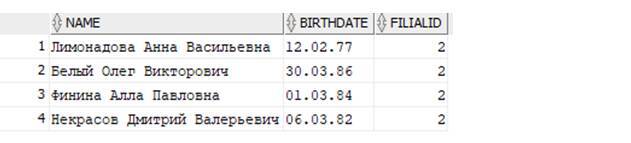
Теперь доработаем запрос, пусть он выведет только сотрудников, где в графе FilialID равно 2:
Как видим из получаемых данных, во втором филиале у нас работает 4 сотрудника!
СУБД ORACLE, выполняя команду SELECT, выбирает для нас такие строчки из всей таблицы Persons, где в колонке FilialID значение равно двум!
Какие символы, помимо знака равно, можно использовать в условиях:
Как мы видим, если в SQL запросе нужно выбрать данные с условием на неравенство, то мы можем написать как <>, так и !=.
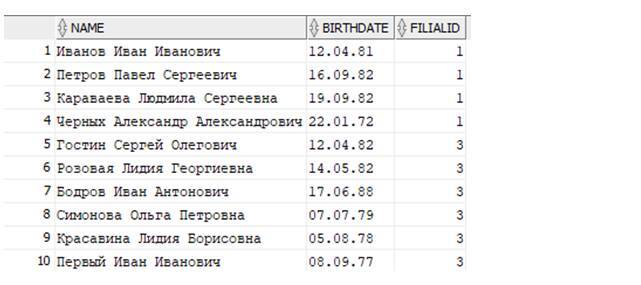
Следующей командой выберем сотрудников, работающих не во втором филиале:
Выведутся данные (всего 17 строк, для экономии места вот первых 10):
4.3. Сортировка данных. Блок ORDER BY
Теперь полученные данные мы можем еще и упорядочить по Фамилии Имени Отчеству. Для этого допишем блок ORDER BY.
В блоке ORDER BY (с англ. «упорядочить по») указали графу NAME, так как согласно значению в этом столбце нам необходимо было упорядочить строки. В результате получаем следующую таблицу с данными:
Как видим, строки упорядочены (отсортированы) по Фамилии Имени Отчеству. Точно также, если нам нужно было бы расставить сотрудников не в алфавитном порядке согласно их ФИО, а, например, согласно их дате рождения, то в боке ORDER BY указали бы BIRTHDATE.
Всякий раз, указывая значение столбца, по которому ведется сортировка строк, мы можем сортировать как в прямом порядке, так и в обратном. Для сортировки строк в обратном порядке нужно сразу после имени столбца написать слово DESC. И все!
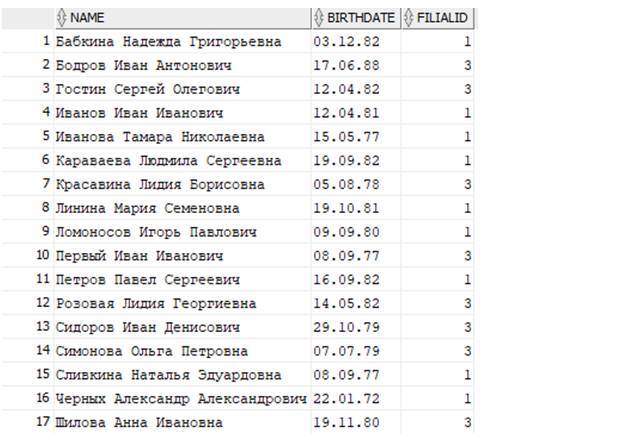
Выведем сотрудников третьего филиала, упорядоченных по Фамилии Имени Отчеству в обратном порядке:
Получаем: