Александру Наумову и Антону Коржу за предоставленный материал и консультации,
Виктору Дацюку, Павлу Костенецкому, Алексею Лацису и Юрию Хребтову за важные замечания.
Вадиму Кузнецову (dikbsd) за неоценимую помощь в конвертации книги в электронный формат.
Глава 1. Что же такое «супер»?
Общие понятия о параллельной обработке и параллельных программах
Все современные суперкомпьютеры используют параллельную обработку данных. С самого начала компьютерной эры именно этот путь был и остаётся наиболее важным для достижения высокой производительности. Сейчас даже самый простой настольный компьютер если не многоядерный, то уж почти наверняка с технологией simultaneous multithreading (например, HyperThreading от Intel или AMD SMT), позволяющей работать двум (иногда более) программным потокам одновременно. Даже мобильные телефоны и фотоаппараты становятся параллельными и многоядерными.
Принцип параллельной обработки данных прост: если две или более операции независимы (т. е. результаты их выполнения не влияют на входные данные друг друга), то эти операции можно выполнить одновременно, т. е. параллельно. В аппаратуре традиционно есть два варианта воплощения этого принципа – параллелизм и конвейеризация.
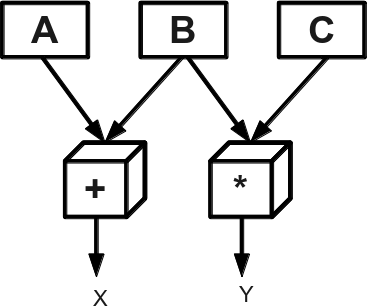
Параллелизм – параллельное выполнение машинных команд разными устройствами. Например, команды
x=a+b и y=b*c
, где
a
,
b
и
с
– регистры, процессор может выполнить независимо, если он имеет раздельные устройства сложения и умножения (см. рис. 1). Этот принцип воплощён в большинстве современных процессоров.
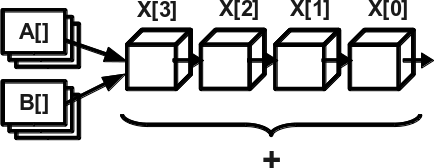
Конвейеризация – разделение команд на этапы, каждый из которых выполняется быстро отдельным элементом аппаратуры, и выполнение этих этапов происходит по принципу конвейера: друг за другом. Таким образом, одновременно может выполняться несколько команд на разных стадиях конвейера. Наиболее часто этот принцип используется в векторизации – выполнении однотипной операции над векторами, т. е. массивами данных, расположенными в памяти регулярно (см. рис. 2).
Рис. 1: Параллельное выполнение
Рис. 2: Векторизация + конвейер
Чаще всего элементы вектора расположены друг за другом. Типичный пример – сложение векторов. Так как операция, выполняющаяся над векторами, одна и та же, то её разбивают на фазы – ступени конвейера. Например, загрузка элементов из памяти, нормализация мантисс, сложение, коррекция, запись в память. После выполнения первой ступени над первым элементом вектора эту стадию можно сразу же выполнить над вторым элементом, не дожидаясь завершения всей операции над первым. После завершения каждой ступени над одним элементом можно выполнить её над следующим. Таким образом, если самая медленная ступень конвейера выполняется за
К
тактов, а все ступени – за
S
тактов, то вектор из
N
элементов обработается за
K*(N–1)+S
.
Первый элемент обработается за положенные
S
тактов (это называется «время разгона конвейера»), а потом устройство будет выдавать по одному результату в
K
тактов. В современных процессорах чаще всего
K=1
. Однако конвейеризация не обязательно подразумевает векторизацию и наоборот. Например, если устройство сложения конвейерное и мы выполняем несколько обычных сложений подряд, они могут отлично задействовать конвейер.
Для системного администратора не всегда нужно доскональное понимание работы процессора, языка ассемблера и умение оптимизировать пользовательские программы, но понимание того, как устроено параллельное выполнение в процессоре, очень важно. Многие современные процессоры многоядерные, т.е. содержат несколько полноценных (или почти полноценных) процессоров на одном кристалле (в одной микросхеме). Естественно, что они могут работать параллельно. Есть ещё параллелизм на уровне доступа к памяти, когда разные банки памяти могут работать независимо, а значит, отдавать или записывать данные быстрее. Есть также параллелизм на уровне работы с устройствами – можно заранее сформировать в памяти блок для записи на диск или для отправки по сети и «скомандовать» контроллеру выполнить запись/передачу. Далее процессор может выполнять другие действия, а данные из памяти в это время будут записываться на диск или пересылаться по сети.
Это параллелизм, заложенный в «железе». Для того, чтобы задействовать его максимально, заставить вычислители (ядра, процессоры, вычислительные узлы…) работать параллельно, необходимо составить программу таким образом, чтобы она использовала все эти ресурсы. Т. е. написать параллельную программу. Этим мы заниматься не будем (по крайней мере, в рамках этой книги), но иметь дело с параллельными программами нам придётся постоянно, и знать, как они работают, нам необходимо.[1]
Если я написал параллельную программу, значит ли это, что она тут же заработает быстрее обычной (последовательной)? Нет. Более того, она может работать даже медленнее. Ведь части, которые должны исполняться параллельно, в реальности могут конфликтовать друг с другом. Например, две нити обращаются к разным участкам памяти и не дают эффективно работать кэшу процессора. Или параллельные процессы постоянно вынуждены ждать данных от самого медленного из них. Или…
Вариантов неэффективного параллельного кода много, и если не удаётся достичь хорошего ускорения программы на суперкомпьютере, то, возможно, она неэффективно использует параллелизм. Выяснить реальную причину очень трудно, для этого необходимо использовать «отладчики производительности» – параллельные профилировщики, трассировщики или хотя бы мониторинг вычислительных узлов, по данным которого можно судить о том, что происходит во время работы программы.
Для нас в первую очередь интересен параллелизм на уровне процессов UNIX (в том числе на разных узлах) и нитей. Именно здесь заложен основной потенциал параллельных приложений. Именно такой параллелизм используют наиболее популярные среды параллельного программирования MPI и OpenMP. Это не значит, что на других уровнях этого потенциала нет, но именно отсюда всегда нужно начинать. Среды (технологии) параллельного программирования представляют собой библиотеки или языки программирования, позволяющие упростить написание параллельных программ.
Для администратора важно знать, как устроена каждая среда, как она реализована технически, так как при возникновении проблем с программами потребуется понять, в чём причина неполадки. Даже если причина – ошибка в программе, нужно уметь показать это пользователю и подсказать ему путь решения проблемы. Параллельные программы, как правило, пишутся в терминах нитей или параллельных процессов (или всего вместе). То есть один и тот же код программы выполняется в разных нитях одного процесса (на разных процессорных ядрах) или в разных процессах, которые могут работать и на разных узлах.
Такой подход позволяет максимально задействовать все процессорные ядра – на каждом выполняется свой процесс или поток. Действия разных процессов в одной программе необходимо согласовать, для этого в средах параллельного программирования предусмотрены разные механизмы: в MPI – передача сообщений, в OpenMP – общие переменные и автоматическое распараллеливание циклов и т. д. Технологии типа MPI – это не только указание особых функций и инструкций в коде, но и среда запуска программы. Особенно это относится к средам, использующим несколько вычислительных узлов, – ведь на каждом узле надо запустить экземпляр (а то и не один) программы и «подружить» его с остальными запущенными экземплярами той же программы (но не соседней). Вот тут и начинаются заботы системного администратора. Все установленные параллельные среды надо оптимально настроить, а при возникновении проблем – уметь расшифровать их диагностику.