Отличие NAS от SAN довольно условное, поскольку существует протокол обмена iSCSI, позволяющий использовать обычную локальную сеть в качестве сети хранения данных. В этом случае сетевое хранилище данных будет видно в операционной системе как локально подключённое дисковое пространство. Сеть хранения данных может объединяться с высокоскоростной коммуникационной сетью. Например, в качестве SAN-сети способна выступать InfiniBand, используемая для высокоскоростного обмена данными между вычислительными узлами кластера.
Особенности аппаратной архитектуры
Ни для кого не секрет, что в самом начале компьютерной эры понятия «процессор» и «ядро» (имеется в виду вычислительное ядро процессора) были синонимичными. Точнее, понятие «ядро» к процессору не относилось вовсе, поскольку многоядерных процессоров ещё не было. В каждом компьютере устанавливался обычно один процессор, который в каждый момент времени мог исполнять лишь один процесс. Современные системы такого типа можно встретить и сейчас, но они, как правило, предназначены для решения специальных задач (контроллеры, встраиваемые системы).
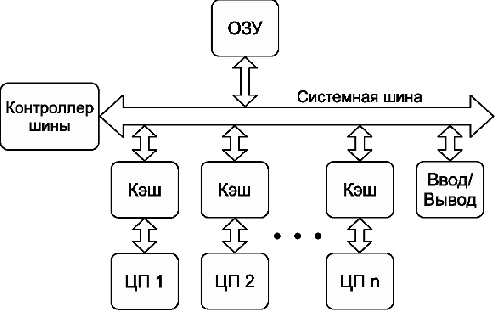
Для увеличения мощности сервера или рабочей станции производители устанавливали несколько «одноядерных» процессоров (обычно от двух до восьми). Такие системы существуют и сейчас и называются симметричными многопроцессорными системами, или SMP-системами (от англ. Symmetric Multiprocessor System) (см. рис. 4).
Рис. 4: симметричная многопроцессорная система (SMP)
Как видно из схемы, каждый процессор, представляющий собой одно вычислительное ядро, соединён с общей системной шиной. В такой конфигурации доступ к памяти для всех процессоров одинаков, поэтому система называется симметричной. В последнее время в каждом процессоре присутствует несколько ядер (обычно от 2 до 16). Каждое из таких ядер может рассматриваться как процессор в специфической SMP-системе. Конечно, многоядерная система отличается от SMP-системы, но эти отличия почти незаметны для пользователя (до тех пор, пока он не задумается о тонкой оптимизации программы).
Для ускорения работы с памятью нередко применяется технология NUMA – Non-Uniform Memory Access. В этом случае каждый процессор имеет свой канал в память, при этом к части памяти он подсоединён напрямую, а к остальным – через общую шину. Теперь доступ к «своей» памяти будет быстрым, а к «чужой» – более медленным. При грамотном использовании такой архитектуры в приложении можно получить существенное ускорение.
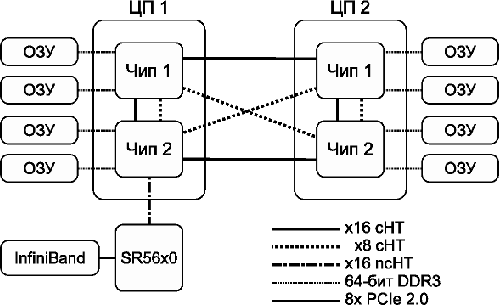
Рис. 5: схема узла NUMA на примере AMD Magny-Cours
Например, в архитектуре AMD Magny-Cours (см. рис. 5) каждый процессор состоит из двух кристаллов (логических процессоров), соединённых между собой каналами HyperTransport. Каждый кристалл (чип) содержит в себе шесть вычислительных ядер и свой собственный двухканальный контроллер памяти. Доступ в «свою» память идёт через контроллер памяти, а в «соседнюю» – через канал HyperTransport. Как видим, построить SMP- или NUMA-систему из двух или четырёх процессоров вполне возможно, а вот с большим числом процессоров – уже непросто.
Ещё одним «камнем преткновения» в современных многоядерных системах является миграция процессов между ядрами. В общем случае для организации работы множества процессов операционная система предоставляет каждому процессу определённый период времени (обычно порядка миллисекунд), после чего процесс переводится в пассивный режим.
Планировщик выполнения заданий, переводя процесс из пассивного режима, выбирает ядро, которое не обязательно совпадает с тем, на котором процесс выполнялся до этого. Нередко получается так, что процесс «гуляет» по всем ядрам, имеющимся в системе. Даже в случае с SMP-системами влияние на скорость работы программы при такой миграции заметно, а в NUMA-системах это приводит ещё и к большим задержкам при доступе в память.
Для того, чтобы избавиться от паразитного влияния миграции процессов между ядрами, используется привязка процессов к ядрам (processor affinity, или pinning). Привязка может осуществляться как к отдельному ядру, так и к нескольким ядрам или даже к одному и более NUMA-узлам. С применением привязки миграция процессов или будет происходить контролируемым образом, или будет исключена вовсе.
Аналогичная проблема присутствует и в механизме выделения памяти пользовательским процессам. Допустим, процессу, работающему на одном NUMA-узле, требуется для работы выделить дополнительную память. В какой области памяти будет выделен новый блок? А вдруг он попадёт на достаточно удалённый NUMA-узел, что резко уменьшит скорость обмена? Для того, чтобы избежать выделения памяти на сторонних узлах, есть механизм привязки процессов к памяти определённого NUMA-узла (memory affinity).
В нормальном случае каждый процесс параллельной программы привязывается к определённым NUMA-узлам как по ядрам, так и по памяти. В этом случае скорость работы параллельной программы не будет зависеть от запуска и будет достаточно стабильной. При запуске параллельных программ такая привязка не просто желательна, а обязательна. Более подробно данный вопрос рассмотрен в главе «Библиотеки поддержки параллельных вычислений», где описываются различные среды параллельного программирования.
В большинстве современных процессоров компании Intel используется технология HyperThreading. Благодаря этой технологии каждое вычислительное ядро представлено в системе как два отдельных ядра. Конечно, эффективность использования аппаратных ресурсов в этом случае сильно зависит от того, как написана программа и с использованием каких библиотек и каким компилятором она собрана. В большинстве случаев параллельные вычислительные программы написаны достаточно эффективно, поэтому ускорения от использования технологии HyperThreading может не быть, и даже наоборот, будет наблюдаться замедление от её использования.
На суперкомпьютерах эта технология вообще может быть отключена в BIOS каждого узла, чтобы не вносить дополнительных трудностей в работу параллельных программ. Как правило, эта технология не приносит ускорения для вычислительных программ. Если вы используете небольшой набор программ на суперкомпьютере, проверьте их работу с включённым и отключённым HyperThreading и выберите лучший вариант. Обычно мы рекомендуем включить её, но при этом указать системе управления заданиями число ядер, как с отключённым HT. Это позволяет получить дополнительные ресурсы для системных сервисов, минимально влияя на работу вычислительных заданий.
Ещё одна особенность архитектуры касается уже не отдельного, а нескольких узлов. Как мы ранее указывали, вычислительные узлы в вычислительном кластере объединены высокоскоростной коммуникационной сетью. Такая сеть может предоставлять дополнительные возможности обмена данными между процессами параллельных программ, запущенных на нескольких вычислительных узлах. В рамках одного узла применяется технология прямого доступа в память (Direct Memory Access, или DMA), позволяющая устройствам узла связываться с оперативной памятью без участия процессора. Например, обмен данными с жёстким диском или с сетевым адаптером может быть организован с использованием технологии DMA.
Адаптер InfiniBand, используя технологию DMA, предоставляет возможность обращаться в память удалённого узла без участия процессора на удалённом узле (технология Remote Direct Memory Access, или RDMA). В этом случае возникнет необходимость синхронизации кэшей процессоров (данный аспект мы не будем рассматривать подробно). Применение технологии RDMA позволяет решить некоторые проблемы масштабируемости и эффективности использования ресурсов.