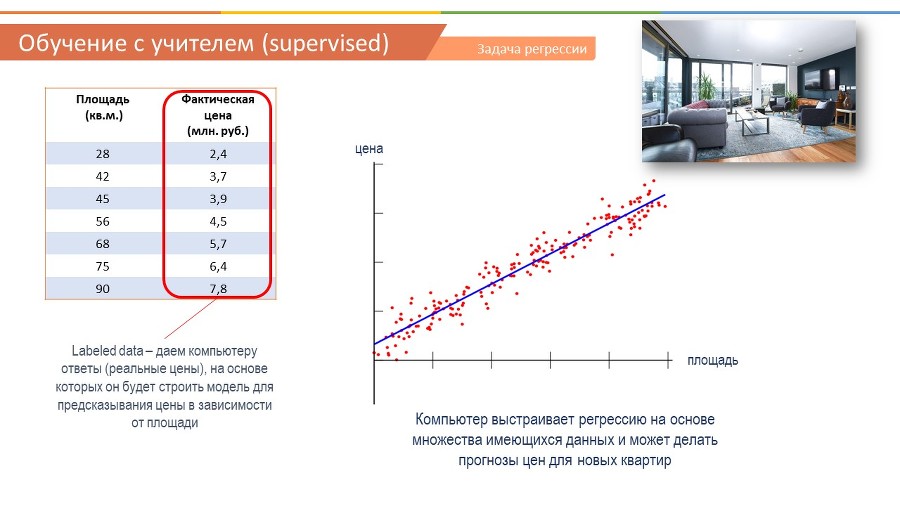
Таким образом, если суммировать, то в обучении с учителем – ключевая фраза – это labeled data или помеченные данные. То есть мы загружаем в нашу модель данные с ответами, будь то класс, к которому принадлежит тот или иной объект или реальная цена квартиры в зависимости от площади. На основе этой информации модель учится и создает алгоритм, который может делать прогнозы.
Идем дальше. Второй вид машинного обучения – это обучение без учителя. Это когда мы позволяем нашей модели обучаться самостоятельно и находить информацию, которая может быть не видна очевидно для человека.
В отличие от обучения с учителем, модели, которые используются в обучении без учителя, выводят закономерности и выводы на основе немаркированных данных (или unlabeled data). Помните, у нас был пример с цветками ириса. Так вот в данных, которые мы давали компьютеру, присутствовали ответы какой вид ириса мы имеем в зависимости от тех или иных размеров лепестка и чашелистника. А в немаркированных данных, у нас имеются данные и признаки, но мы не имеем ответа к какому виду или классу они относятся. Поэтому такие данные называются немаркированные.
В обучении без учителя основными типами задач являются Кластеризация и снижение размерности. Если в двух словах, то снижение размерности означает, что мы удаляем ненужные или излишние признаки из наших данных, чтобы облегчить классификацию наших данных и сделать ее более понятной для интерпретации.
Давайте рассмотрим пример кластеризации.
В задачах кластеризации у нас имеется набор объектов и нам надо выявить его внутреннюю структуру. То есть нам надо найти группы объектов внутри этого набора, которые наиболее похожи между собой, и отличаются от других групп объектов из этого же набора. Например, разобрать все движущиеся средства по категориям, например, все средства, похожие на велосипед, в одну группу или кластер, а похожие на автобус – в отдельную группу. Причем, мы не говорим компьютеру, что чем является, он должен самостоятельно найти схожие признаки и определить похожие объекты в ту или иную группу. Поэтому это и называется обучение без учителя, потому что мы не говорим изначально компьютеру к какой группе принадлежат те или иные объекты.
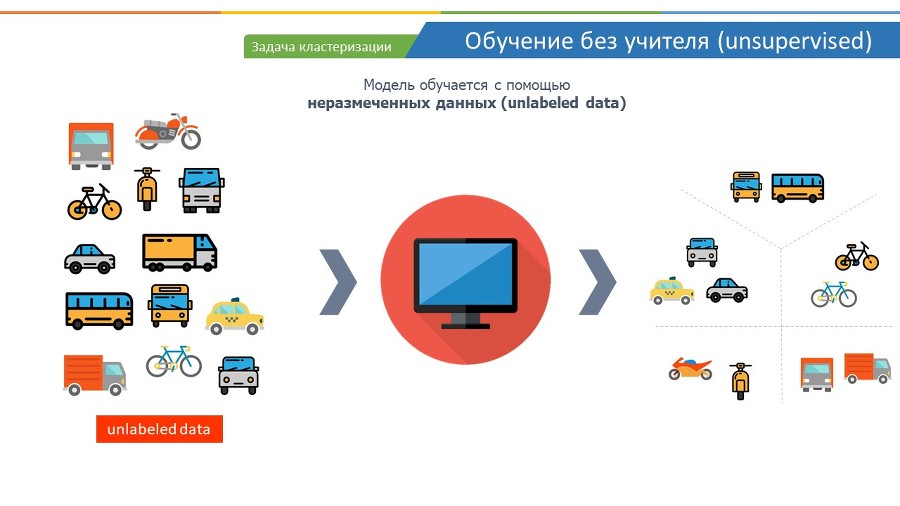
Такие задачи бывают очень полезны для крупных ритейлеров, если они, например, хотят понять из кого состоят их клиенты. Предположим, есть крупный гипермаркет, и чтобы делать точечные рекламные акции для своих потребителей, ему необходимо будет разбить их по группам или кластерам. И если сейчас акция на спортивные товары, то отправлять информацию об этой акции не всем подряд потребителям, а только тем, кто в прошлом уже покупали спортивные товары.
Таким образом, основная разница между обучением с учителем и обучением без учителя, это то, что в обучении с учителем мы используем маркированные данные, где каждый объект помечен и относится к тому или иному классу или имеет конкретное числовое значение. И на основе этих помеченных данных наша модель строит алгоритм, который помогает нам прогнозировать результаты при новых данных. А в обучении без учителя, имеющиеся у нас данные непромаркированы, и компьютер самостоятельно выводит определенные закономерности и общие признаки и разделяет все объекты на разные группы, схожие внутри одной группы и отличающиеся от объектов в других группах.
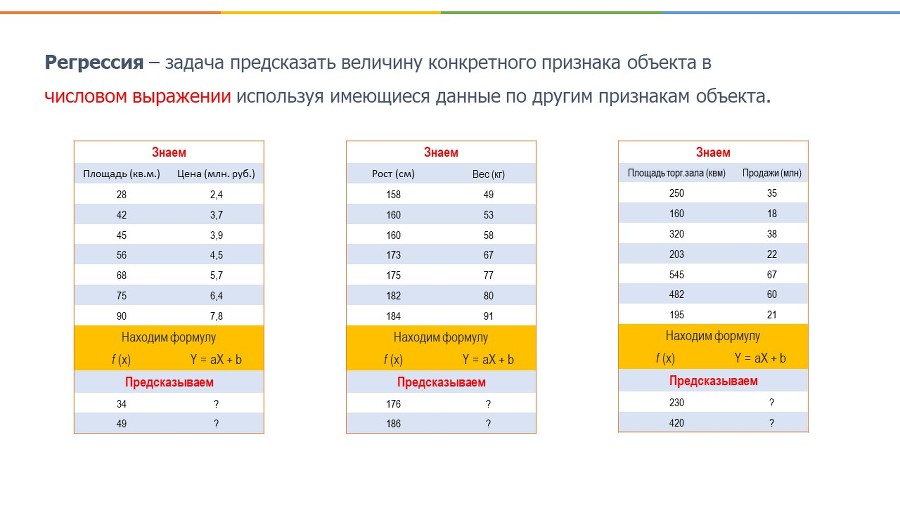
Основные задачи обучения с учителем разделяются на два типа: Классификация, когда мы разделяем наши данные на классы, и Регрессия, когда мы делаем численный прогноз на основе предыдущих данных.
Основные задачи обучения без учителя включают в себя кластеризацию, когда компьютер делит наши данные на группы или кластеры. И снижение размерности, которое необходимо для более удобной демонстрации больших объемов данных.
Указанные задачи мы рассмотрим более подробно в следующих главах.
Регрессия
Итак, одной из самых популярных задач машинного обучения является регрессия. Это задача определить какую-то величину в цифрах (например, вес человека, стоимость квартиры, объем продаж) используя известную информацию (рост, площадь, удаленность от метро, сезонность).
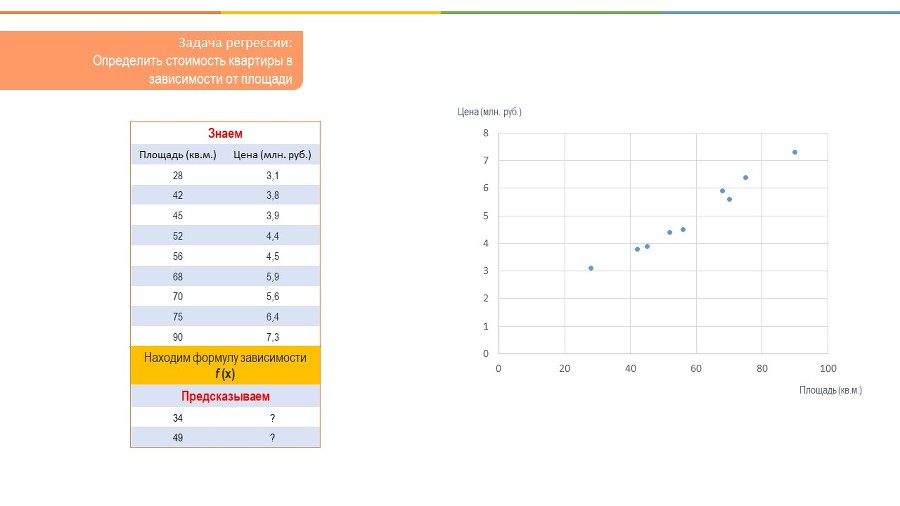
Давайте возьмем пример с предсказанием стоимости квартиры в зависимости от площади. Для любой задачи машинного обучения нужны данные, и чем больше, тем лучше. Так вот, представим, что у нас есть табличка с данными, в одном столбце площадь квартиры, в другом цена этой квартиры.
Мы располагаем эти данные на графике и в принципе можем заметить, что тут имеется определенная линейная зависимость, которая достаточно очевидна, что чем больше площадь, тем выше стоимость квартиры. Понятное дело, что на стоимость квартиры будет влиять намного больше факторов, как например, удаленность от центра города и от метро, этажность, возраст дома и т.д. Но для упрощения, возьмем всего один признак – площадь квартиры.
Так вот, наша задача – научиться предсказывать цену. Для этого нам нужна будет формула, с помощью которой мы сможем подставлять площадь, и нам будет выдаваться цена.
В данном случае мы видим линейную зависимость, и в таких ситуациях используется формула прямой Y = AX + B, в которой Y = цена, X – площадь.
На самом деле, зависимость необязательно будет линейной, она может быть кривой, либо иметь совсем странный вид.
Так вот, чтобы у нас была конкретная рабочая формула, нам надо найти коэффициенты А и В.
Как это можно сделать? Самый простой классический способ, который вы наверняка проходили на уроках алгебры или статистики – это метод наименьших квадратов. На самом деле этот метод был придуман еще 200 лет назад, и сейчас появились более эффективные решения, но тем не менее метод наименьших квадратов по-прежнему актуален и используется достаточно часто в задачах регрессии.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.