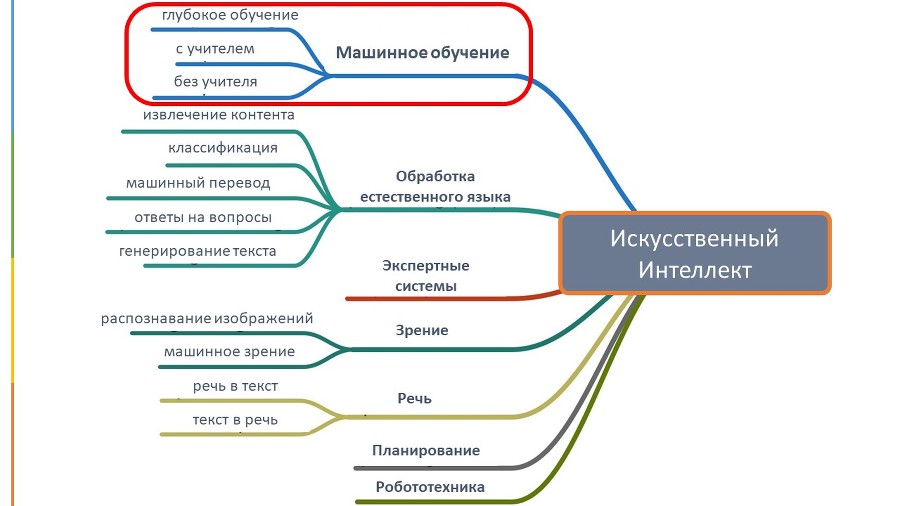
6. Автоматическое планирование – обычно используется автономными роботами и беспилотными аппаратами, когда им необходимо выполнять последовательность действий, особенно когда это происходит в многомерном пространстве и когда им приходится решать комплексные задачи.
7. И наконец, Машинное обучение.
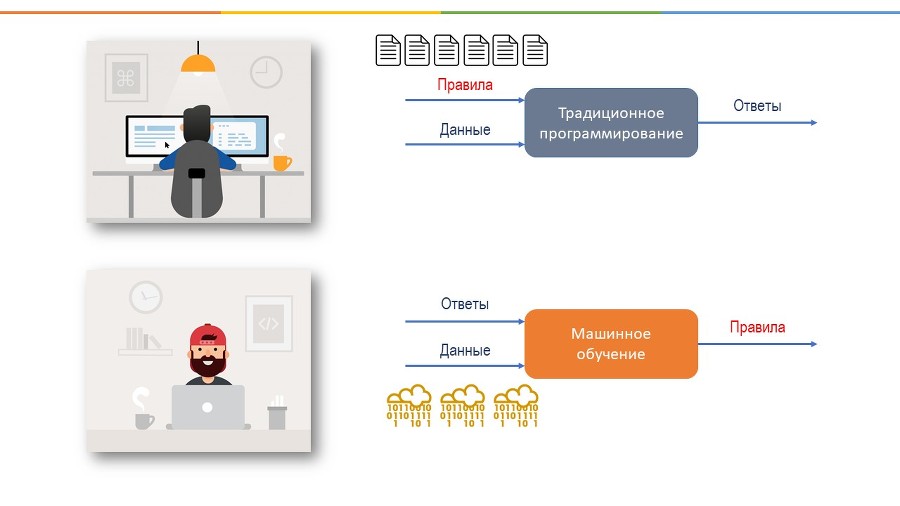
Машинное обучение появилось после того, как долгое время мы пытались сделать компьютер умнее, давая ему все больше и больше правил и инструкций. Однако, это оказалось не такой уж и хорошей идеей, потому что отнимало много времени, и мы не могли придумать правила для каждой детали и для каждой ситуации.
И тогда ученые пришли к выводу, а почему бы не написать алгоритмы, которые учатся самостоятельно на основе опыта. Так родилось машинное обучение. То есть, когда машины могут учиться на основе больших наборов данных вместо явно написанных инструкций и правил.
МО – это область ИИ, когда мы тренируем наш алгоритм с помощью набора данных, делая его все лучше, точнее и более эффективным. При машинном обучении наши алгоритмы обучаются на основе данных, но без заранее запрограммированных инструкций. То есть мы даем машине большой набор данных, и говорим правильные ответы, и потом машина сама создает алгоритмы, которые бы удовлетворяли этим ответам. И с каждым новым дополнительным объемом данных, машина учится дальше и еще больше улучшает свою точность прогнозов.
Например, если взять пример шахмат, то в примере с ИИ, мы даем машине много логических правил, и на их основе она учится играть. А в примере с МО, мы даем машине много примеров прошлых игр, она изучает их и анализирует почему одни игроки выигрывали, а другие проигрывали, какие шаги вели к успеху, а какие – к поражению. И на основе этих примеров, машина сама создает алгоритмы и правила как надо играть в шахматы, чтобы выиграть.
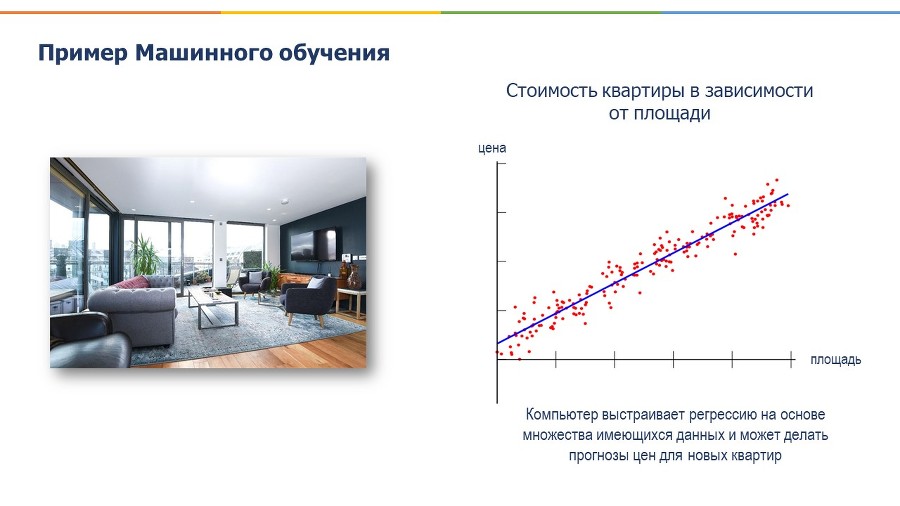
Другой пример, предположим, нам надо понять, как будет вести себя цена квартиры при изменении тех или иных параметров, например, в зависимости от площади, удаленности от метро, этажности и прочих факторов. Мы загружаем данные с разными квартирами, и компьютер создает модель, по которой можно будет предсказать цены в зависимости от этих факторов. Мы можем регулярно обновлять эти данные, и наш алгоритм будет обучаться на основе этих новых данных и каждый раз будет усовершенствовать свою точность по предсказанию цены в зависимости от параметров.
Идем дальше. Глубокое обучение – это подотрасль МО, то есть здесь тоже компьютер обучается, но обучается немного по-другому, чем в стандартном МО. В ГО используются нейронные сети (НС), которые представляют собой алгоритмы, повторяющие логику нейронов человеческого мозга. Большие объемы данных проходят через эти нейронные сети, и на выходе выдаются уже готовые ответы. Нейронные сети намного сложнее, чем обычное машинное обучение, и мы можем не всегда понимать, какие факторы имеют больший вес на тот или иной ответ, но использование нейронных сетей также помогает решать очень запутанные задачи в наше время. Иногда нейронные сети называют даже черным ящиком, потому что мы не всегда можем понять, что происходит внутри этих сетей.
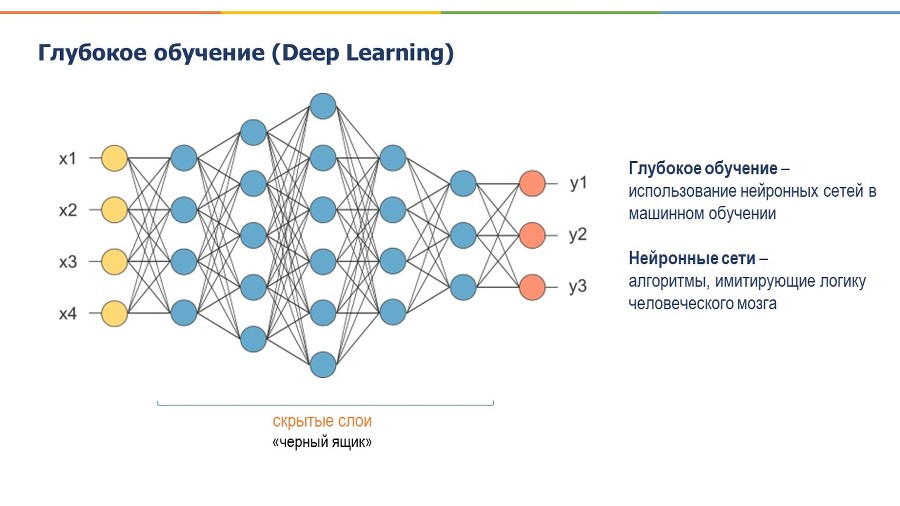
Предположим, ваш компьютер оценивает, насколько хорошо написано эссе. Если вы используете ГО, то компьютер вам просто выдаст финальное решение, что эссе хорошее либо нет, и скорее всего, ответ будет очень близок к тому, как бы оценил это эссе человек. Но вы не сможете понять, почему было принято такое решение, потому что в ГО используются несколько уровней НС, что делает его очень трудно интерпретируемым. Вы не будете знать какой узел НС был активирован, и как эти узлы вели себя вместе, чтобы прийти к этому результату. Если же вы используете МО, например, алгоритм «дерево решений», то там видно какой фактор сыграл решающую роль в определении качества эссе.
Нейронные сети были известны еще в 20 веке, но тогда они были не настолько глубокими, там был всего один или два слоя, и они не давали таких хороших результатов, как другие алгоритмы МО. Поэтому на какое-то время они отошли на второй план. Однако они стали популярны в последнее время, особенно примерно с 2006 года, когда появились огромные наборы данных и сильные компьютерные мощности, в частности, видео карты и мощные процессоры, которые стали способны создавать более глубокие слои НС и делать вычисления более эффективно.
По этим же причинам, ГО является достаточно дорогим. Потому что, во-первых, сложно собрать большие данные по определенным признакам и, во-вторых, серьезные вычислительные способности компьютеров – тоже достаточно дорогое удовольствие.
Если вкратце, то каким образом работает ГО. Предположим, наша задача вычислить сколько единиц транспорта и какой именно транспорт (то есть автобусы, грузовики, машины или велосипеды) проходит через определенную трассу в день, чтобы в дальнейшем распределить полосы движения.
Для этой цели нам надо научить наш компьютер распознавать виды транспорта. Если бы мы решали эту задачу с помощью МО, мы бы написали алгоритм, в котором указывали бы характеристики машин, автобусов, грузовиков и велосипедов, например, если количество колес 2, то мотоцикл, если длина движущегося средства более 5 метров, то грузовик либо автобус, если много окон, то автобус, и т.д. Но как понимаете, здесь много подводных камней. Например, автобус может быть затонированным и будет трудно понять, где там окна, либо грузовик может выглядеть как автобус или наоборот, да и крупные машины пикапы выглядят как некоторые небольшие грузовики.
Поэтому другой вариант решения этой задачи, это загрузить большое количество изображений с разными видами транспорта в наш компьютер и просто указать ему, на каких изображениях изображен мотоцикл, автомобиль, грузовик или автобус. Компьютер сам начнет подбирать характеристики, по которым можно определить, что за вид транспорта изображен и как их можно отличить друг от друга. После этого мы загрузим еще некоторое количество изображений и протестируем насколько хорошо компьютер справляется с задачей. Если он будет ошибаться, мы укажем ему, что вот здесь ты ошибся, здесь не грузовик, а автобус. Компьютер, в свою очередь, вернется назад к своим алгоритмам (это называется backpropagation) и внесет туда какие-то изменения, и мы начнем заново по кругу до тех пор, пока компьютер не начнет угадывать, что изображено на картинке с очень большой долей вероятности. Это и называется глубокое обучение на основе нейронных сетей. Как вы понимаете, это может занимать достаточно долгое время, может быть несколько недель, в зависимости от сложности поставленной задачи, также требует наличия большого количества данных, желательно, чтобы было от миллиона изображений и выше, и все эти изображения должны либо быть промаркированы, либо это должен делать человек, но это будет очень затратно по времени.
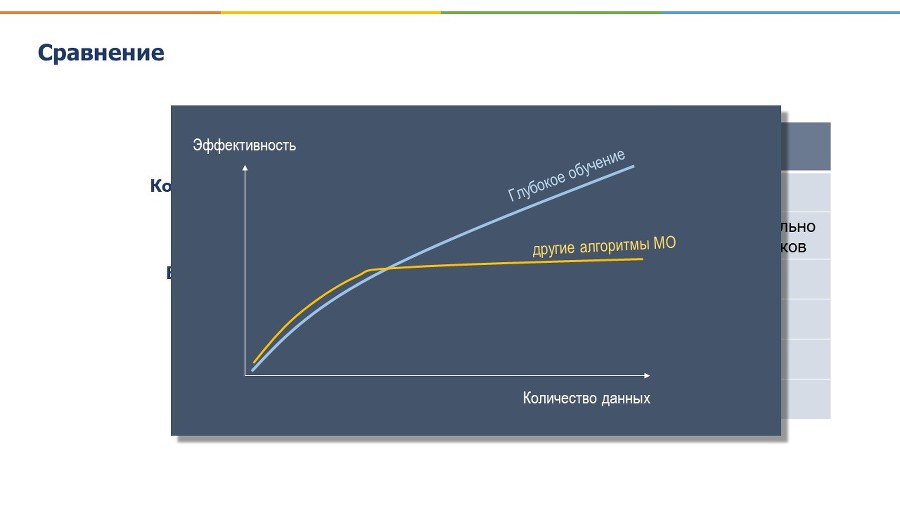
Давайте еще раз сравним МО и ГО по разным параметрам.
Если суммировать:
ГО является подобластью МО, и они оба подпадают под более широкое определение ИИ.
МО использует алгоритмы, чтобы разбирать данные, обучаться на их основе, и принимать взвешенные решения на основе обученного.
ГО делает то же самое, так как оно тоже является разновидностью МО, но специфика ГО в том, что при нем алгоритмы структурируются в несколько слоев, чтобы создать искусственную нейронную сеть, которая может тоже обучаться и принимать умные решения.