сгруппированные_по_дням <– group_by(flights, year, month, day)
summarise(сгруппированные_по_дням,
средняя_задержка_рейсов_по_датам = mean(dep_delay, na.rm = TRUE))
Вызов функций group_by() совместно с summary() чаще всего используется при работе в пакете dplyr для получения статистических отчетов по группам. Но прежде, чем погрузиться в детали, дополнительно изложим одну техническую идею, касающуюся обработки информации путём её направления по специальным каналам. Представьте, что хотим исследовать закономерность между расстоянием и средней задержкой рейса для каждого пункта назначения. Опираясь на имеющиеся знания о возможностях dplyr, для этого достаточно использовать такой код:
группы_рейсов_по_месту_назначения <– group_by(flights, dest)
задержки <– summarise(группы_рейсов_по_месту_назначения,
опозданий = n(), средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE))
Оставим в выборке рейсы имеющие более сотни регулярных опозданий и, например, не на московских направлениях:
задержки <– filter(задержки, опозданий > 100, dest != "MSK")
Визуализируем оставшиеся записи:
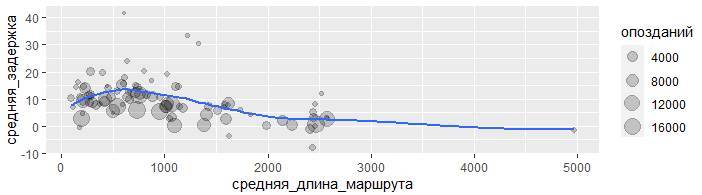
ggplot(data = задержки, mapping =
aes(x = средняя_длина_маршрута, y = средняя_задержка)) +
geom_point(aes(size = опозданий), alpha = 1/5) +
geom_smooth(se = FALSE)
Похоже, что задержки растут с увеличением расстояния до ~750 миль, а затем сокращаются. Неужели, когда рейсы становятся длиннее, появляется возможность компенсировать опоздание находясь в полёте?
Предварительно было пройдено три вспомогательных этапа подготовки данных:
1. Сгруппированы рейсы по направлениям.
2. В каждой из групп усреднены расстояния, длительность задержки и вычислено количество опоздавших рейсов.
3. Отфильтрованы шумы и аэропорт, который не подчиняется законам логики.
Этот код немного перегружен, так как каждому промежуточному блоку данных присвоено имя. Вспомогательные таблицы сохранялись, даже когда их содержимое не востребовано на заключительном этапе, и замедляли анализ. Но есть отличный способ справиться с обозначенной проблемой посредством настройки каналов передачи данных служебным оператором %>%:
задержки <– flights %>%
group_by(dest) %>%
summarise(
опозданий = n(),
средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE) ) %>%
filter(опозданий > 100, dest != " MSK ")
Такой синтаксис фокусирует внимание исследователя на выполняемых преобразованиях, а не на том, что получается на каждом из вспомогательных этапов, и делает код более читаемым. Это звучит как ряд предписаний: сгруппируй, после этого подведи итоги, после этого отфильтруй полученное. Как подсказывает здравый смысл, можно читать %>% в коде как «после этого». По сути же, формируется информационный канал последовательной передачи данных на обработку от одной функции через другую к третьей. Технически, x %>% f(y) превращается в f(x, y), а x %>% f(y) %>% g(z) превращается в композицию функций g(f(x, y), z) и так далее, что позволяет использовать канал для объединения нескольких операций в одну, которую можно читать слева направо, сверху вниз. Будем часто пользоваться каналами, так как это значительно упрощает читаемость кода, разберём их более подробно в соответствующем разделе.
Работа с каналами это одна из ключевых особенностей tidyverse. Единственным исключением является ggplot2, так как библиотека была написано до появления такой возможности в R. К сожалению, являющаяся наследником ggplot2 библиотека ggvis хотя и поддерживает работу с каналами, но пока еще не в полной мере.
Внимательный читатель наверняка задавался вопросом о смысле и предназначении аргумента na.rm. Что будет, если его не писать? Получим много пропущенных значений! Дело в том, что агрегационные функции подчиняются обычному правилу пропущенных значений: если на входе есть какое-либо отсутствующее значение, то выход будет отсутствующим значением. К счастью, все функции агрегации имеют аргумент na.rm, который удаляет пропущенные значения перед началом вычислений. В том случае, где пропущенные значения представляют отмененные рейсы, мы также могли бы решить эту проблему, сначала удалив отмененные рейсы. Сохраним этот набор данных, чтобы использовать его повторно в нескольких следующих нескольких примерах:
неотмененные <– flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
Сгруппируем получившиеся данные о неотмененных рейсах по датам и посчитаем среднюю задержку на каждую дату в отдельности:
неотмененные %>%
group_by(year, month, day) %>%
summarise(средняя_задержка = mean(dep_delay))
Всякий раз, когда осуществляется подобная агрегация, правилом хорошего тона является добавление счетчика числа учтенных значений функцией n(), либо путём подсчета используемых непустых значений командой sum(!is.na(x)). Таким способом можно удостовериться, что не делается поспешных выводов на основании выборок очень малых объемов. Например, сгруппировав рейсы по бортовому номеру, хранящемуся в переменной tailnum из таблицы неотмененных рейсов, на графике посмотрим каковы самые высокие задержки в среднем на борт:
задержки <– неотмененные %>%
group_by(tailnum) %>%
summarise(
средняя_задержка = mean(arr_delay)
)
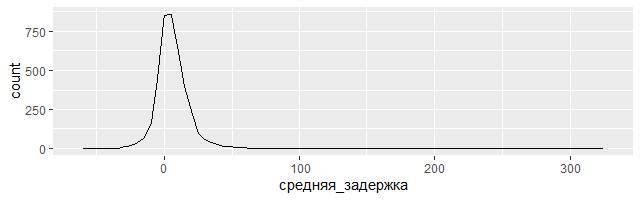
ggplot(data = задержки, mapping = aes(x = средняя_задержка)) +
geom_freqpoly(binwidth = 5)
Неужели много самолетов со средней задержкой рейса более 5 часов (300+ минут)? На самом деле не всё так печально, как могло показаться при поверхностном ознакомлении. Можно получить более глубокое представление об опозданиях, если нарисовать диаграмму рассеяния количества рейсов относительно средней задержки:
задержки <– неотмененные %>%
group_by(tailnum) %>%
summarise(
средняя_задержка = mean(arr_delay, na.rm = TRUE),
количество_выполненных_рейсов = n()
)
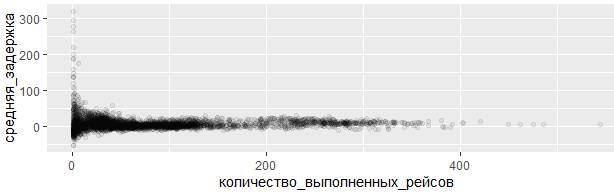
ggplot(data = задержки, mapping = aes(x = количество_выполненных_рейсов,
y = средняя_задержка)) +
geom_point(alpha = 1/15)
Неудивительно, что на частых рейсах задержек практически не наблюдается, а в основном задерживаются те борта, чьих рейсов мало. Что характерно, и в принципе соответствует статистическому закону больших чисел: всякий раз, когда ищется среднее значение (или другая сводка) в сравнении с размером группы, приходят к выводу, что вариативность вычисленного значения уменьшается по мере увеличения объема выборки.
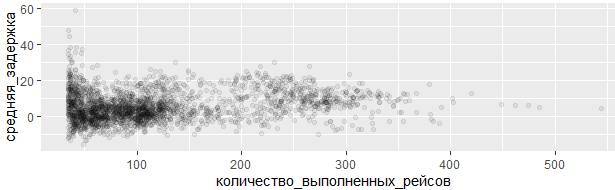
Именно поэтому, когда решаете аналогичные задачи, полезно отфильтровывать группы с наименьшим количеством наблюдений, тогда можно будет увидеть общие закономерности и уменьшить выбросы значений на малых группах. На примере следующего кода будет демонстрирован удобный шаблон интеграции ggplot2 с каналами в dplyr. Немного странным может показаться смешение стилей %>% и +, дело привычки, со временем это станет естественным. Отфильтруем на предыдущем графике экспериментальные самолёты с малым количеством вылетов, не превышающим 33:
задержки %>% filter(количество_выполненных_рейсов > 33) %>%
ggplot(mapping = aes(x = количество_выполненных_рейсов,
y = средняя_задержка)) +
geom_point(alpha = 1/15)
Полезным сочетанием клавиш RStudio является Ctrl + Shift + P, для повторной отправки ранее отправленного фрагмента из редактора в консоль. Это очень удобно, когда экспериментируете с граничным значением 33 в приведенном выше примере: отправляете весь блок в консоль нажатием Ctrl + Enter, а затем изменяете значение границ фильтрации на новое и нажимаете Ctrl + Shift + P, чтобы повторно отправить весь блок в консоль.