tidyverse_update()
Есть много разных пакетов, которые не являются частью tidyverse, они либо решают задачи статистического анализа немного иначе, либо предназначены для использования других парадигм представления информации. Это не делает их лучше или хуже, они просто иные. По мере ознакомления с R, обязательно узнаете про новые пакеты и новые способы представления данных. В книге будем использовать как правило три вспомогательных пакета из-за ограничений tidyverse. Так как в них предоставлены данные о мировом развитии, рейсах авиакомпаний и бейсболе, то присутствуют некоторые сведения об успеваемости, развитии, различные оценки и тесты, поэтому мы будем использовать их для иллюстрации ключевых идей науки о педагогических данных.
Выше было показано несколько примеров выполнения кода на языке R. Код в книге выглядит так:
1 + 2
#[1] 3
Если запустите тот же код в своей локальной консоли, он будет выглядеть так:
> 1 + 2
[1] 3
Как видим, в консоли код вводится после приглашения, символа «>», его не будем дублировать в книге. Выходные же данные порой закомментированы с помощью «#»; а в консоли они появляется непосредственно после кода. Эти два различия означают, что если работаете с электронной версией книги, то сможете легко копировать код из книги и вставлять его в консоль. Кроме того, на протяжении всей книги будем пользоваться следующими договоренностями в тексте кода:
1) Функции находятся в шрифте кода и завершаются скобками, например sum().
2) Другие объекты R, например, данные или аргументы функции, записываются без скобок.
3) Если из контекста не ясно, какой объект из какого пакета, то будем использовать имя пакета, за которым следуют два двоеточия и имя объекта. Этими допущениями изобилует код R.
С другой стороны, эта книга не единственна в своём роде, есть много людей и онлайн-ресурсов, помогающих освоить R. Как только начнете применять техники, описанные в этой книге к вашим данным, наверняка возникнут вопросы, на которые здесь нет ответа. Приведём несколько советов, как получить помощь, чтобы продолжить обучение. Если не знаете, с чего начать, начните с Yandex. Как правило, добавления «R» к поисковому запросу достаточно, чтобы повысить релевантность поисковой выдачи: если поиск не удался, это часто означает, что нет доступных для R результатов, но Yandex особенно полезен для поиска сообщений об ошибках. Если же получаете сообщение об ошибке и Yandex понятия не имеет, что это значит, попробуйте погуглить. Скорее всего, кто-то ранее уже сталкивался с подобным, и обращался за помощью где-нибудь в интернете. Если сообщение об ошибке не отображается на русском, то в консоли введите
Sys.setenv(LANGUAGE = "ru")
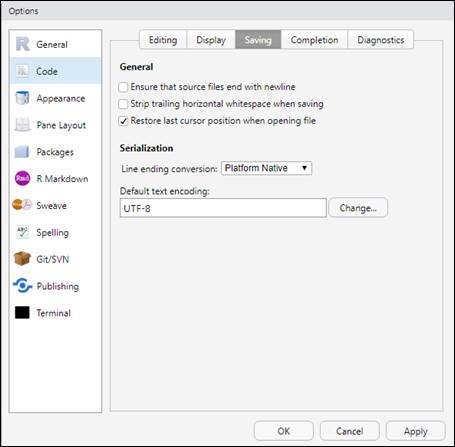
и повторите запуск кода; с большей вероятностью найдете справку для сообщения об ошибке на русском языке. При этом, удастся избежать многих проблем совместимости кода, написанного членами международных исследовательских команд, если настроите RStudio через меню Tools/Global Options на использование UTF-8 в качестве кодировки по умолчанию, как это показано на следующей иллюстрации:
Если Yandex не помогает, то попробуйте ru.stackoverflow.com. Начните с того, чтобы потратить немного времени на поиск существующего ответа, в том числе по тэгу [R], чтобы ограничить ваш поиск вопросами и ответами, которые используют R. Если не нашли ничего полезного, то подготовьте краткий воспроизводящий ошибку пример. Удачный пример делает его более доступным для других людей, чтобы они смогли помочь вам, и часто искореняет проблему в процессе его подготовки.
Есть три вещи, которые нужно описать, чтобы сделать ваш пример воспроизводим другими: необходимые пакеты, используемые данные и код.
1) Пакеты должны загружаться в самом начале скрипта, чтобы можно было увидеть, какие из них понадобятся в примере. При этом, хорошо не лишним будет проверить, что используете последнюю версию каждого пакета; возможно, разработчики обнаружили ошибку ранее и она уже была исправлена с момента установки пакета. Для пакетов из комплекта tidyverse самый простой способ – запустить tidyverse_update().
2) Самый простой способ включить свои данные в вопрос, это использовать dput () при создании кода R. Например, чтобы воссоздать набор данных mtcars в R, достаточно выполнить следующее шаги:
а) Запустите dput (mtcars) в R
б) Скопируйте выходные данные
в) В демонстрационном скрипте введите mtcars<– и вставьте ранее скопированное. Попробуйте найти наименьшее подмножество ваших данных, которое приводит к появлению проблемы.
3) Потратьте немного времени на то, чтобы проверить, что ваш код легко читается другими участниками. Для этого: убедитесь, что использовали пространство и ваш имена переменных лаконичны, но информативны; используйте комментарии, чтобы указать, где именно возникла проблема; сделайте все возможное, чтобы удалить все, что не связано с демонстрируемой проблемой. Чем короче ваш код, тем проще его использовать, понять, и тем легче его исправить.
4) Закончите, проверив, что действительно сделали воспроизводимый пример путем запуска нового сеанса R, копирования и вставки своего скрипта внутрь.
В любом случае, необходимо потратить некоторое время на подготовку, чтобы можно было решать проблемы до их возникновения. Инвестирование времени в обучение R каждый день на долгосрочной перспективе окупится сторицей. Принимайте активное участие в обсуждениях перспективных проектов на блоге RStudio, там размещаются объявления о новых пакетах, публикуются новые возможности интегрированной среды разработки и разрабатываются индивидуальные курсы. Чтобы идти в ногу со временем и сообществом R в более широком смысле, рекомендуется чтение http://www.r-bloggers.com: оно объединяет более 700 блогов пользователей R со всего мира. Если являетесь активным участником социальной сети Twitter, то подпишитесь на обновления по хэштегу #rstats, так как Twitter является одним из ключевых инструментов, который используют разработчики на R. Эта книга не просто вольный пересказ новостей компании занимающейся активной разработкой R, а результат долгой и плодотворной самостоятельной работы. С публикациями автора, в которых оказались применены описываемые инструменты статистической обработки информации в педагогических, биологических и химических областях на базе научных и исследовательских лабораторий ОмГПУ, можно ознакомиться на сайте https://www.researchgate.net.
§2. Визуализация и преобразование данных
Цель первой главы состояла в том, чтобы получить быстрое знакомство с основными инструментами исследования данных. Ведь исследование данных это в первую очередь искусство просмотра ваших данных, быстрая генерация гипотез, быстрая их проверка, а затем повторение этого процесса снова, и снова. Цель предварительного исследования данных заключается в том, чтобы сгенерировать как можно больше многообещающих идей, которые можете будет развить позднее.
Во второй части книги изложены некоторые полезные инструменты, которые дают немедленную отдачу по следующим причинам:
1) Визуализация прекрасна для начала работы в R, потому что выигрыш очевиден, научитесь делать элегантные и информативные графики, которые помогут понять собранные данные. Погрузитесь в визуализацию изучая основное содержимое библиотеки ggplot2, и узнаете мощные методы превращения табличных данных в графики.
2) Визуализация сама по себе, как правило, не является достаточной для полноценного исследования, потому что в последующей трансформации данных ключевое место занимают визуально обнаруживаемые тренды, наглядная фильтрация наблюдений, создание новых переменных и вычисление сводных данных.
3) Наконец, в исследовательском анализе данных, приходится сочетать визуализацию и преобразования с вашим любопытством и скептицизмом, чтобы задать и ответить на интересующие вопросы о данных.