Последующие этапы позволяют выбрать опциональное создание ярлыков программы, по умолчанию располагаемых в меню «Пуск», и наблюдать за процессом завлечения и копирования файлов RStudio в папку назначения. Так как RStudio написана на языке программирования C++ и использует фреймворк Qt для графического интерфейса пользователя, то в операционную систему будут установлены все необходимые для запуска дополнительные библиотеки сторонних разработчиков. Наиболее крупной из которых, в частности, является Qt5WebEngineCore.dll. По окончанию процесса копирования работа мастера установки будет завершена.
Если пользоваться R без RStudio, то запускаем консоль в Пуск/R/R x64, после разрядности записывается номер установленной версии программного комплекса. Интерфейс будет чуть проще чем RStudio, но для решения элементарных задач достаточным:
Третьим шагом установите надстройку для многофакторного анализа (http://factominer.free.fr), для этого в консоли R просто вводится команда
install.packages("FactoMineR")
install.packages("Factoshiny")
после чего выбирается зеркало для загрузки надстройки.
Для включения пакета следует выбрать пункт меню «Пакеты/Включить пакет…/FactoMineR/ОК», либо установить в пункте меню «Пакеты/установить пакеты…/Factoshiny/ОК». После установки консоль готова для работы.
Кратко опишем, в каких целях используется пакет Factoshiny. Не секрет, что качественная графическая иллюстрация зачастую говорит больше, чем длинная речь оратора, поэтому крайне важно улучшать графики, полученные любыми основными компонентами методами (например: Метод главных компонент «PCA», Анализ соответствий «CA», Анализ повторяющихся соответствий «MCA», Многофакторный анализ «MFA», и многие другие). Factoshiny позволяет легко улучшить графики в интерактивном режиме. Этот удобный интерфейс позволяет параметризовать используемые методы и изменять графические параметры. При этом не нужно знать, как программировать.
Внося изменения в интерактивном режиме через интуитивно понятный интерфейс, становится очевидным, как улучшаются соответствующие графики. Результаты настроек графиков и параметров обновляются автоматически. В дальнейшем можно скачать получившиеся графики, а также строки настроенного кода, чтобы повторить анализ. Кроме того, можно сохранить, а затем повторно использовать объект, полученный из Factoshiny, для дальнейшей модификации графиков. При каждом новом запуске интерфейс открывается с теми настройками, которые были выбраны при последнем выходе из программы, следовательно, быстро можно продолжить изменение параметров выбранного метода факторного анализа или визуализации графиков.
Подготовив рабочее окружение, можно в качестве демонстрации из Google-документов выгрузить Excel-таблицу table.xlsx успеваемости своего онлайн-класса (с оценками для 5-7 учеников по 7-10 темам) и выполнить анализ данных созданной электронной таблицы средствами R. Для этого достаточно ввести следующую серию команд в консоли R (начинающиеся с символа # строки пропускаются, так как воспринимаются системой в качестве комментариев, подробнее необходимость комментирования исходных кодов будет обоснована в следующих разделах):
1) подключаем библиотеку импорта данных из .xls
library(readxl)
2) подключаем библиотеку многофакторного анализа
library(Factoshiny)
3) загружаем в переменную My_table содержимое файла table.xlsx
My_table <– read_excel("C:/путь к файлу/table.xlsx")
4) запускаем графический интерфейс для визуальной настройки и получения статотчетов PCA, в примере 1, 2, 3, 4, 5, 6, 7, 8 – номера импортируемых колонок из электронной таблицы My_table
PCAshiny(My_table[,c(1, 2, 3, 4, 5, 6, 7, 8)])
5) делаем выводы на предмет ведущих факторов, тем, вызвавших наибольшие/наименьшие затруднения учащихся и их взаимовлияния, тенденции развития.
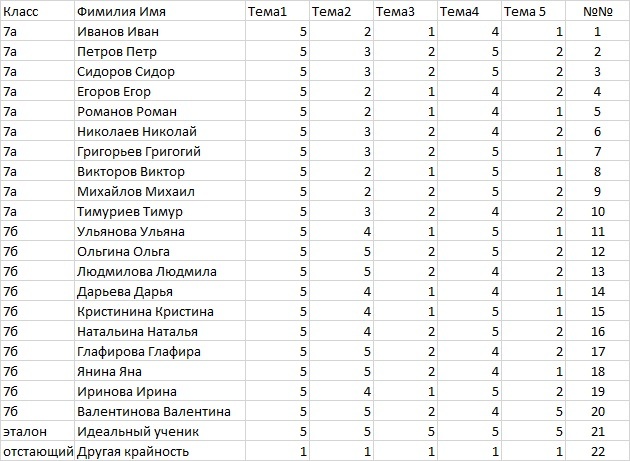
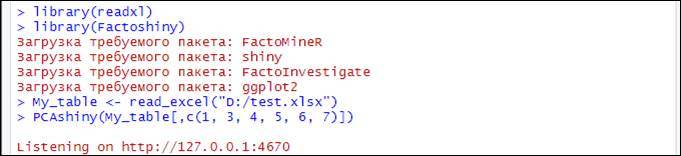
Предположим, что электронный журнал, экспортированный в файл D:\test.xlsx содержит следующие данные об успеваемости обучающихся в 7а и 7б классах:
Запустим RStudio с предустановленными пакетами многофакторного анализа и в консоли R введём серию команд:
library(readxl)
library(Factoshiny)
My_table <– read_excel("D:/test.xlsx")
PCAshiny(My_table[,c(1, 3, 4, 5, 6, 7)])
Система запишет лог выполнения:
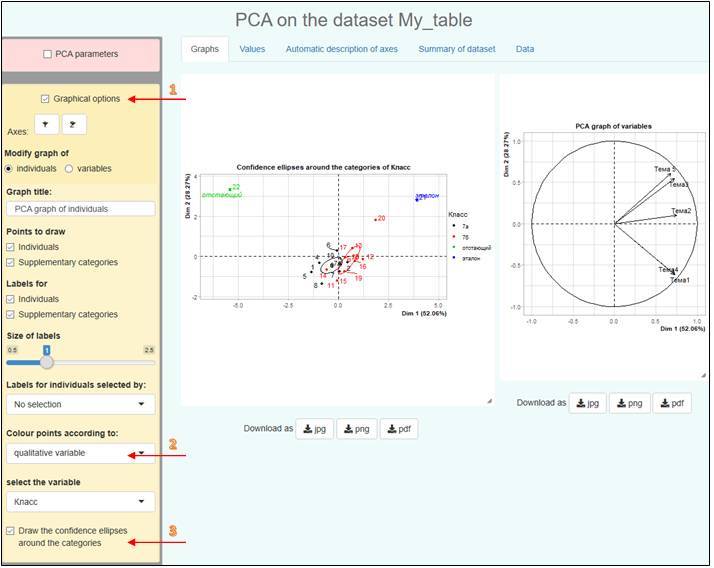
В открывшемся окне браузера настроим некоторые опции. Под номером 1 на рисунке отмечено включение дополнительных параметров построения графика; ПОД номером 2 настраивается способ выделения переменных цветом; под номером 3 включается изображение эллипсов доверительных интервалов значений переменных из разных категорий:
По полученному рисунку становится очевидным следующее:
– так как на круге корреляций вектора Тема1 и Тема4 фактически совпадают, то с этими темами большинство справились одинаково хорошо (если быть более точным, разделение по горизонтальной оси охватывает 52.06%, а по вертикальной – 28.27% тестируемых);
– эталонный ученик оказался в первой четверти, где лежат вектора Тема2, Тема3 и Тема5, значит остальным хуже дались перечисленные Тема2, Тема3 и Тема5;
– ученик №20 лучше всех освоил пройденный материал, так как ближе к эталонному отличнику, а с учениками 1, 4, 6, 8 следует позаниматься дополнительно;
– Тема2 в 7б была освоена лучше, чем в 7а, так как красный и черный эллипсы оказались разнесены вдоль направления вектора Тема2;
– так как центры обоих эллипсов лежат в нижней полуплоскости, снесены от начала координат по направлению векторов Тема1 и Тема4, следовательно статистическому большинству Тема3 и Тема5 далась хуже, чем Тема1 и Тема4, поэтому Темы 3 и 5 необходимо изучить детальнее.
Сказанное выше соотносится с исходными табличными данными, но на большом количестве факторов и аналитических данных графическое представление для обнаружения закономерностей оказывается гораздо удобнее.
Глава 1. Первое знакомство
Внимательный читатель наверняка понял из введения, что эта книга поможет в сфере анализа педагогических данных с помощью R: научит, как импортировать данные в R, систематизировать их наиболее эффективным способом, преобразовать данные, визуализировать и смоделировать возможную динамику. Аналогично тому, как начинающий математик учится ставить мысленные эксперименты, формулировать гипотезы, рассуждать по аналогии, формировать доказательную базу, вы узнаете, как представлять данные, строить графики и многое другое. Эти навыки позволяют состояться онлайн-учителю как исследователю, и в этой книге собраны проверенные оптимальные способы работы с R, освоив которые будет легко использовать язык графиков, чтобы экономить время. Кроме того, станет ясным, как достичь понимания в процессе визуализации и исследования данных. Наука о данных – это захватывающая дисциплина, которая позволяет превратить необработанные исходные разрозненные данные в систематизированные, породив понимание и новое знание. Таким образом, основная цель этой книги – помочь читателю изучить наиболее важные инструменты в R, позволяющие заниматься наукой о педагогических данных. После прочтения этой книги у вас появятся инструменты для решения широкого круга задач средствами R.