— Саймон Роджерс, The Guardian
Полнотекстовая визуализация документов о войне в Ираке, Associated Press
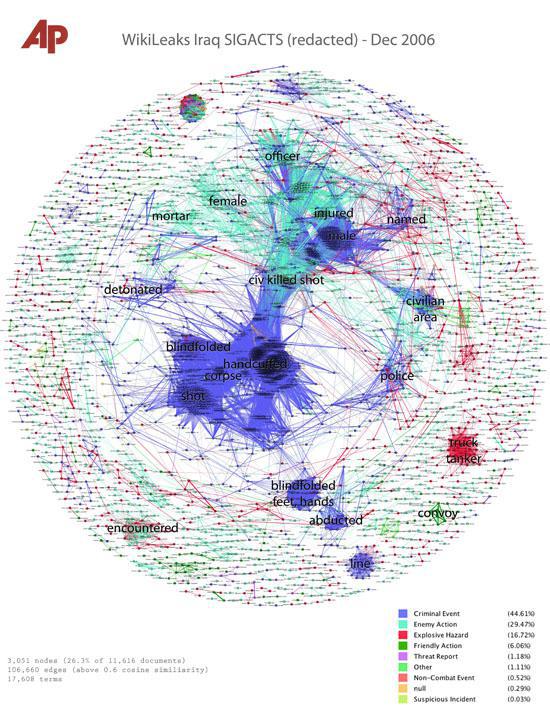
Рис 7. Анализ военных отчетов (Associated Press)
Работа Джонатана Стрэя (Jonathan Stray) и Джулиан Берджесс (Julian Burgess) на основе документов о войне в Ираке (Iraq War Logs) ) является воодушевляющим примером проникновения в текстовый анализ и визуализацию с использованием экспериментальной техники, чтобы разобраться в темах, заслуживающих пристального внимания, за счет большого набора текстовых данных (Рис 7).
Средствами техники текстового анализа и алгоритмов Джонатан и Джулия создали метод, который позволяет демонстрировать кластеры ключевых слов, содержащихся в тысячах отчетов американских властей по Иракской войне, которые подверглись утечке благодаря WikiLeaks, в визуальной форме.
Хотя у представленных методов есть ограничения, и подход носит экспериментальный характер, он представляет собой инновационный подход. Вместо того, чтобы пытаться прочитать все файлы или просматривать записи о войне с предвзятым мнением о том, что там можно найти, вводя определенные ключевые слова и анализируя полученный на выходе результат, эта техника подсчитывает и визуализирует темы/ключевые слова, имеющие особое значение.
В условиях увеличивающихся объемов данных – как текстовых (сообщения электронной почты, отчеты), так и цифровых, оказывающихся в распоряжении общественности, поиск путей для выделения ключевых областей интересов будет становиться все более и более важным – это великолепная подобласть журналистики данных.
— Синтия О'Мурчу, Financial Times
Тайны убийств
Рис 8. Тайны убийств (Scripps Howard News Service)
Одним из моих любимых примеров журналистики данных является проект «Тайны убийств» Тома Харгроува (Tom Hargrove) из Scripps Howard News Service (Рис 8). На основе правительственных данных и запросов на получение данных из открытых источников он составил демографически детализованную базу данных из более чем 185 тысяч нераскрытых убийств, а потом сконструировал алгоритм для поиска по ней образцов, позволяющих объединять те или иные дела на основании предположений о наличии серийных убийц. В этом проекте есть все: упорный труд по сбору данных и составлению базы лучше, чем правительственная, мудрый анализ с использованием техники социальной науки, и интерактивное представление данных в режиме онлайн таким образом, чтобы читатели могли сами в этой базе работать.
— Стив Дойг, Школа журналистики Уолтера Кронкайта, Университет штата Аризона
Машина текстовых сообщений (Message Machine)
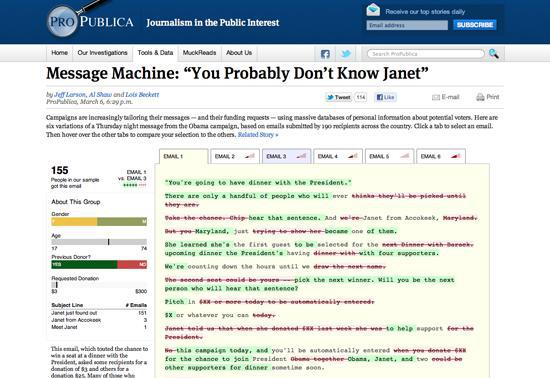
Рис 9. Message Machine (ProPublica)
Мне нравится проект ProPublica под названием «Машина текстовых сообщений» (Message Machine) и пост в блоге (Рис 9). Все это началось тогда, когда несколько пользователей твиттера выразили любопытство по поводу получения разных сообщений электронной почты во время проведения избирательной кампании Обамы. Ребята в ProPublica заметили это и попросили читателей форвардить им любые e–mail–ы, которые они получают от деятелей избирательной кампании. Представление этих данных весьма элегантно, а визуализация выгодно отличается от обычных сообщений электронной почты, которые обычно отправляешь вечерами. Этот проект классный, потому что они собрали свою собственную информацию (хотя, признаем, и небольшую по объему, но достаточную для того, чтобы рассказать историю). Но что еще более здорово, так это то, что они рассказывают историю развивающегося явления, повествуют о масштабных данных, используемых в политических кампаниях с целью целевой рассылки сообщений конкретным лицам. Это лишь первое знакомство, позволяющее попробовать на вкус то, что грядет.
— Брайан, Chicago Tribune
Проект Chartball
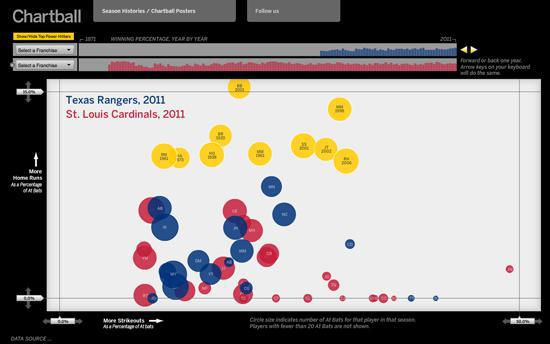
Рис 10. Список побед и поражений (Проект Chartball)
Одним из моих любимых примеров проектов из области журналистики данных является проект Эндрю Гарсиа Филипса (Andrew Garcia Phillips) под названием Chartball (Рис 10). Эндрю – великий фанат спорта, испытывающий при этом ненасытный аппетит к данным, умеющий создавать отличный дизайн и писать программные коды. В «Чартболле» он визуализирует не только размах истории, но и выдает детальную информацию об успехах и неудачах конкретных игроков и команд. Он создает контекст, делает приятную, пробуждающую интерес графику, его работа представляет собой глубокое исследование, она приятна и интересна – и при этом я не особо интересуюсь спортом!
— Сара Слобин, Wall Street Journal
Журналистика данных в перспективе
В августе 2010 года некоторые коллеги и я организовали то, что, как мы считаем, было первыми международными конференциями по журналистике данных, which took place in Amsterdam. At this time there wasn’t a great deal of discussion around this topic and there were only a couple of organizations that were widely known for their work in this area.
1. Они проходили в Амстердаме. В то время на эту тему не велось особых дискуссий, и была лишь пара организаций, которые были широко известны своими работами в данной области.
Способ, которым медийные организации, такие как Guardian и New York Times, обрабатывали огромные объемы данных, опубликованных WikiLeaks, стал одним из основных шагов, которые придали данному термину известность. Примерно в это время термин начал более широко использоваться, вместе с «компьютерной журналистикой», для того, чтобы описать, как журналисты используют данные для улучшения качества освещения событий и увеличения числа глубоких исследований на заданную тему.
Общаясь с опытными журналистами данных и учеными в области журналистики в Twitter , приходишь к выводу, что одна из самых ранних формулировок того, что мы ныне признаем журналистикой данных, была дана в 2006 году Эдрианом Головатым (Adrian Holovaty), основателем проекта EveryBlock – информационной службы, которая позволяет пользователям искать и находить то, что произошло в их районе, в их квартале. В своем коротком эссе под названием «Фундаментальный путь, которым должны измениться газетные сайты» («A fundamental way newspaper sites need to change»)он заявляет, что журналисты должны публиковать структурированные, машиночитаемые данные, вместе с традиционными «большими массами текста»:
Например, предположим, в газете опубликована печатная заметка о местном пожаре. Если есть возможность прочитать эту статью на сотовом телефоне – это здорово и прекрасно, просто щегольски. Ура, технологии! Но что я действительно хочу, чтобы было возможно сделать, так это изучить исходные данные этой истории, один за другим, со всеми слоями атрибуции и ссылок на источники, с инфраструктурой для сравнения данных пожара – даты, времени, места, жертв, номера пожарной части, расстояния от пожарной части, имен и уровня опыта пожарных на месте события, времени, которое потребовалось пожарным для того, чтобы прибыть на место происшествия – с подробными данными о предыдущих пожарах. И последующих пожаров, когда/если они произойдут.